sched-ext Tutorial
Extensible Scheduler Class (besser bekannt als sched-ext) ist ein Linux-Kernel-Feature, das es ermöglicht, Kernel-Thread-Scheduler in
BPF (Berkeley Packet Filter) zu implementieren und dynamisch zu laden. Im Wesentlichen erlaubt dies Endbenutzern, ihre Scheduler im Userspace zu ändern, ohne
einen neuen Kernel kompilieren zu müssen, nur um einen anderen Scheduler zu haben.
-
Die Scheduler findest du in den Paketen
scx-schedsundscx-scheds-git.Terminal-Fenster # Stabiler Branch + scx_loader und scxctl-Tools.sudo pacman -S scx-scheds scx-tools# Bleeding-Edge-Branch (Dieser Branch enthält die neuesten Änderungen aus dem Master-Branch.) + scx_loader und scxctl-Tools.sudo pacman -S scx-scheds-git scx-tools-git
Wie man den Scheduler startet und verwaltet
Abschnitt betitelt „Wie man den Scheduler startet und verwaltet“- Um den Scheduler zu starten, öffne dein Terminal und gib den folgenden Befehl ein:
Beispiel für den Start von rusty sudo scx_rusty
Dadurch wird der Rusty-Scheduler gestartet und der Standard-Scheduler getrennt.
Um den Scheduler zu stoppen, drücke STRG + C. Der Scheduler wird dann gestoppt und der Standard-Kernel-Scheduler übernimmt wieder.
scxctl ist ein CLI-DBUS-Client zur Interaktion mit scx_loader.
- Features:
- Den aktuellen Scheduler und Modus abrufen
- Alle verfügbaren Scheduler auflisten
- Einen Scheduler in einem bestimmten Modus oder mit bestimmten Argumenten starten
- Zwischen Schedulern und Modi wechseln
- Den laufenden Scheduler stoppen
- Den laufenden Scheduler neu starten
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUsage: scxctl <COMMAND>
Commands: get Get the info on the running scheduler list List all supported schedulers start Start a scheduler in a mode or with arguments switch Switch schedulers or modes, optionally with arguments stop Stop the current scheduler restart Restart the current scheduler with original configuration restore Restore the default scheduler from configuration help Print this message or the help of the given subcommand(s)
Options: -h, --help Print help -V, --version Print versionWie der Name schon sagt, ist es ein Dienstprogramm, das als Lader und Manager für das sched-ext-Framework über die D-Bus-Schnittstelle fungiert.
Obwohl es systemd nicht erfordert, kann es dennoch in Verbindung damit verwendet werden. Schau dir die Übergangsanleitung als Referenz an.
- Hat die Fähigkeit, einen scx-Scheduler zu stoppen, zu starten, neu zu starten, Informationen darüber zu lesen und mehr.
- Du kannst Tools wie
dbus-sendodergdbusverwenden, um damit zu kommunizieren.
- Du kannst Tools wie
- Diese Anleitung erklärt, wie man scx_loader mit dem Befehl dbus-send verwendet.
-
scx_rusty mit seinen Standardargumenten starten dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Einen Scheduler mit Argumenten starten # Dieses Beispiel startet scx_bpfland mit den folgenden Flags: -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Den aktuell laufenden Scheduler stoppen dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Zum Standard-Scheduler wechseln # scx_loader wechselt zum Standard-Scheduler, der in der scx_loader-Konfigurationsdatei festgelegt istdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Zu einem anderen Scheduler im Modus 2 wechseln dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# Dies wechselt zu scx_lavd mit dem Scheduler-Modus 2, was bedeutet, dass LAVD im Energiesparmodus gestartet wird -
Zu einem anderen Scheduler mit Argumenten wechseln dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Den aktuell laufenden Scheduler abrufen dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Eine Liste der unterstützten Scheduler abrufen dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Du kannst darauf zugreifen und sie über den Button sched-ext scheduler config konfigurieren.
SCX Manager ist ein eigenständiges GUI-Tool, das vom CachyOS Kernel Manager abgeleitet ist. Es ermöglicht Benutzern, das sched-ext-Framework und seine Scheduler über scx_loader zu verwalten.
Features:
- Überprüfen, welcher Scheduler gerade aktiv ist
- Einen Scheduler oder ein Profil auswählen: (Auto, Gaming, Energiesparen, Niedrige Latenz oder Server)
- Zusätzliche Flags setzen
- Den aktuellen Scheduler deaktivieren
Screenshot

Scheduler-Anleitung: Profile und Anwendungsfälle
Abschnitt betitelt „Scheduler-Anleitung: Profile und Anwendungsfälle“Da es viele Scheduler zur Auswahl gibt, wollen wir eine kleine Einführung zu den verfügbaren Schedulern geben.
Melde gerne jedes Problem oder Feedback in ihrem Scheduler-Repository.
Verwende scx_schedulername --help, um die verfügbaren Flags und eine kurze Beschreibung ihrer Funktion zu sehen.
scx_rusty --helpEntwickelt von: Andrea Righi (arighi GitHub)
Produktionsreif?
Ein vruntime-basierter sched_ext-Scheduler, der interaktive Workloads priorisiert. Sehr flexibel und einfach anzupassen.
Wenn Bpfland Entscheidungen darüber trifft, welche Kerne verwendet werden sollen, berücksichtigt es deren Cache-Layout und welche Kerne denselben L2/L3-Cache teilen, was zu weniger Cache-Misses = mehr Leistung führt.
- Anwendungsfälle:
- Gaming
- Desktop-Nutzung
- Multimedia-/Audioproduktion
- Hervorragende Interaktivität unter intensiven Workloads
- Energiesparen
- Server
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“Niedrige Latenz
Abschnitt betitelt „Niedrige Latenz“- Kommandozeilen-Flags:
-m performance -w - Beschreibung: Soll die Latenz auf Kosten des Durchsatzes verringern. Geeignet für Soft-Echtzeitanwendungen wie Audioverarbeitung und Multimedia.
Energiesparen
Abschnitt betitelt „Energiesparen“- Kommandozeilen-Flags:
-s 20000 -m powersave -I 100 -t 100 - Beschreibung: Priorisiert die Energieeffizienz. Bevorzugt weniger leistungsstarke Kerne (z. B. E-Kerne bei Intel).
- Kommandozeilen-Flags:
-s 20000 -S - Beschreibung: Priorisiert Aufgaben mit strikter Affinität. Diese Option kann den Durchsatz auf Kosten der Latenz erhöhen und ist besser für Server-Workloads geeignet.
Entwickelt von: Andrea Righi (arighi GitHub)
Produktionsreif?
scx_beerland ist ein Scheduler, der darauf ausgelegt ist, Lokalität und Skalierbarkeit zu priorisieren.
Priorisiert das Halten von Aufgaben auf derselben CPU, um die Cache-Lokalität zu wahren, und stellt gleichzeitig eine gute Skalierbarkeit über viele CPUs sicher, indem lokale DSQs (per-CPU-Runqueues) verwendet werden, wenn das System nicht ausgelastet ist.
- Anwendungsfälle:
- Cache-intensive Workloads
- Systeme mit einer großen Anzahl von CPUs
- Gaming: Es ist bekannt, dass es in bestimmten Spielen überraschend gut funktioniert, obwohl deine Ergebnisse variieren können
- Server: Gut für allgemeine Server-Workloads aufgrund seiner Skalierbarkeits- und Lokalitätsoptimierungen.
- Kann auch für die Desktop-Nutzung verwendet werden.
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“Momentan keine.
Entwickelt von: Andrea Righi (arighi GitHub)
Produktionsreif?
Für leistungskritische Produktionsszenarien werden andere Scheduler wahrscheinlich eine bessere Leistung zeigen, da das Auslagern aller Scheduling-Entscheidungen in den User-Space mit einem gewissen Preis verbunden ist (auch wenn dieser minimal ist).
Ein vollständig im User-Space implementierter Scheduler birgt jedoch das Potenzial für eine nahtlose Integration mit anspruchsvollen Bibliotheken, Tracing-Tools, externen Diensten (z. B. KI) usw.
Daher kann es Situationen geben, in denen die Vorteile den Overhead überwiegen und die Verwendung dieses Schedulers in einer Produktionsumgebung rechtfertigen.
Teilt Ähnlichkeiten mit bpfland, wurde mit der Absicht erstellt, leicht lesbar und verständlich zu sein, wie er aufgrund seiner Implementierung im Userspace funktioniert.
Denk daran, dass es einen leichten Durchsatznachteil gibt, wenn ein Userspace-Scheduler verwendet wird.
- Anwendungsfälle:
- Workloads mit geringer Latenz (Gaming, Videokonferenzen und Live-Streaming)
- Desktop-Nutzung
Entwickelt von: Andrea Righi (arighi GitHub)
Produktionsreif?
Ein Scheduler, der sich darauf konzentriert, Fairness zwischen Aufgaben und Leistungsvorhersehbarkeit zu gewährleisten.
Er arbeitet nach einer Earliest Deadline First (EDF) Richtlinie, bei der jeder Aufgabe ein “Latenz”-Gewicht zugewiesen wird. Dieses Gewicht wird dynamisch angepasst, je nachdem, wie oft eine Aufgabe die CPU freigibt, bevor ihre volle Zeitscheibe aufgebraucht ist.
Aufgaben, die die CPU frühzeitig freigeben, erhalten ein höheres Latenzgewicht und werden gegenüber Aufgaben priorisiert, die ihre Zeitscheibe vollständig verbrauchen.
- Anwendungsfälle:
- Gaming
- Latenzempfindliche Workloads wie Multimedia- oder Echtzeit-Audioverarbeitung
- Bedarf an Reaktionsfähigkeit in überlasteten Situationen
- Konsistenz in der Leistung
- Server
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“Niedrige Latenz
Abschnitt betitelt „Niedrige Latenz“- Kommandozeilen-Flags:
-m performance -w -C 0 - Beschreibung: Soll die Latenz auf Kosten des Durchsatzes verringern. Geeignet für Soft-Echtzeitanwendungen wie Audioverarbeitung und Multimedia.
- Kommandozeilen-Flags:
-m all - Beschreibung: Optimiert für hohe Leistung in Spielen.
Energiesparen
Abschnitt betitelt „Energiesparen“- Kommandozeilen-Flags:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Beschreibung: Priorisiert die Energieeffizienz. Bevorzugt weniger leistungsstarke Kerne (z. B. E-Kerne bei Intel) und führt alle 10 ms einen erzwungenen Leerlaufzyklus ein, um die Energieeinsparung zu erhöhen.
- Kommandozeilen-Flags:
-m all -s 20000 -S 1000 -I -1 -D -L - Beschreibung: Für Server-Workloads optimiert. Tauscht Reaktionsfähigkeit gegen Durchsatz.
Entwickelt von: Andrea Righi (arighi GitHub)
- Produktionsreif?
Leichter Scheduler, optimiert für die Beibehaltung der Task-zu-CPU-Lokalität.
Wenn das System nicht ausgelastet ist, priorisiert der Scheduler das Halten von Aufgaben auf derselben CPU mithilfe lokaler DSQs. Dies erhält nicht nur die Lokalität, sondern reduziert auch die Sperrkonflikte im Vergleich zu gemeinsamen DSQs, was eine gute Skalierbarkeit über viele CPUs ermöglicht.
- Anwendungsfälle:
- Allzweck-Scheduler: Der Scheduler sollte sich sowohl für Server-Workloads als auch für Desktop-Workloads anpassen.
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“- Kommandozeilen-Flags:
-d - Beschreibung: Deaktiviert verzögerte Wakeups. Reduziert den Durchsatz und die Leistung für bestimmte Workloads und verringert gleichzeitig den Stromverbrauch.
- Kommandozeilen-Flags:
-c 0 -p 0 - Beschreibung: Deaktiviert die CPU-Lastverfolgung und erzwingt immer ein Deadline-basiertes Scheduling, um die Reaktionsfähigkeit zu verbessern.
Energiesparen
Abschnitt betitelt „Energiesparen“- Kommandozeilen-Flags:
-m powersave -d -p 5000 - Beschreibung: Priorisiert die Energieeffizienz. Bevorzugt weniger leistungsstarke Kerne (z. B. E-Kerne bei Intel) und deaktiviert verzögerte Wakeups, was den Durchsatz reduziert und die Energieeffizienz erhöht. Die CPU-Lastabfrage wird auf 5 ms erhöht.
Niedrige Latenz
Abschnitt betitelt „Niedrige Latenz“- Kommandozeilen-Flags:
-m performance -c 0 -p 0 -w - Beschreibung: Soll die Latenz auf Kosten des Durchsatzes verringern. Geeignet für Soft-Echtzeitanwendungen wie Audioverarbeitung und Multimedia. Erzwingt immer Deadline-basiertes Scheduling und synchrone Wake-up-Optimierungen, um die Leistungsvorhersehbarkeit zu verbessern.
- Kommandozeilen-Flags:
-s 20000 - Beschreibung: Aktiviert die Adressraumaffinität, um die Lokalität und Leistung bei bestimmten cache-sensitiven Workloads zu verbessern. Die Abfrage wird auf 20 ms erhöht.
Entwickelt von: Changwoo Min (multics69 GitHub).
- Produktionsreif?
Kurze Einführung in LAVD von Changwoo:
LAVD ist ein neuer Scheduling-Algorithmus, der sich noch in der Entwicklung befindet. Er ist motiviert durch Gaming-Workloads, die latenzkritisch und kommunikationsintensiv sind. Er zielt darauf ab, Latenzspitzen zu minimieren, während ein insgesamt guter Durchsatz und eine faire Nutzung der CPU-Zeit unter den Aufgaben beibehalten werden.
- Anwendungsfälle:
- Gaming
- Audioproduktion
- Latenzempfindliche Workloads
- Desktop-Nutzung
- Hervorragende Interaktivität unter intensiven Workloads
- Energiesparen
Eine der wichtigsten und genialsten Fähigkeiten, die LAVD beinhaltet, ist die Core Compaction. die ohne auf technische Details einzugehen: Wenn die CPU-Auslastung < 50% ist, laufen die derzeit aktiven Kerne länger und mit einer höheren Frequenz. In der Zwischenzeit bleiben die inaktiven Kerne für eine viel längere Dauer im C-State (Ruhezustand), was zu einem geringeren Gesamtstromverbrauch führt.
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“Gaming & Niedrige Latenz
Abschnitt betitelt „Gaming & Niedrige Latenz“- Kommandozeilen-Flags:
--performance - Beschreibung: Maximiert die Leistung durch die Nutzung aller verfügbaren Kerne und priorisiert physische Kerne.
Energiesparen
Abschnitt betitelt „Energiesparen“- Kommandozeilen-Flags:
--powersave - Beschreibung: Minimiert den Stromverbrauch bei angemessener Leistung. Priorisiert effiziente Kerne und Threads gegenüber physischen Kernen.
Entwickelt von: David Vernet (Byte-Lab GitHub)
- Produktionsreif?
- Ja. Wenn er richtig eingestellt ist.
Rusty bietet eine breite Palette von Funktionen, die seine Fähigkeiten erweitern und eine größere Flexibilität für verschiedene Anwendungsfälle bieten. Eine dieser Funktionen ist die Einstellbarkeit, die es dir ermöglicht, Rusty an deine Vorlieben und spezifischen Anforderungen anzupassen.
- Anwendungsfälle:
- Gaming
- Latenzempfindliche Workloads
- Desktop-Nutzung
- Multimedia-/Audioproduktion
- Hervorragende Interaktivität unter intensiven Workloads
- Energiesparen
- Produktionsreif?
- Ja. Wenn er für deinen spezifischen Workload und deine Hardware richtig eingestellt ist.
Entwickelt von: Daniel Hodges (hodgesds GitHub)
Ein Allzweck-Scheduler, der sich auf “Pick Two”-Lastausgleich zwischen LLCs konzentriert. Erhält eine hohe Cache-Lokalität und Work Conservation bei angemessener Latenz.
- Anwendungsfälle:
- Server
- Desktop-Umgebungen
- Gaming (mit etwas manuellem Tuning)
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“- Kommandozeilen-Flags:
--task-slice true -f --sched-mode performance - Beschreibung: Sorgt für eine gleichmäßigere Leistung beim Zocken und bevorzugt die leistungsstärkeren Kerne für die Aufgabenplanung.
Low Latency (Geringe Latenz)
Abschnitt betitelt „Low Latency (Geringe Latenz)“- Kommandozeilen-Flags:
-y -f --task-slice true - Beschreibung: Verringert die Latenz, indem interaktive Aufgaben stärker an die CPU gebunden werden, der sie zugewiesen wurden, und erhöht die Stabilität der “Slice Time”.
Power Save (Energiesparmodus)
Abschnitt betitelt „Power Save (Energiesparmodus)“- Kommandozeilen-Flags:
--sched-mode efficiency - Beschreibung: Verbessert die Energieeffizienz, indem energieeffiziente Kerne bevorzugt werden.
- Kommandozeilen-Flags:
--keep-running - Beschreibung: Verbessert Server-Workloads, indem Aufgaben auch über ihre zugewiesene Zeit hinaus laufen dürfen, wenn die CPU im Leerlauf ist.
Entwickelt von: Andrea Righi (arighi Github)
- Für den Produktionseinsatz bereit?
- Dieser Scheduler ist noch experimentell und wird nicht für den produktiven Einsatz empfohlen.
scx_tickless ist ein serverorientierter Scheduler, der für Cloud Computing, Virtualisierung und High-Performance-Computing-Workloads entwickelt wurde.
Der Scheduler leitet alle Planungsereignisse durch einen Pool von primären CPUs, die für diese Aufgaben zuständig sind. Das ermöglicht es, den “Tick” des Schedulers auf anderen CPUs zu deaktivieren, was das “OS-Rauschen” reduziert.
- Anwendungsfälle:
- Cloud Computing
- Virtualisierung
- High-Performance-Computing-Workloads
- Server
Scheduler-Modi
Abschnitt betitelt „Scheduler-Modi“- Kommandozeilen-Flags:
-f 5000 -s 5000 - Beschreibung: Verbessert die Gaming-Leistung, indem der Scheduler häufiger CPU-Konflikte erkennt und Kontextwechsel mit einer kürzeren “Time Slice” auslöst.
Power Save (Energiesparmodus)
Abschnitt betitelt „Power Save (Energiesparmodus)“- Kommandozeilen-Flags:
-f 50 - Beschreibung: Verbessert die Energieeffizienz, indem die Überprüfung auf Konflikte seltener stattfindet.
Low Latency (Geringe Latenz)
Abschnitt betitelt „Low Latency (Geringe Latenz)“- Kommandozeilen-Flags:
-f 5000 -s 1000 - Beschreibung: Ähnlich wie das Gaming-Profil, aber mit einer noch kürzeren “Slice”.
- Kommandozeilen-Flags:
-f 100 - Beschreibung: Reduziert, wie oft der Scheduler nach CPU-Konflikten sucht, um den Durchsatz auf Kosten der Reaktionsfähigkeit zu verbessern.
Konfiguration und Leistungstests
Abschnitt betitelt „Konfiguration und Leistungstests“LAVD Autopilot & Autopower
Abschnitt betitelt „LAVD Autopilot & Autopower“Zitate von Changwoo Min:
-
Im Autopilot-Modus passt der Scheduler seinen Energiemodus (
Powersave, Balanced oder Performance) an die Systemlast an, insbesondere an die CPU-Auslastung. -
Autopower: Entscheidet automatisch über den Energiemodus des Schedulers basierend auf dem Energieprofil des Systems, auch bekannt als EPP (Energy Performance Preference).
# Autopower kann mit dem folgenden Flag aktiviert werden:--autopower# z.B.:scx_lavd --autopowerananicy-cpp & sched-ext
Abschnitt betitelt „ananicy-cpp & sched-ext“Um ananicy-cpp zu deaktivieren/stoppen, führe den folgenden Befehl aus:
systemctl disable --now ananicy-cppUmschalten der Energieprofile mit scx_loader
Abschnitt betitelt „Umschalten der Energieprofile mit scx_loader“Das Ganze ist im Paket power-profiles-daemon von CachyOS drin, das einen eigenen Patch mitbringt, um das Umschalten der scx_loader-Energieprofile zu ermöglichen.
- Wenn
scx_loadergerade läuft und du game-performance nutzt, wird der aktive Scheduler automatisch auf das „Gaming“-Profil umgeschaltet, sobald du ein Spiel startest. Wenn du das Spiel wieder schließt, geht’s zurück zum Standardprofil. - Wenn du zwischen den Energieprofilen wechselst, zum Beispiel in KDE Plasma oder GNOME über den Umschalter für Energieprofile, schaltet
scx_loaderautomatisch zum passenden Scheduler-Profil um:
| Power Profile | Scheduler Profile |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Benchmarking und Vergleich von Schedulern mit dem cachyos-benchmarker
Abschnitt betitelt „Benchmarking und Vergleich von Schedulern mit dem cachyos-benchmarker“Das Tool cachyos-benchmarker bietet eine einfache Möglichkeit, die Leistung verschiedener CPU-Scheduler zu bewerten und zu vergleichen.
Es führt eine umfassende Suite von Benchmarks durch, um die CPU-, Speicher- und Gesamtsystemleistung unter verschiedenen Arbeitslasten zu messen.
Die folgenden Benchmarks sind enthalten:
| Test | Misst | Tool |
|---|---|---|
| stress-ng cpu-cache-mem | CPU-, Cache- und Speicherleistung | stress-ng |
| FFmpeg-Kompilierung | Parallele Build-Leistung | make |
| x265-Kodierung | Videokodierungs-Durchsatz | x265 |
| argon2-Hashing | Multithreaded-Passwort-Hashing | argon2 |
| perf sched msg | Kontextwechsel- und IPC-Leistung | perf |
| perf memcpy | Speicherdurchsatz memcpy() | perf |
| Primzahlberechnung | Ganzzahl-Arithmetik und Parallelität | primesieve |
| NAMD | Molekulardynamik (wissenschaftliche Arbeitslast) | namd3 |
| Blender-Render | reines CPU-3D-Rendering | blender |
| xz-Kompression | Kompressionsdurchsatz | xz |
| Kernel-defconfig-Build | Kernel-Kompilierungsleistung | make |
| y-cruncher | Mathematische Präzision und Speicherbelastung | y-cruncher |
cachyos-benchmarker kann für verschiedene Zwecke verwendet werden, darunter:
- Testen der Scheduler-Stabilität
Führe die gesamte Benchmark-Suite aus, um Hänger, Abstürze oder Regressionen zu erkennen, die durch Scheduler-Änderungen eingeführt wurden.
Wenn du
scx_loaderverwendest, kannst du im Falle eines Hängers oder Absturzes Protokolle mit folgendem Befehl sammeln:Dadurch wird eine Datei namensTerminal-Fenster journalctl --unit scx_loader.service --boot 0 > crash.logcrash.login deinem aktuellen Verzeichnis erstellt. - Vergleich der Scheduler-Leistung
- Bewerte Leistungsunterschiede zwischen Schedulern. z.B.
BPFLAND vs. LAVD
- Bewerte Leistungsunterschiede zwischen Schedulern. z.B.
- Messen des Effekts von Kernel- oder Scheduler-Updates
- Vergleiche Durchläufe vor und nach dem Anwenden von Patches oder Versionsänderungen, um Leistungsregressionen oder -verbesserungen zu prüfen.
- Testen von Konfigurationsanpassungen
- Bewerte die Auswirkungen von Änderungen wie CPU-Governor-Einstellungen, SMT-Umschaltung oder modifizierten Scheduler-Flags.
Anforderungen
Abschnitt betitelt „Anforderungen“- 4 GB RAM oder mehr
- Mindestens 8 GB freier Speicherplatz
- Zeit und Geduld – der vollständige Benchmark kann auf langsameren Systemen über eine Stunde dauern
Installation
Abschnitt betitelt „Installation“Um cachyos-benchmarker zu installieren, führe den folgenden Befehl aus:
sudo pacman -S cachyos-benchmarkerAusführen des Benchmarks
Abschnitt betitelt „Ausführen des Benchmarks“- Führe
cachyos-benchmarkeraus:Terminal-Fenster cachyos-benchmarker ~/cachyos-benchmarker/# Du kannst ~/cachyos-benchmarker/ durch ein beliebiges Verzeichnis ersetzen, in dem die Protokolle gespeichert werden sollen. - Warte, bis die Vorbereitungsschritte abgeschlossen sind.
- Folge den Anweisungen:
Do you want to drop page cache now? Root privileges needed! (y/N) y(Möchtest du jetzt den Page-Cache leeren? Root-Rechte erforderlich!)Please enter a name for this run, or leave empty for default:(Bitte gib einen Namen für diesen Durchlauf ein oder lass das Feld für den Standardnamen leer:)
- Warte, bis die Tests abgeschlossen sind.
- Sobald der Vorgang abgeschlossen ist, geschieht Folgendes:
- Erstellung einer Protokolldatei mit einem Namen wie
benchie_<name>_<DATUM>.log, die detaillierte Informationen über den Benchmark-Lauf enthält.- Beispiel:
benchie_p2dq_2025-09-29-2115.log - Das Skript
benchmark_scraper.pywird automatisch ausgeführt, um einen zusammenfassenden Bericht im HTML-Format zu erstellen. - Was macht das Skript?:
- Liest alle
benchie_*.log-Dateien im angegebenen Verzeichnis. - Extrahiert die Benchmark-Namen, -Zeiten und -Werte.
- Sortiert oder fasst sie zusammen.
- Gibt eine saubere Zusammenfassung der Ergebnisse in deinem Terminal aus und erstellt eine HTML-Datei, die in einem Browser geöffnet werden kann.
Beispiel für die Terminal-Ausgabe:
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1HTML-Beispiel eines Testergebnisses, das zwei verschiedene Branches desselben Schedulers vergleicht:
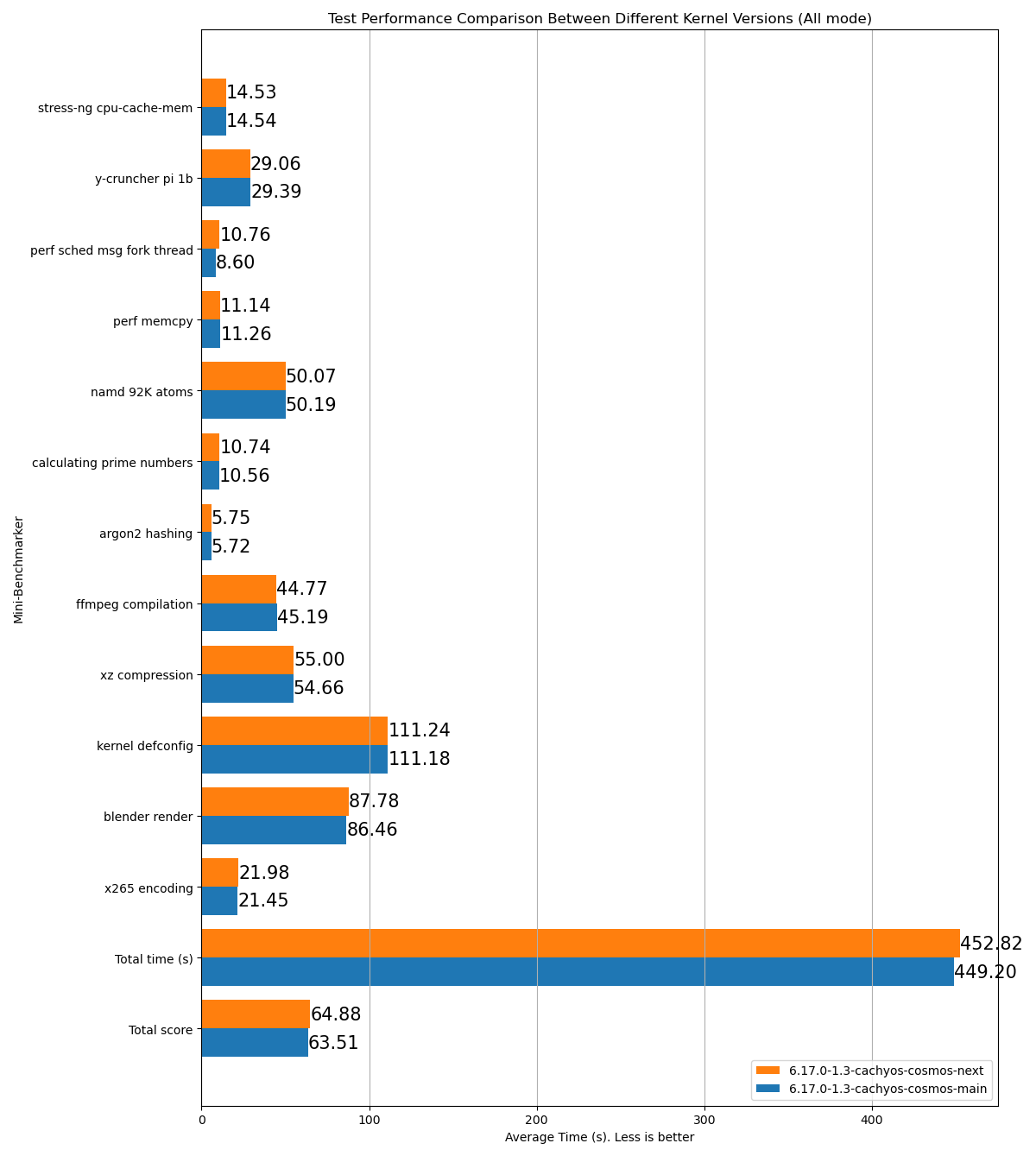
- Liest alle
- Beispiel:
- Erstellung einer Protokolldatei mit einem Namen wie
- Um zwei oder mehr Durchläufe zu vergleichen, lege die
.log-Dateien vor dem Ausführen vonbenchmark_scraper.pyin dasselbe Verzeichnis. Das Tool erkennt und vergleicht sie automatisch im HTML-Bericht.
Testen der Scheduler-Latenz mit schbench
Abschnitt betitelt „Testen der Scheduler-Latenz mit schbench“schbench ist ein Scheduler-Benchmark, der entwickelt wurde, um die Scheduler-Latenz unter einer simulierten serverähnlichen Arbeitslast zu messen. Es erzeugt eine konfigurierbare Anzahl von “Worker”- und “Message”-Threads, bei denen die Message-Threads wiederholt die Worker-Threads aufwecken. Durch die Messung der Latenzverteilung vom Aufwecken bis zur Ausführung dieser Worker-Threads liefert es wichtige Einblicke in die Fähigkeit eines Kernels, mit Thread-Aufweckvorgängen, Lastausgleich und CPU-Konflikten umzugehen, insbesondere unter Last.
Anwendungsfälle
Abschnitt betitelt „Anwendungsfälle“Du kannst schbench verwenden, um:
- Scheduler-Latenz zu bewerten: Finde heraus, wie schnell Threads nach dem Aufwecken eingeplant werden.
- Aufweckleistung zwischen Schedulern zu vergleichen: Entdecke Verbesserungen oder Regressionen bei Kontextwechseln und Aufwecklatenz.
- Die Auswirkung von Kernel- oder Scheduler-Patches zu testen: Bewerte, ob Optimierungen oder Updates die Fairness und Reaktionsfähigkeit des Schedulings beeinflussen.
Installation
Abschnitt betitelt „Installation“schbench ist in den CachyOS-Repositories verfügbar:
sudo pacman -S schbenchAusführen des Benchmarks
Abschnitt betitelt „Ausführen des Benchmarks“Eine einfache Möglichkeit, schbench für einen allgemeinen Latenztest auszuführen, ist:
schbench -m 2 -t 8 -r 60Dieses Beispiel führt aus:
- 2 Message-Threads (
-m 2) - 8 Worker-Threads pro Message-Thread (
-t 8) - für eine Gesamtlaufzeit von 60 Sekunden (
-r 60)
Du kannst diese Werte je nach Anzahl deiner CPU-Kerne und dem gewünschten Lastniveau anpassen.
Hier ist eine Tabelle, die einige der wichtigsten Optionen erklärt:
| Option | Beschreibung |
|---|---|
-C, --calibrate | Kalibrierung durchführen und Zeitmessung berichten (kein Benchmark). |
-L, --no-locking | Spinlocks während der CPU-Arbeit deaktivieren (Standard: Sperren aktiviert). |
-m, --message-threads <n> | Anzahl der Message-Threads (Standard: 1). |
-t, --threads <n> | Worker-Threads pro Message-Thread (Standard: Anzahl der CPUs). |
-r, --runtime <sec> | Benchmark-Dauer (Standard: 30). |
-F, --cache_footprint <KB> | Größe des Cache-Footprints (Standard: 256). |
-n, --operations <count> | Anzahl der auszuführenden “Denkzeit”-Operationen (Standard: 5). |
-A, --auto-rps | RPS automatisch erhöhen, bis das CPU-Auslastungsziel erreicht ist. |
-R, --rps <count> | Modus “Anfragen pro Sekunde”. |
-p, --pipe <bytes> | Simuliert einen Pipe-Übertragungstest. |
-w, --warmuptime <sec> | Aufwärmdauer vor dem Sammeln von Statistiken (Standard: 0). |
-i, --intervaltime <sec> | Intervall zum Drucken von Latenzen (Standard: 10). |
-z, --zerotime <sec> | Intervall zum Zurücksetzen der Latenzstatistiken (Standard: nie). |
Die Ausgabe verstehen
Abschnitt betitelt „Die Ausgabe verstehen“Nach jedem Durchlauf gibt schbench Latenzperzentile aus, wie hier:
Beispiel für die Ausgabe
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Wie man die Ergebnisse interpretiert
Abschnitt betitelt „Wie man die Ergebnisse interpretiert“- Wakeup Latencies (Aufwecklatenzen):
- Misst, wie schnell Threads aufwachen, nachdem sie ein Signal erhalten haben.
- Niedrigere Werte hier (insbesondere das 99. Perzentil) bedeuten, dass der Scheduler reaktionsschneller ist.
- Misst, wie schnell Threads aufwachen, nachdem sie ein Signal erhalten haben.
- Request Latencies (Anforderungslatenzen):
- Stellt die Zeit dar, die benötigt wird, um Anfragen zwischen Threads abzuschließen.
- Eine niedrigere Latenz deutet auf eine bessere Kommunikation zwischen den Threads und eine höhere Scheduling-Effizienz hin.
- Stellt die Zeit dar, die benötigt wird, um Anfragen zwischen Threads abzuschließen.
- RPS (Requests Per Second - Anfragen pro Sekunde):
- Zeigt den aufrechterhaltenen Durchsatz:
- Ein höherer durchschnittlicher RPS-Wert zeigt an, dass der Scheduler unter der gegebenen Konfiguration mehr Arbeit pro Sekunde bewältigen kann.
- Zeigt den aufrechterhaltenen Durchsatz:
Zusammenfassend:
- Ein guter Scheduler zeigt niedrige Aufweck- und Anforderungslatenzen mit konstanten RPS-Werten.
- Ein weniger effizienter Scheduler kann hohe Latenzspitzen oder instabile RPS-Werte im Laufe der Zeit aufweisen.
Empfehlungen für das Benchmarking von Spielen
Abschnitt betitelt „Empfehlungen für das Benchmarking von Spielen“Wenn du Spiele benchmarken möchtest, um die Leistung verschiedener Scheduler zu vergleichen, findest du hier einige Tipps, um die genauesten Ergebnisse zu erhalten:
- Nutze eingebaute Benchmarks: Viele moderne Spiele verfügen über integrierte Benchmark-Tools. Diese sind so konzipiert, dass sie konsistente Ergebnisse liefern, indem sie bei jedem Durchlauf dieselbe Abfolge von Ereignissen ausführen.
- Schau dir diese Website für eine Liste von Spielen an, die eingebaute Benchmarks enthalten.
- Konsistente Einstellungen: Stelle sicher, dass die Spieleinstellungen (Auflösung, Grafikqualität usw.) bei jedem Testlauf identisch sind.
- Schließe Hintergrundanwendungen: Andere im Hintergrund laufende Anwendungen können die Leistung beeinträchtigen. Schließe unnötige Programme, um ihren Einfluss zu minimieren.
- Wenn du keinen eingebauten Benchmark verwendest, versuche, bei jedem Testlauf dieselben Aktionen im Spiel auszuführen. Dies könnte das Verfolgen desselben Pfades, die Teilnahme an ähnlichen Kampfszenarien oder die Durchführung derselben Aufgaben umfassen.
- Schon das Zielen auf eine andere Stelle kann zu unterschiedlichen Leistungsergebnissen führen.
- Mehrere Durchläufe: Führe mehrere Benchmark-Durchläufe durch und bilde den Durchschnitt, um Schwankungen auszugleichen.
- Verwende Leistungsüberwachungstools: Tools wie MangoHud oder GOverlay können Echtzeit-Leistungsmetriken wie FPS, Frame-Zeiten und CPU/GPU-Auslastung liefern.
- Nutze Tastenkombinationen oder Makros:
- Ein Beispiel ist die Erstellung einer Tastenkombination, mit der du im Spiel zwischen verschiedenen Schedulern wechseln oder deren Modi spontan ändern kannst.
- Dies kann mit einem Tool wie scxctl oder durch das Erstellen eigener Skripte erfolgen, die den aktiven Scheduler und seinen Modus ändern.
- Ein Beispiel ist die Erstellung einer Tastenkombination, mit der du im Spiel zwischen verschiedenen Schedulern wechseln oder deren Modi spontan ändern kannst.
Hochladen und Teilen deiner Benchmarks
Abschnitt betitelt „Hochladen und Teilen deiner Benchmarks“Diese Website enthält eine Liste von Benchmarks, die von der Community mit verschiedenen Schedulern oder beim Testen verschiedener Einstellungen durchgeführt wurden.
Um deine eigenen Benchmarks hochzuladen, musst du dein Discord-Konto mit der Website verknüpfen, und dann kannst du deine eigenen Benchmarks einreichen.
Klicke dann auf die Schaltfläche New benchmark und fülle die erforderlichen Informationen aus.
- Du kannst mehrere Ergebnisse für dasselbe Spiel mit verschiedenen Schedulern oder Einstellungen hochladen.
- Akzeptiert sowohl MangoHud- als auch Afterburner-Protokolle.
- Ermöglicht die Suche nach Titel oder Beschreibung.
Umstieg von scx.service auf scx_loader: Eine umfassende Anleitung
Abschnitt betitelt „Umstieg von scx.service auf scx_loader: Eine umfassende Anleitung“Beginnen wir mit einem genauen Vergleich der Dateistruktur von scx.service mit der Konfigurationsdateistruktur von scx_loader.
Wenn du zuvor LAVD mit dem alten scx.service wie im folgenden Beispiel ausgeführt hast:
# Liste der scx_scheduler: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Setze benutzerdefinierte Flags für den SchedulerSCX_FLAGS='--performance'Dann wird das Äquivalent in der Konfigurationsdatei von scx_loader so aussehen:
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Weitere Informationen zur Konfiguration der scx_loader-Datei findest du hier
Folge der nachstehenden Anleitung für einen einfachen Übergang vom scx systemd service zum neuen scx_loader-Dienstprogramm.
-
Deaktivieren von scx.service zugunsten des scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Erstellen der Konfigurationsdatei für den scx_loader und Hinzufügen der Standardstruktur # Der Micro-Editor wird eine neue Datei erstellen.sudo micro /etc/scx_loader.toml# Füge die folgenden Zeilen hinzu:default_sched = "scx_bpfland" # Bearbeite diese Zeile mit dem Scheduler, den scx_loader beim Booten starten solldefault_mode = "Auto" # Mögliche Werte: "Auto", "Gaming", "LowLatency", "PowerSave".# Drücke STRG + S, um die Änderungen zu speichern, und STRG + Q, um Micro zu beenden. -
Neustarten des scx_loader systemctl restart scx_loader.service- Du bist fertig, der scx_loader wird nun den gewünschten Scheduler laden und starten.
Debugging im scx_loader
Abschnitt betitelt „Debugging im scx_loader“-
Dienststatus überprüfen systemctl status scx_loader.service -
Alle Log-Einträge des Dienstes anzeigen journalctl -u scx_loader.service -
Nur die Logs der aktuellen Sitzung anzeigen. journalctl -u scx_loader.service -b 0
Um ein detaillierteres Log zu erhalten, befolge diese Schritte.
-
Die Service-Datei bearbeiten sudo systemctl edit scx_loader.service -
Füge die folgende Zeile unter dem Abschnitt [Service] hinzu Environment=RUST_LOG=trace -
Den Dienst neu starten sudo systemctl restart scx_loader.service - Überprüfe die Logs erneut, um detailliertere Debugging-Informationen zu erhalten.
Warum ist der X-Scheduler schlechter als der andere?
Abschnitt betitelt „Warum ist der X-Scheduler schlechter als der andere?“- Beim Vergleich gibt es viele Variablen zu beachten. Zum Beispiel, wie messen sie die Gewichtung einer Aufgabe? Priorisieren sie interaktive Aufgaben gegenüber nicht-interaktiven? Letztendlich hängt es von ihren Design-Entscheidungen ab.
Warum sagen alle, dass dieser X-Scheduler der beste für den Fall Y ist, er bei mir aber nicht so gut funktioniert?
Abschnitt betitelt „Warum sagen alle, dass dieser X-Scheduler der beste für den Fall Y ist, er bei mir aber nicht so gut funktioniert?“- Ähnlich wie bei der vorherigen Antwort können die Wahl der CPU und ihr Design, wie z. B. das Core-Layout, die gemeinsame Nutzung des Cache über die Kerne hinweg und andere damit zusammenhängende Faktoren, dazu führen, dass der Scheduler weniger effizient arbeitet.
- Deshalb ist die Wahlmöglichkeit einer der Höhepunkte des sched-ext-Frameworks. Scheu dich also nicht, einen auszuprobieren und zu sehen, welcher für deinen Anwendungsfall am besten funktioniert.
Beispiele: FPS-Stabilität, maximale Leistung, Reaktionsfähigkeit bei intensiver Arbeitslast usw.
Die Anwendungsfälle dieser Scheduler sind ziemlich ähnlich… warum ist das so?
Abschnitt betitelt „Die Anwendungsfälle dieser Scheduler sind ziemlich ähnlich… warum ist das so?“Hauptsächlich, weil es sich um Mehrzweck-Scheduler handelt, was bedeutet, dass sie eine Vielzahl von Arbeitslasten bewältigen können, auch wenn sie vielleicht nicht in jedem Bereich überragen.
- Um herauszufinden, welcher Scheduler am besten zu dir passt, gibt es keinen besseren Rat, als ihn selbst auszuprobieren.
Warum fehlt bei mir ein Scheduler, den einige Benutzer auf dem CachyOS-Discord-Server erwähnen oder testen?
Abschnitt betitelt „Warum fehlt bei mir ein Scheduler, den einige Benutzer auf dem CachyOS-Discord-Server erwähnen oder testen?“Stell sicher, dass du die topaktuelle Version des scx-scheds-Pakets mit dem Namen scx-scheds-git verwendest.
- Einer der Gründe könnte sein, dass dieser Scheduler sehr neu ist und gerade von den Benutzern getestet wird und daher noch nicht zum
scx-scheds-git-Paket hinzugefügt wurde.
Warum ist der Scheduler plötzlich abgestürzt? Ist er instabil?
Abschnitt betitelt „Warum ist der Scheduler plötzlich abgestürzt? Ist er instabil?“- Es könnte ein paar Gründe geben, warum das passiert ist:
- Einer der häufigsten Gründe ist, dass du ananicy-cpp neben dem Scheduler verwendet hast. Deshalb haben wir diese Warnung hinzugefügt.
- Ein weiterer Grund könnte sein, dass die Arbeitslast, die du ausgeführt hast, die Grenzen und die Kapazität des Schedulers überschritten hat, was zu einem Stillstand führte.
- Beispiel für eine unangemessene Arbeitslast:
hackbench
- Beispiel für eine unangemessene Arbeitslast:
- Oder der offensichtlichere Grund: Du hast einen Bug im Scheduler gefunden. Wenn ja, melde ihn bitte als Issue in deren GitHub oder lass es sie
im CachyOS-Discord-Kanal
sched-extwissen.
Ich habe den scx_loader zuvor in der Kernel-Manager-GUI verwendet. Muss ich die Übergangsschritte trotzdem befolgen?
Abschnitt betitelt „Ich habe den scx_loader zuvor in der Kernel-Manager-GUI verwendet. Muss ich die Übergangsschritte trotzdem befolgen?“- In diesem speziellen Fall ist es nicht notwendig, da der Kernel Manager den Übergangsprozess bereits übernimmt.
- Es sei denn, du hast zuvor benutzerdefinierte Flags in
/etc/default/scxhinzugefügt und möchtest diese weiterhin verwenden.
- Es sei denn, du hast zuvor benutzerdefinierte Flags in
Mehr erfahren
Abschnitt betitelt „Mehr erfahren“- Sched_ext YT-Playlist
- LWN: The extensible scheduler class (Februar 2023)
- arighis Blog: Implement your own kernel CPU scheduler in Ubuntu with sched_ext (Juli 2023)
- David Vernets Vortrag: Kernel Recipes 2023 - sched_ext: pluggable scheduling in the Linux kernel (September 2023)
- Changwoos Blog: sched_ext: a BPF-extensible scheduler class (Part 1) (Dezember 2023)
- arighis Blog: Getting started with sched_ext development (April 2024)
- Changwoos Blog: sched_ext: scheduler architecture and interfaces (Part 2) (Juni 2024)
- arighis YT-Kanal: scx_bpfland Linux scheduler demo: topology awareness (August 2024)
- David Vernets Vortrag: Kernel Recipes 2024 - Scheduling with superpowers: Using sched_ext to get big perf gains (September 2024)