Руководство по sched-ext
Extensible Scheduler Class (более известный как sched-ext) — это функция ядра Linux, которая позволяет реализовывать планировщики потоков ядра на
BPF (Berkeley Packet Filter) и динамически их загружать. По сути, это позволяет конечным пользователям изменять свои планировщики в пространстве пользователя без
необходимости собирать новое ядро только для того, чтобы получить другой планировщик.
-
Планировщики можно найти в пакетах
scx-schedsиscx-scheds-git.Terminal window # Стабильная ветка + утилиты scx_loader и scxctl.sudo pacman -S scx-scheds scx-tools# Передовая ветка (эта ветка включает последние изменения из ветки master) + утилиты scx_loader и scxctl.sudo pacman -S scx-scheds-git scx-tools-git
Как запускать и управлять планировщиком
Заголовок раздела «Как запускать и управлять планировщиком»- Чтобы запустить планировщик, откройте терминал и введите следующую команду:
Пример запуска rusty sudo scx_rusty
Это запустит планировщик rusty и отключит планировщик по умолчанию.
Чтобы остановить планировщик, нажмите CTRL + C, после чего планировщик будет остановлен, и снова будет использоваться планировщик ядра по умолчанию.
scxctl — это клиент DBUS для командной строки для взаимодействия с scx_loader.
- Возможности:
- Получить информацию о текущем планировщике и режиме
- Показать список всех доступных планировщиков
- Запустить планировщик в заданном режиме или с заданными аргументами
- Переключаться между планировщиками и режимами
- Остановить работающий планировщик
- Перезапустить работающий планировщик
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUsage: scxctl <COMMAND>
Commands: get Get the info on the running scheduler list List all supported schedulers start Start a scheduler in a mode or with arguments switch Switch schedulers or modes, optionally with arguments stop Stop the current scheduler restart Restart the current scheduler with original configuration restore Restore the default scheduler from configuration help Print this message or the help of the given subcommand(s)
Options: -h, --help Print help -V, --version Print versionКак следует из названия, это утилита, которая функционирует как загрузчик и менеджер для фреймворка sched-ext, используя интерфейс D-Bus.
Хотя она не требует systemd, её всё же можно использовать совместно с ним. Обратитесь к руководству по переходу для справки.
- Имеет возможность останавливать, запускать, перезапускать, считывать информацию о планировщике scx и многое другое.
- Вы можете использовать такие инструменты, как
dbus-sendилиgdbus, для взаимодействия с ним.
- Вы можете использовать такие инструменты, как
- Это руководство объясняет, как использовать scx_loader с командой dbus-send.
-
Запуск scx_rusty с аргументами по умолчанию dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Запуск планировщика с аргументами # Этот пример запускает scx_bpfland со следующими флагами: -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Остановка текущего работающего планировщика dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Переключиться на планировщик по умолчанию # scx_loader переключится на планировщик по умолчанию, установленный в файле конфигурации scx_loaderdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Переключение на другой планировщик в Режиме 2 dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# Это переключает на scx_lavd с режимом планировщика 2, что означает запуск LAVD в режиме энергосбережения -
Переключение на другой планировщик с аргументами dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Получение информации о текущем работающем планировщике dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Получение списка поддерживаемых планировщиков dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Вы можете получить к ним доступ и настроить их с помощью кнопки sched-ext scheduler config.
SCX Manager — это отдельный графический инструмент, созданный на основе CachyOS Kernel Manager. Он позволяет пользователям управлять фреймворком sched-ext и его планировщиками через scx_loader.
Возможности:
- Проверить, какой планировщик активен в данный момент
- Выбрать планировщик или профиль: (Авто, Игровой, Энергосбережение, Низкая задержка или Серверный)
- Установить дополнительные флаги
- Отключить текущий планировщик
Снимок экрана

Руководство по планировщикам: Профили и сценарии использования
Заголовок раздела «Руководство по планировщикам: Профили и сценарии использования»Поскольку на выбор предлагается множество планировщиков, мы хотим кратко представить каждый из них.
Не стесняйтесь сообщать о любых проблемах или оставлять отзывы в репозитории соответствующего планировщика.
Используйте scx_имя_планировщика --help, чтобы увидеть доступные флаги и краткое описание их функций.
scx_rusty --helpРазработчик: Andrea Righi (arighi GitHub)
Готов к использованию в production?
scx_beerland — это планировщик, разработанный для приоритезации локальности данных и масштабируемости.
Он стремится удерживать задачи на одном и том же ЦП для сохранения локальности кэша, а также обеспечивает хорошую масштабируемость на множестве ЦП за счет использования локальных DSQ (очередей выполнения для каждого ЦП), когда система не насыщена.
- Сценарии использования:
- Нагрузки, интенсивно использующие кэш
- Системы с большим количеством ЦП
- Игры: известно, что он на удивление хорошо работает в некоторых играх, хотя ваш опыт может отличаться
- Сервер: хорошо подходит для серверных нагрузок общего назначения благодаря оптимизации локальности и масштабируемости.
- Может также использоваться на настольных компьютерах.
Режимы планировщика
Заголовок раздела «Режимы планировщика»На данный момент отсутствуют.
Разработчик: Andrea Righi (arighi GitHub)
Готов к использованию в production?
Планировщик sched_ext на основе vruntime, который отдает приоритет интерактивным рабочим нагрузкам. Очень гибкий и легко адаптируемый.
При принятии решений о том, какие ядра использовать, Bpfland учитывает их структуру кэша и то, какие ядра совместно используют кэш L2/L3, что приводит к меньшему количеству промахов кэша и, следовательно, к большей производительности.
- Сценарии использования:
- Игры
- Использование на настольном компьютере
- Производство мультимедиа/аудио
- Отличная интерактивность при интенсивных нагрузках
- Энергосбережение
- Сервер
Режимы планировщика
Заголовок раздела «Режимы планировщика»Низкая задержка (Low Latency)
Заголовок раздела «Низкая задержка (Low Latency)»- Флаги командной строки:
-m performance -w - Описание: Предназначен для снижения задержки за счет пропускной способности. Подходит для приложений мягкого реального времени, таких как обработка аудио и мультимедиа.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
-s 20000 -m powersave -I 100 -t 100 - Описание: Приоритезирует энергоэффективность. Отдает предпочтение менее производительным ядрам (например, E-ядрам на Intel).
Сервер (Server)
Заголовок раздела «Сервер (Server)»- Флаги командной строки:
-s 20000 -S - Описание: Приоритезирует задачи со строгим сродством (affinity). Эта опция может увеличить пропускную способность за счет задержки и больше подходит для серверных нагрузок.
Разработчик: RitzDaCat (RitzDaCat GitHub)
- Готов к использованию в production?
scx_cake — это экспериментальный BPF планировщик ЦП, адаптирующий алгоритм CAKE для сетевых пакетов с помощью DRR++ (Deficit Round Robin++) для планирования ЦП.
- 4-уровневая классификация — задачи сортируются по среднему времени выполнения EWMA на уровни Critical / Interactive / Frame / Bulk
- Отсутствие глобальных атомиков — массивы BSS для каждого ЦП с записями под защитой MESI устраняют блокировку шины
- Выбор простоя, делегированный ядру — scx_bpf_select_cpu_dfl() для авторитетного выбора ЦП без устаревших данных
- Шардинг DSQ на уровне LLC — устраняет конкуренцию за блокировки между CCD на многочиплетных ЦП
- Отслеживание дефицита DRR++ — алгоритм справедливости потоков сети CAKE, адаптированный для планирования задач ЦП
Разработан для игровых нагрузок на современном оборудовании AMD и Intel.
- Сценарии использования:
- Игры
4-уровневая система
Заголовок раздела «4-уровневая система»scx_cake классифицирует каждую задачу по одному из четырёх уровней на основе её EWMA (экспоненциально взвешенного скользящего среднего) времени выполнения. Классификация выполняется автоматически и непрерывно — задачи перемещаются между уровнями по мере изменения их поведения.
Пороговые значения уровней
Заголовок раздела «Пороговые значения уровней»| Уровень | Название | avg_runtime | Типичная нагрузка | Квант | Голодание |
|---|---|---|---|---|---|
| T0 | Critical | < 100µs | IRQ-обработчики, драйверы ввода, аудио (PipeWire), сеть | 0.5ms | 3ms |
| T1 | Interactive | < 2ms | Композиторы, физика игр, ИИ игр, короткие рабочие потоки | 2.0ms | 8ms |
| T2 | Frame | < 8ms | Потоки рендеринга игр, кодирование видео | 4.0ms | 40ms |
| T3 | Bulk | ≥ 8ms | Компиляция, фоновая индексация, пакетные задачи | 8.0ms | 100ms |
[!TIP] Ни одна игровая задача не должна находиться в T3. Потоки рендеринга игр выполняются 2–8 мс на кадр → T2. Физика/ИИ выполняются 0,5–2 мс → T1. Обработчики ввода выполняются < 100 мкс → T0. В T3 попадают только задачи, выполняющие более 8 мс непрерывной работы ЦП (компиляция шейдеров, экраны загрузки).
Как работает классификация
Заголовок раздела «Как работает классификация»- Начальное размещение: на основе значения
nice—nice < 0→ T0,nice 0-10→ T1,nice > 10→ T3 - Авторитет времени выполнения: после ~3 остановок EWMA avg_runtime становится авторитетным. Задача с nice -5, выполняющаяся по 50 мс, будет реклассифицирована в T3 независимо от значения nice.
- Гистерезис: мёртвая зона 10% предотвращает колебания на границах уровней. Повышение требует, чтобы avg_runtime был явно ниже порогового значения; понижение происходит немедленно.
- Постепенное снижение частоты: как только уровень остаётся стабильным в течение 3+ последовательных остановок, частота реклассификации снижается для каждого уровня: T0 проверяется каждую 1024-ю остановку, T3 — каждую 16-ю. Нестабильность сбрасывает до полной частоты проверок.
Отслеживание дефицита DRR++
Заголовок раздела «Отслеживание дефицита DRR++»Адаптировано из алгоритма справедливости потоков сети CAKE:
- Каждая задача начинает с дефицита (квант + бонус нового потока ≈ 10 мс кредита)
- Каждое исполнение потребляет дефицит пропорционально времени выполнения
- При исчерпании дефицита → бонус нового потока удаляется → задача конкурирует в обычном режиме
- Это даёт вновь порождённым потокам (игра, запускающая рабочий поток) мгновенную отзывчивость, которая естественным образом затухает
DVFS (масштабирование частоты ЦП)
Заголовок раздела «DVFS (масштабирование частоты ЦП)»Каждый уровень отображается на целевую производительность ЦП через таблицу поиска RODATA:
| Уровень | Цель | Обоснование |
|---|---|---|
| T0-T2 | 100% (максимальная частота) | Игровые нагрузки требуют полной производительности |
| T3 | 75% | Фоновая работа может выполняться немного медленнее для экономии энергии |
На гибридных ЦП Intel (has_hybrid = true) цели масштабируются по cpuperf_cap каждого ядра для предотвращения избыточного запроса частоты на E-ядрах.
Профили (--profile, -p)
Заголовок раздела «Профили (--profile, -p)»| Профиль | Квант | Голодание | Сценарий использования |
|---|---|---|---|
| gaming | 2ms | 100ms | (По умолчанию) Сбалансирован для большинства игр |
| esports | 1ms | 50ms | Соревновательный шутер от первого лица, сверхнизкая задержка |
| legacy | 4ms | 200ms | Старые ЦП, экономия заряда батареи |
| default | 2ms | 100ms | Псевдоним для gaming |
Аргументы командной строки
Заголовок раздела «Аргументы командной строки»| Аргумент | По умолчанию | Описание |
|---|---|---|
--profile, -p <PROFILE> |
gaming |
Выбрать предустановленный профиль |
--quantum <µs> |
профиль | Базовый временной срез в микросекундах |
--new-flow-bonus <µs> |
профиль | Дополнительный дефицит для только что разбуженных задач |
--starvation <µs> |
профиль | Максимальное время выполнения до принудительного вытеснения |
--verbose, -v |
false |
Включить отображение статистики TUI в реальном времени |
--interval <secs> |
1 |
Интервал обновления TUI |
Тонкая настройка по уровням (игровой профиль)
Заголовок раздела «Тонкая настройка по уровням (игровой профиль)»| Уровень | Множитель кванта | Эффективный срез | Лимит голодания |
|---|---|---|---|
| T0 Critical | 0.75x | 1.5ms | 3ms |
| T1 Interactive | 1.0x | 2.0ms | 8ms |
| T2 Frame | 1.2x | 2.4ms | 40ms |
| T3 Bulk | 1.4x | 2.8ms | 100ms |
Разработчик: Andrea Righi (arighi GitHub)
- Готов к использованию в production?
Легковесный планировщик, оптимизированный для сохранения локальности «задача-ЦП».
Когда система не насыщена, планировщик отдает приоритет удержанию задач на одном и том же ЦП с помощью локальных DSQ. Это не только сохраняет локальность, но и снижает конфликты блокировок по сравнению с общими DSQ, обеспечивая хорошую масштабируемость на многих ЦП.
- Сценарии использования:
- Планировщик общего назначения: планировщик должен адаптироваться как для серверных, так и для настольных рабочих нагрузок.
Режимы планировщика
Заголовок раздела «Режимы планировщика»Авто (Auto)
Заголовок раздела «Авто (Auto)»- Флаги командной строки:
-s 20000 -d -c 0 -p 0 - Описание: Жертвует локальностью кэша и энергоэффективностью ради равномерного распределения по всем ЦП. Больше ориентирован на интерактивные нагрузки.
Игры (Gaming)
Заголовок раздела «Игры (Gaming)»- Флаги командной строки:
-c 0 -p 0 - Описание: Отключает отслеживание загрузки ЦП и всегда применяет планирование на основе крайних сроков для улучшения отзывчивости.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
-m powersave -d -p 5000 - Описание: Приоритезирует энергоэффективность. Отдает предпочтение менее производительным ядрам (например, E-ядрам на Intel) и отключает отложенные пробуждения, снижая пропускную способность при одновременном повышении энергоэффективности. Интервал опроса загрузки ЦП увеличен до 5 мс.
Низкая задержка (Low Latency)
Заголовок раздела «Низкая задержка (Low Latency)»- Флаги командной строки:
-m performance -c 0 -p 0 -w - Описание: Предназначен для снижения задержки за счет пропускной способности. Подходит для приложений мягкого реального времени, таких как обработка аудио и мультимедиа. Всегда применяет планирование на основе крайних сроков и синхронные оптимизации пробуждения для улучшения предсказуемости производительности.
Сервер (Server)
Заголовок раздела «Сервер (Server)»- Флаги командной строки:
-s 20000 - Описание: Включает сродство к адресному пространству для улучшения локальности и производительности в некоторых нагрузках, чувствительных к кэшу. Интервал опроса увеличен до 20 мс.
Разработчик: Andrea Righi (arighi GitHub)
Готов к использованию в production?
Планировщик, который фокусируется на обеспечении справедливости между задачами и предсказуемости производительности.
Он работает по политике earliest deadline first (EDF), где каждой задаче присваивается весовой коэффициент «задержки». Этот вес динамически корректируется в зависимости от того, как часто задача освобождает ЦП до истечения полного временного кванта.
Задачи, которые освобождают ЦП раньше, получают более высокий весовой коэффициент задержки, что дает им приоритет перед задачами, которые полностью используют свой временной квант.
- Сценарии использования:
- Игры
- Нагрузки, чувствительные к задержкам, такие как мультимедиа или обработка аудио в реальном времени
- Необходимость отзывчивости в условиях перегрузки
- Стабильность производительности
- Сервер
Режимы планировщика
Заголовок раздела «Режимы планировщика»Низкая задержка (Low Latency)
Заголовок раздела «Низкая задержка (Low Latency)»- Флаги командной строки:
-m performance -w -C 0 - Описание: Предназначен для снижения задержки за счет пропускной способности. Подходит для приложений мягкого реального времени, таких как обработка аудио и мультимедиа.
Игры (Gaming)
Заголовок раздела «Игры (Gaming)»- Флаги командной строки:
-m all - Описание: Оптимизирует для высокой производительности в играх.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Описание: Приоритезирует энергоэффективность. Отдает предпочтение менее производительным ядрам (например, E-ядрам на Intel) и вводит принудительный цикл простоя каждые 10 мс для увеличения энергосбережения.
Сервер (Server)
Заголовок раздела «Сервер (Server)»- Флаги командной строки:
-m all -s 20000 -S 1000 -I -1 -D -L - Описание: Настроен для серверных нагрузок. Жертвует отзывчивостью ради пропускной способности.
Разработчик: Changwoo Min (multics69 GitHub).
- Готов к использованию в production?
Краткое введение в LAVD от Changwoo:
LAVD — это новый алгоритм планирования, который все еще находится в разработке. Он создан с учетом игровых нагрузок, которые критичны к задержкам и интенсивны в обмене данными. Его цель — минимизировать пики задержек, сохраняя при этом хорошую общую пропускную способность и справедливое использование времени ЦП между задачами.
- Сценарии использования:
- Игры
- Производство аудио
- Нагрузки, чувствительные к задержкам
- Использование на настольном компьютере
- Отличная интерактивность при интенсивных нагрузках
- Энергосбережение
Одной из основных и замечательных возможностей LAVD является Уплотнение ядер (Core Compaction). Если не вдаваться в технические детали: когда загрузка ЦП < 50%, активные в данный момент ядра будут работать дольше и на более высокой частоте. В то же время бездействующие ядра будут оставаться в C-состоянии (режиме сна) гораздо дольше, что приводит к меньшему общему энергопотреблению.
Режимы планировщика
Заголовок раздела «Режимы планировщика»Игры и Низкая задержка (Gaming & Low Latency)
Заголовок раздела «Игры и Низкая задержка (Gaming & Low Latency)»- Флаги командной строки:
--performance - Описание: Максимизирует производительность за счет использования всех доступных ядер, отдавая приоритет физическим ядрам.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
--powersave - Описание: Минимизирует энергопотребление, сохраняя при этом приемлемую производительность. Отдает приоритет эффективным ядрам и потокам перед физическими ядрами.
Разработчик: Will Clingan (willclngn GitHub)
Планировщик с поведенческой классификацией, использующий оценку на основе EWMA (частота пробуждений, скорость переключения контекста, дисперсия времени выполнения) для сортировки задач по трём уровням диспетчеризации — LAT_CRITICAL, INTERACTIVE и BATCH — каждый из которых имеет свой временной срез, правила вытеснения и маршрутизацию DSQ. Механизм восстановления задержавшихся задач под вдохновением CoDel отслеживает время ожидания в пакетной очереди и восстанавливает стареющие задачи до их зависания, с пороговыми значениями, адаптированными к скорости диспетчеризации и количеству ядер. Двойное обнаружение всплесков (точка изменения CUSUM + счётчик частоты пробуждений) обрабатывает шторм форков, а адаптивный управляющий цикл Rust регулирует параметры планирования раз в секунду на основе обнаружения режима нагрузки и телеметрии гистограмм BPF.
Композиторы (KWin, GNOME Shell, Hyprland, Sway и другие) автоматически повышаются до LAT_CRITICAL. Постоянная база данных процессов изучает классификации задач между перезагрузками.
- Сценарии использования:
- Игры
- Использование на настольном компьютере
- Производство мультимедиа/аудио
- Компиляция кодовой базы
- Интерактивность при интенсивных нагрузках
- Смешанные нагрузки
Режимы планировщика
Заголовок раздела «Режимы планировщика»По умолчанию (адаптивный)
Заголовок раздела «По умолчанию (адаптивный)»- Флаги командной строки: (нет — адаптивный режим по умолчанию)
- Описание: Полный адаптивный режим. Управляющий цикл Rust определяет режим нагрузки (LIGHT / MIXED / HEAVY) и регулирует параметры планирования в реальном времени. Лучший выбор для общего использования рабочего стола и игр.
Только BPF
Заголовок раздела «Только BPF»- Флаги командной строки:
--no-adaptive - Описание: Отключает адаптивный управляющий цикл Rust. Планировщик BPF работает со статическими параметрами настройки. Меньше накладных расходов, полезно для бенчмаркинга или если адаптивный слой перекорректирует вашу нагрузку.
Подробный / отладочный
Заголовок раздела «Подробный / отладочный»- Флаги командной строки:
-vили--verbose - Описание: Включает подробный вывод телеметрии, включая счётчики диспетчеризации по уровням, времена ожидания и статистику поведенческой классификации. Полезно для диагностики поведения планировщика.
- Готов к использованию в production?
- Да. Если правильно настроен для вашей конкретной нагрузки и оборудования.
Разработчик: Дэниел Ходжес (Daniel Hodges) (hodgesds GitHub)
Планировщик общего назначения, который фокусируется на балансировке нагрузки “выбери два” (pick two) между LLC. Сохраняет высокую локальность кэша и консервацию работы, обеспечивая при этом приемлемую задержку.
- Сценарии использования:
- Сервер
- Настольные окружения
- Игры (с некоторой ручной настройкой)
Режимы планировщика
Заголовок раздела «Режимы планировщика»Игры (Gaming)
Заголовок раздела «Игры (Gaming)»- Флаги командной строки:
--task-slice true -f --sched-mode performance - Описание: Улучшает стабильность производительности в играх и увеличивает смещение в сторону планирования на более производительных ядрах.
Низкая задержка (Low Latency)
Заголовок раздела «Низкая задержка (Low Latency)»- Флаги командной строки:
-y -f --task-slice true - Описание: Снижает задержку за счет того, что интерактивные задачи сильнее “прилипают” к назначенному им ЦП, и увеличивает стабильность временного кванта.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
--sched-mode efficiency - Описание: Повышает энергоэффективность за счет приоритезации энергоэффективных ядер.
Сервер (Server)
Заголовок раздела «Сервер (Server)»- Флаги командной строки:
--keep-running - Описание: Улучшает производительность серверных нагрузок, позволяя задачам выполняться дольше своего кванта времени, если ЦП простаивает.
Разработчик: Andrea Righi (arighi Github)
- Готов к использованию в production?
- Этот планировщик все еще является экспериментальным и не рекомендуется для использования в production.
scx_tickless — это ориентированный на серверы планировщик, разработанный для облачных вычислений, виртуализации и высокопроизводительных вычислений.
Планировщик работает, направляя все события планирования через пул основных ЦП, назначенных для обработки этих событий. Это позволяет отключить тик планировщика на других ЦП, уменьшая шум ОС.
- Сценарии использования:
- Облачные вычисления
- Виртуализация
- Высокопроизводительные вычисления
- Сервер
Режимы планировщика
Заголовок раздела «Режимы планировщика»Игры (Gaming)
Заголовок раздела «Игры (Gaming)»- Флаги командной строки:
-f 5000 -s 5000 - Описание: Повышает производительность в играх за счет увеличения частоты обнаружения планировщиком конфликтов на ЦП и запуска переключений контекста с более коротким временным квантом.
Энергосбережение (Power Save)
Заголовок раздела «Энергосбережение (Power Save)»- Флаги командной строки:
-f 50 - Описание: Повышает энергоэффективность за счет снижения частоты проверок на конфликты.
Низкая задержка (Low Latency)
Заголовок раздела «Низкая задержка (Low Latency)»- Флаги командной строки:
-f 5000 -s 1000 - Описание: Аналогично игровому профилю, но с еще более коротким квантом времени.
Сервер (Server)
Заголовок раздела «Сервер (Server)»- Флаги командной строки:
-f 100 - Описание: Снижена частота проверок планировщиком на конфликты ЦП для улучшения пропускной способности за счет отзывчивости.
Разработчик: Andrea Righi (arighi GitHub)
Готов к использованию в production?
Для критически важных к производительности сценариев в production другие планировщики, вероятно, покажут лучшую производительность, так как перенос всех решений по планированию в пользовательское пространство имеет свою цену (пусть и минимальную).
Однако планировщик, полностью реализованный в пользовательском пространстве, обладает потенциалом для бесшовной интеграции со сложными библиотеками, инструментами трассировки, внешними сервисами (например, ИИ) и т. д.
Следовательно, могут возникнуть ситуации, когда преимущества перевешивают накладные расходы, оправдывая использование этого планировщика в производственной среде.
Имеет сходства с bpfland, создан с целью быть легким для чтения и понимания его работы благодаря реализации в пользовательском пространстве.
Имейте в виду, что при использовании планировщика в пользовательском пространстве наблюдается небольшое снижение пропускной способности.
- Сценарии использования:
- Нагрузки с низкой задержкой (игры, видеоконференции и прямые трансляции)
- Использование на настольном компьютере
Разработчик: Дэвид Вернет (David Vernet) (Byte-Lab GitHub)
- Готов к использованию в production?
- Да. При правильной настройке.
Rusty предлагает широкий спектр функций, которые расширяют его возможности, обеспечивая большую гибкость для различных сценариев использования. Одной из таких функций является возможность тонкой настройки, позволяющая вам адаптировать Rusty в соответствии с вашими предпочтениями и конкретными требованиями.
- Сценарии использования:
- Игры
- Нагрузки, чувствительные к задержкам
- Использование на настольном компьютере
- Производство мультимедиа/аудио
- Отличная интерактивность при интенсивных нагрузках
- Энергосбережение
Конфигурация и тестирование производительности
Заголовок раздела «Конфигурация и тестирование производительности»LAVD Autopilot и Autopower
Заголовок раздела «LAVD Autopilot и Autopower»Цитаты от Changwoo Min:
-
В режиме автопилота планировщик регулирует свой режим энергопотребления —
Powersave, Balanced или Performance— в зависимости от нагрузки на систему, а именно от загрузки ЦП. -
Autopower: автоматически определяет режим энергопотребления планировщика на основе энергетического профиля системы, также известного как EPP (Energy Performance Preference).
# Autopower можно активировать с помощью следующего флага:--autopower# например:scx_lavd --autopowerananicy-cpp и sched-ext
Заголовок раздела «ananicy-cpp и sched-ext»Чтобы отключить/остановить ananicy-cpp, выполните следующую команду:
systemctl disable --now ananicy-cppПереключение профилей производительности scx_loader
Заголовок раздела «Переключение профилей производительности scx_loader»Реализовано в пакете power-profiles-daemon, предоставляемом CachyOS, который включает в себя пользовательский патч для поддержки переключения профилей производительности scx_loader.
- Если
scx_loaderзапущен, то при использовании game-performance он автоматически переключит активный планировщик на профильGamingпри запуске игры и вернется к профилю по умолчанию после ее закрытия. - При смене профилей производительности, например, в KDE Plasma или GNOME с помощью переключателя профилей,
scx_loaderавтоматически переключится на соответствующий профиль планировщика:
| Power Profile | Scheduler Profile |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Бенчмаркинг и сравнение планировщиков с помощью cachyos-benchmarker
Заголовок раздела «Бенчмаркинг и сравнение планировщиков с помощью cachyos-benchmarker»Инструмент cachyos-benchmarker предоставляет простой способ оценки и сравнения производительности различных планировщиков ЦП.
Он запускает полный набор тестов для измерения производительности ЦП, памяти и общей производительности системы при различных рабочих нагрузках.
Включены следующие тесты:
| Тест | Что измеряет | Инструмент |
|---|---|---|
| stress-ng cpu-cache-mem | Производительность ЦП, кэша и памяти | stress-ng |
| Компиляция FFmpeg | Производительность параллельной сборки | make |
| Кодирование x265 | Пропускная способность кодирования видео | x265 |
| Хеширование argon2 | Многопоточное хеширование паролей | argon2 |
| perf sched msg | Переключение контекста и производительность IPC | perf |
| perf memcpy | Пропускная способность памяти memcpy() |
perf |
| Вычисление простых чисел | Целочисленная арифметика и параллелизм | primesieve |
| NAMD | Молекулярная динамика (научная нагрузка) | namd3 |
| Рендеринг в Blender | 3D-рендеринг только на ЦП | blender |
| Сжатие xz | Пропускная способность сжатия | xz |
| Сборка Kernel defconfig | Производительность компиляции ядра | make |
| y-cruncher | Математическая точность и нагрузка на память | y-cruncher |
cachyos-benchmarker можно использовать для нескольких целей, в том числе:
- Тестирование стабильности планировщика
Запустите полный набор тестов для обнаружения зависаний, сбоев или регрессий, вызванных изменениями в планировщике.
Если вы используете
scx_loader, вы можете собрать логи в случае зависания или сбоя с помощью:Это создаст файл с именемTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logв вашем текущем каталоге. - Сравнение производительности планировщиков
- Оцените различия в производительности между планировщиками. Например,
BPFLAND против LAVD.
- Оцените различия в производительности между планировщиками. Например,
- Измерение влияния обновлений ядра или планировщика
- Сравните запуски до и после применения патчей или изменений версий, чтобы проверить наличие регрессий или улучшений производительности.
- Тестирование настроек конфигурации
- Оцените влияние изменений, таких как настройки регулятора ЦП, переключение SMT или изменённые флаги планировщика.
Требования
Заголовок раздела «Требования»- 4 ГБ ОЗУ или более
- Не менее 8 ГБ свободного места на диске
- Время и терпение — полный тест может занять более часа на медленных системах
Установка
Заголовок раздела «Установка»Для установки cachyos-benchmarker выполните следующую команду:
sudo pacman -S cachyos-benchmarkerЗапуск теста
Заголовок раздела «Запуск теста»- Выполните
cachyos-benchmarker:Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# Вы можете заменить ~/cachyos-benchmarker/ на любой каталог, в который вы хотите сохранять логи. - Подождите, пока завершатся подготовительные шаги.
- Следуйте подсказкам:
Do you want to drop page cache now? Root privileges needed! (y/N) y(Хотите сбросить кэш страниц сейчас? Требуются права root! (д/Н) д)Please enter a name for this run, or leave empty for default:(Пожалуйста, введите имя для этого запуска или оставьте поле пустым для значения по умолчанию:)
- Дождитесь окончания тестов.
- После завершения произойдёт следующее:
- Создание лог-файла с именем вида
benchie_<имя>_<ДАТА>.log, который содержит подробную информацию о запуске теста.- Пример:
benchie_p2dq_2025-09-29-2115.log - Скрипт
benchmark_scraper.pyбудет автоматически выполнен для создания сводного отчёта в формате HTML. - Что делает скрипт?:
- Читает все файлы
benchie_*.logв указанном каталоге. - Извлекает названия тестов, время и оценки.
- Сортирует или агрегирует их.
- Выводит в терминал краткую сводку результатов и создаёт HTML-файл, который можно открыть в браузере.
Пример вывода в терминале:
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1Пример HTML-отчёта с результатами теста, сравнивающего две разные ветки одного и того же планировщика:
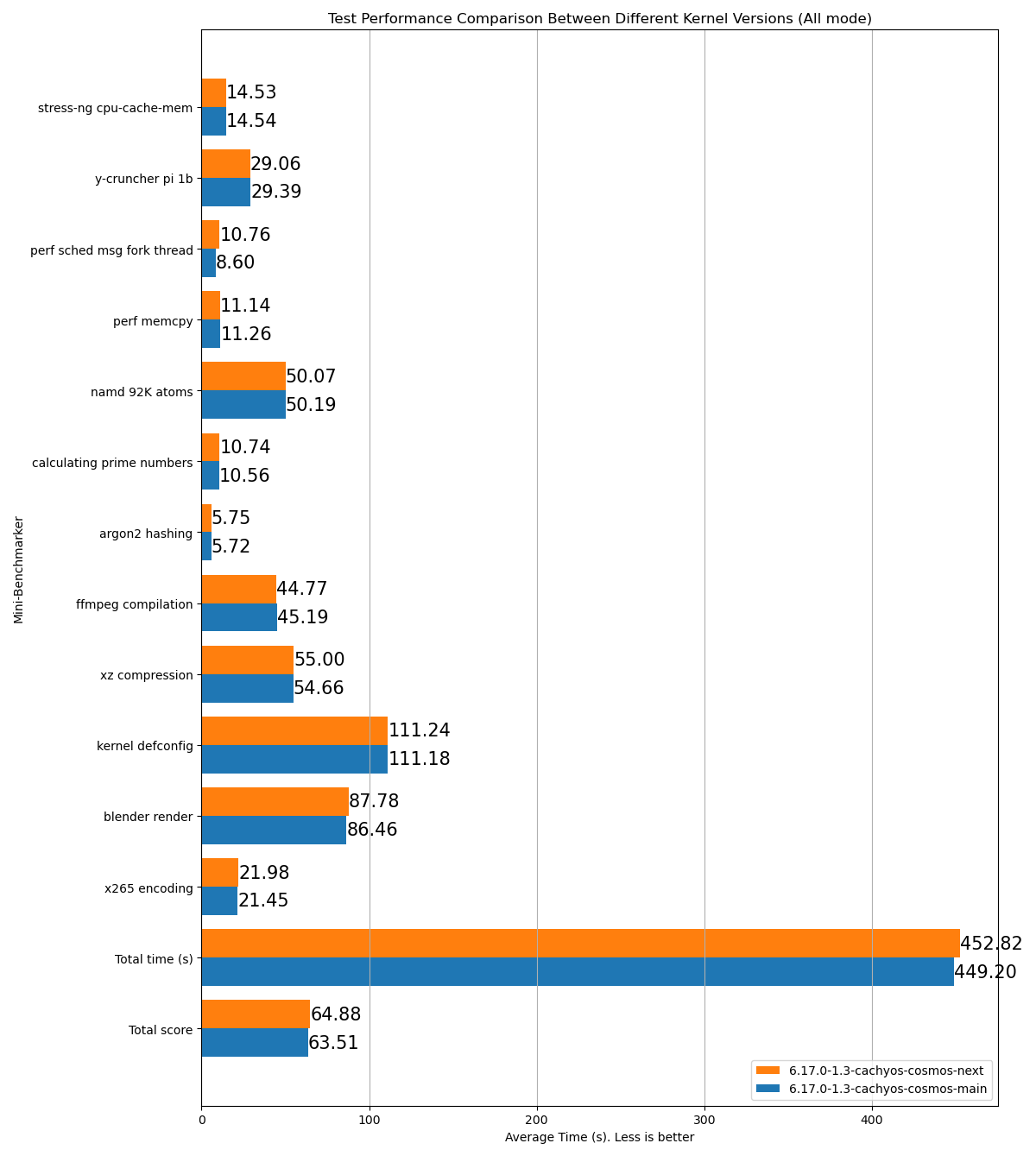
- Читает все файлы
- Пример:
- Создание лог-файла с именем вида
- Чтобы сравнить два или более запуска, поместите файлы
.logв один и тот же каталог перед запускомbenchmark_scraper.py. Инструмент автоматически обнаружит и сравнит их в HTML-отчёте.
Тестирование задержек планировщика с помощью schbench
Заголовок раздела «Тестирование задержек планировщика с помощью schbench»schbench — это бенчмарк для планировщиков, предназначенный для измерения задержек планировщика при симулированной рабочей нагрузке в стиле сервера. Он создаёт настраиваемое количество потоков-«обработчиков» и потоков-«сообщений», где сообщения многократно пробуждают обработчиков. Измеряя распределение задержек от пробуждения до выполнения этих потоков-обработчиков, он предоставляет критически важную информацию о способности ядра обрабатывать пробуждения потоков, балансировку и конкуренцию за ЦП, особенно под нагрузкой.
Сценарии использования
Заголовок раздела «Сценарии использования»Вы можете использовать schbench для:
- Оценки задержек планировщика: Определить, как быстро потоки планируются после пробуждения.
- Сравнения производительности пробуждения между планировщиками: Обнаружить улучшения или регрессии в переключении контекста и задержках пробуждения.
- Тестирования влияния патчей на ядро или планировщик: Оценить, влияют ли настройки или обновления на справедливость и отзывчивость планирования.
Установка
Заголовок раздела «Установка»schbench доступен в репозиториях CachyOS:
sudo pacman -S schbenchЗапуск теста
Заголовок раздела «Запуск теста»Простой способ запустить schbench для общего теста задержек:
schbench -m 2 -t 8 -r 60В этом примере запускается:
- 2 потока сообщений (
-m 2) - 8 потоков-обработчиков на каждый поток сообщений (
-t 8) - на общее время выполнения 60 секунд (
-r 60)
Вы можете настроить эти значения в зависимости от количества ядер вашего ЦП и желаемого уровня нагрузки.
Вот таблица, объясняющая некоторые из ключевых опций:
| Опция | Описание |
|---|---|
-C, --calibrate |
Запустить калибровку и сообщить о времени (без теста). |
-L, --no-locking |
Отключить спин-блокировки во время работы ЦП (по умолчанию: блокировки включены). |
-m, --message-threads <n> |
Количество потоков сообщений (по умолчанию: 1). |
-t, --threads <n> |
Потоки-обработчики на каждый поток сообщений (по умолчанию: количество ЦП). |
-r, --runtime <sec> |
Продолжительность теста (по умолчанию: 30). |
-F, --cache_footprint <KB> |
Размер занимаемой кэш-памяти (по умолчанию: 256). |
-n, --operations <count> |
Количество операций “времени на раздумье” (по умолчанию: 5). |
-A, --auto-rps |
Автоматически увеличивать RPS до достижения целевой загрузки ЦП. |
-R, --rps <count> |
Режим запросов в секунду. |
-p, --pipe <bytes> |
Симулировать тест передачи данных через pipe. |
-w, --warmuptime <sec> |
Время разогрева перед сбором статистики (по умолчанию: 0). |
-i, --intervaltime <sec> |
Интервал для вывода задержек (по умолчанию: 10). |
-z, --zerotime <sec> |
Интервал для обнуления статистики задержек (по умолчанию: никогда). |
Понимание вывода
Заголовок раздела «Понимание вывода»После каждого запуска schbench выводит перцентили задержек, например:
Пример вывода
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Как интерпретировать результаты
Заголовок раздела «Как интерпретировать результаты»- Wakeup Latencies (Задержки пробуждения):
- Измеряет, как быстро потоки пробуждаются после получения сигнала.
- Более низкие значения здесь (особенно 99-й перцентиль) означают, что планировщик более отзывчив.
- Измеряет, как быстро потоки пробуждаются после получения сигнала.
- Request Latencies (Задержки запросов):
- Представляет время, затраченное на выполнение запросов между потоками.
- Более низкая задержка указывает на лучшую межпоточную коммуникацию и эффективность планирования.
- Представляет время, затраченное на выполнение запросов между потоками.
- RPS (Requests Per Second - Запросов в секунду):
- Показывает устойчивую пропускную способность:
- Более высокий средний RPS указывает на то, что планировщик может обрабатывать больше работы в секунду при данной конфигурации.
- Показывает устойчивую пропускную способность:
В заключение:
- Хороший планировщик будет показывать низкие задержки пробуждения и запросов при стабильном RPS.
- Менее эффективный планировщик может демонстрировать высокие скачки задержек или нестабильные значения RPS с течением времени.
Рекомендации по бенчмаркингу игр
Заголовок раздела «Рекомендации по бенчмаркингу игр»Если вы хотите провести тестирование игр для сравнения производительности различных планировщиков, вот несколько советов, чтобы получить наиболее точные результаты:
- Используйте встроенные бенчмарки: Многие современные игры поставляются со встроенными инструментами для тестирования. Они предназначены для получения согласованных результатов путём выполнения одной и той же последовательности событий каждый раз.
- Посмотрите на этом сайте список игр, включающих встроенные бенчмарки.
- Согласованные настройки: Убедитесь, что настройки игры (разрешение, качество графики и т. д.) одинаковы для каждого тестового запуска.
- Закройте фоновые приложения: Другие приложения, работающие в фоновом режиме, могут влиять на производительность. Закройте ненужные программы, чтобы минимизировать их влияние.
- Если вы не используете встроенный бенчмарк, старайтесь выполнять одни и те же действия в игре для каждого тестового запуска. Это может включать прохождение одного и того же пути, участие в похожих боевых сценариях или выполнение одних и тех же задач.
- Даже прицеливание в разные точки может привести к разным результатам производительности.
- Множественные запуски: Выполните несколько запусков теста и возьмите среднее значение, чтобы учесть вариативность.
- Используйте инструменты мониторинга производительности: Инструменты, такие как MangoHud или GOverlay, могут предоставлять метрики производительности в реальном времени, такие как FPS, время кадра и загрузка ЦП/ГП.
- Используйте сочетания клавиш или макросы:
- Один из примеров — создать сочетание клавиш, с помощью которого можно переключаться между различными планировщиками или изменять их режимы прямо в игре.
- Это можно сделать с помощью такого инструмента, как scxctl, или создав собственные скрипты, которые изменяют активный планировщик и его режим.
- Один из примеров — создать сочетание клавиш, с помощью которого можно переключаться между различными планировщиками или изменять их режимы прямо в игре.
Загрузка и обмен вашими результатами тестов
Заголовок раздела «Загрузка и обмен вашими результатами тестов»Этот сайт содержит список тестов, проведённых сообществом с использованием различных планировщиков или тестированием различных настроек.
Чтобы загрузить свои собственные тесты, вам нужно будет привязать свою учётную запись Discord к веб-сайту, и после этого вы сможете отправлять свои собственные результаты.
Затем нажмите на кнопку New benchmark (Новый тест) и заполните необходимую информацию.
- Вы можете загружать несколько результатов для одной и той же игры, используя разные планировщики или настройки.
- Принимаются логи как от MangoHud, так и от Afterburner.
- Позволяет искать по названию или описанию.
Переход с scx.service на scx_loader: подробное руководство
Заголовок раздела «Переход с scx.service на scx_loader: подробное руководство»Для начала давайте подробно сравним структуру файла scx.service со структурой файла конфигурации scx_loader.
Если у вас ранее был запущен LAVD со старым scx.service, как в примере ниже:
# Список scx_планировщиков: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Установка пользовательских флагов для планировщикаSCX_FLAGS='--performance'Тогда эквивалентная запись в файле конфигурации scx_loader будет выглядеть так:
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Дополнительную информацию о настройке файла scx_loader можно найти здесь
Следуйте руководству ниже для простого перехода от службы systemd scx к новой утилите scx_loader.
-
Отключение scx.service в пользу scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Создание файла конфигурации для scx_loader и добавление базовой структуры # Редактор Micro создаст новый файл.sudo micro /etc/scx_loader.toml# Добавьте следующие строки:default_sched = "scx_bpfland" # Измените эту строку на планировщик, который scx_loader должен запускать при загрузкеdefault_mode = "Auto" # Возможные значения: "Auto", "Gaming", "LowLatency", "PowerSave".# Нажмите CTRL + S, чтобы сохранить изменения, и CTRL + Q, чтобы выйти из Micro. -
Перезапуск scx_loader systemctl restart scx_loader.service- Готово, теперь scx_loader будет загружать и запускать нужный планировщик.
Отладка в scx_loader
Заголовок раздела «Отладка в scx_loader»-
Проверка статуса службы systemctl status scx_loader.service -
Просмотр всех записей журнала службы journalctl -u scx_loader.service -
Просмотр логов только текущей сессии journalctl -u scx_loader.service -b 0
Чтобы получить более подробный лог, выполните следующие шаги.
-
Редактирование файла службы sudo systemctl edit scx_loader.service -
Добавьте следующую строку в раздел [Service] Environment=RUST_LOG=trace -
Перезапустите службу sudo systemctl restart scx_loader.service - Снова проверьте логи для получения более подробной отладочной информации.
Так много вариантов… почему нельзя просто сделать один планировщик, который хорош во всём?
Заголовок раздела «Так много вариантов… почему нельзя просто сделать один планировщик, который хорош во всём?»Главная причина в том, что не существует универсального решения в области планирования ЦП. Разные нагрузки предъявляют разные требования и имеют разные приоритеты, а планировщик, оптимизированный для одного типа нагрузки, может плохо работать с другим.
Вы можете представить планировщики ЦП как разную обувь, каждая из которых предназначена для определённой деятельности. Например, запуск игры на планировщике, оптимизированном для серверных нагрузок, может привести к неоптимальной производительности и повышенной задержке, тогда как использование планировщика, разработанного для игр, на сервере может привести к неэффективному использованию ресурсов и снижению пропускной способности.
В этом и заключается магия sched-ext. Ограничения больше не являются проблемой.
Почему планировщик X работает хуже, чем другой?
Заголовок раздела «Почему планировщик X работает хуже, чем другой?»- При их сравнении следует учитывать множество переменных. Например, как они измеряют “вес” задачи? Приоритезируют ли они интерактивные задачи перед неинтерактивными? В конечном счете, это зависит от их проектных решений.
Почему все говорят, что планировщик X лучший для случая Y, но у меня он работает не так хорошо?
Заголовок раздела «Почему все говорят, что планировщик X лучший для случая Y, но у меня он работает не так хорошо?»- Как и в предыдущем ответе, выбор процессора и его архитектура, такая как расположение ядер, способ совместного использования кэша между ядрами и другие связанные факторы, могут привести к тому, что планировщик будет работать менее эффективно.
- Вот почему наличие выбора является одной из сильных сторон фреймворка sched-ext, поэтому не бойтесь пробовать разные варианты и выяснять, какой из них лучше всего подходит для вашего сценария использования.
Примеры: стабильность FPS, максимальная производительность, отзывчивость при интенсивных нагрузках и т.д.
Сценарии использования этих планировщиков довольно похожи… почему так?
Заголовок раздела «Сценарии использования этих планировщиков довольно похожи… почему так?»В основном потому, что это многоцелевые планировщики, что означает, что они могут справляться с различными рабочими нагрузками, даже если они не преуспевают в каждой области.
- Чтобы определить, какой планировщик подходит вам лучше всего, нет лучшего совета, чем попробовать его самостоятельно.
Почему у меня отсутствует планировщик, который некоторые пользователи упоминают или тестируют на Discord-сервере CachyOS?
Заголовок раздела «Почему у меня отсутствует планировщик, который некоторые пользователи упоминают или тестируют на Discord-сервере CachyOS?»Убедитесь, что вы используете самую последнюю версию пакета scx-scheds под названием scx-scheds-git
- Одной из причин может быть то, что этот планировщик очень новый и в настоящее время тестируется пользователями, поэтому он еще не был добавлен в пакет
scx-scheds-git.
Почему планировщик внезапно перестал работать? Он нестабилен?
Заголовок раздела «Почему планировщик внезапно перестал работать? Он нестабилен?»- Этому могло быть несколько причин:
- Одна из самых частых причин — вы использовали ananicy-cpp вместе с планировщиком. Именно поэтому мы добавили это предупреждение
- Другой причиной может быть то, что выполняемая вами рабочая нагрузка превысила пределы и возможности планировщика, что привело к его остановке.
- Пример чрезмерной нагрузки:
hackbench
- Пример чрезмерной нагрузки:
- Или более очевидная причина — вы нашли баг в планировщике. В таком случае, пожалуйста, сообщите об этом как о проблеме на их GitHub или дайте им знать
об этом на Discord-канале CachyOS
sched-ext
Я ранее использовал scx_loader в графическом интерфейсе Kernel Manager. Нужно ли мне все равно выполнять шаги по переходу?
Заголовок раздела «Я ранее использовал scx_loader в графическом интерфейсе Kernel Manager. Нужно ли мне все равно выполнять шаги по переходу?»- В данном конкретном случае нет, это не обязательно, потому что Kernel Manager уже выполняет процесс перехода.
- За исключением случаев, когда вы ранее добавляли пользовательские флаги в
/etc/default/scxи все еще хотите их использовать.
- За исключением случаев, когда вы ранее добавляли пользовательские флаги в
Узнайте больше
Заголовок раздела «Узнайте больше»- Плейлист Sched_ext на YouTube
- LWN: Расширяемый класс планировщика (февраль, 2023)
- Блог arighi: Реализуйте свой собственный планировщик ЦП в ядре Ubuntu с помощью sched_ext (июль, 2023)
- Доклад от David Vernet: Kernel Recipes 2023 - sched_ext: подключаемое планирование в ядре Linux (сентябрь, 2023)
- Блог Changwoo: sched_ext: расширяемый BPF класс планировщика (Часть 1) (декабрь, 2023)
- Блог arighi: Начало работы с разработкой sched_ext (апрель, 2024)
- Блог Changwoo: sched_ext: архитектура и интерфейсы планировщика (Часть 2) (июнь, 2024)
- YouTube-канал arighi: Демонстрация планировщика Linux scx_bpfland: осведомленность о топологии (август, 2024)
- Доклад от David Vernet: Kernel Recipes 2024 - Планирование со сверхспособностями: использование sched_ext для получения большого прироста производительности (сентябрь, 2024)