sched-ext チュートリアル
Extensible Scheduler Class (sched-ext とも呼ばれます) は BPF (Berkeley Package Filter) でカーネルスレッドスケジューラを実装して動的に読み込めるようにする Linux カーネルの機能です。これにより、異なるスケジューラを使用するためだけに別のカーネルをビルドすることなく、エンドユーザーがユーザー空間でスケジューラを変更できるようになります。
-
スケジューラは
scx-schedsとscx-scheds-gitパッケージに含まれています。Terminal window # 安定版ブランチ + scx_loader と scxctl ツールsudo pacman -S scx-scheds scx-tools# 最新版ブランチ (マスターブランチの最新変更が含まれる) + scx_loader と scxctl ツールsudo pacman -S scx-scheds-git scx-tools-git
スケジューラの起動と管理方法
Section titled “スケジューラの起動と管理方法”- スケジューラを起動するには、ターミナルを開いて以下のコマンドを入力してください。
rusty を起動する例 sudo scx_rusty
これにより rusty スケジューラが起動し、デフォルトスケジューラが切り離されます。
スケジューラを停止するには CTRL + C を押してください。スケジューラが停止し、デフォルトのカーネルスケジューラに戻ります。
scxctl は scx_loader と連携するための CLI の DBUS クライアントです。
- 機能
- 現在のスケジューラとモードの取得
- 利用可能なスケジューラの一覧表示
- 指定したモードまたは引数でスケジューラを起動
- スケジューラとモードの切り替え
- 実行中のスケジューラの停止
- 実行中のスケジューラの再起動
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --help使用法: scxctl <コマンド>
コマンド: get 実行中のスケジューラの情報を取得 list 対応しているスケジューラの一覧を取得 start 指定したモードまたは引数でスケジューラを起動 switch 任意で引数付きでスケジューラとモードの切り替え stop 実行中のスケジューラの停止 restart 標準設定で実行中のスケジューラの再起動 restore 設定からデフォルトのスケジューラを復元 help このメッセージを出力するかサブコマンドのヘルプを表示
オプション: -h, --help ヘルプを出力 -V, --version バージョンを出力名前の通り、D-Bus インターフェースを使って sched-ext フレームワークのローダーおよびマネージャーとして機能するツールです。
systemd は必須ではありませんが、組み合わせて使うこともできます。移行ガイドをご覧ください。
- scx スケジューラの停止、起動、再起動、情報の読み取りなどができます。
dbus-sendやgdbusなどのツールで通信できます。
- ここでは scx_loader を dbus-send コマンドで使う方法を説明します。
-
デフォルト引数で scx_rusty を起動する dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
引数付きでスケジューラを起動する # この例では scx_bpfland を -k -c 0 フラグで起動しますdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
現在実行中のスケジューラを停止する dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
デフォルトスケジューラに切り替える # scx_loader は scx_loader 設定ファイルに設定されたデフォルトスケジューラに切り替えますdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
モード 2 で別のスケジューラに切り替える dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# scx_lavd をスケジューラモード 2 (省電力) で起動します -
引数付きで別のスケジューラに切り替える dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
現在実行中のスケジューラを取得する dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
対応しているスケジューラの一覧を取得する dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
sched-ext スケジューラ設定 ボタンからアクセスして設定できます。
SCX Manager は CachyOS カーネルマネージャーから派生したスタンドアロンの GUI ツールです。scx_loader を通じて sched-ext フレームワークとそのスケジューラを管理できます。
機能
- 現在アクティブなスケジューラの確認
- スケジューラまたはプロファイルの選択 (Auto, Gaming, Power save, Low Latency, Server)
- 追加フラグの設定
- 現在のスケジューラを無効にする
スクリーンショット

スケジューラガイド: プロファイルと用途
Section titled “スケジューラガイド: プロファイルと用途”えらべるスケジューラが多いため、各スケジューラについて簡単に紹介します。
問題やフィードバックはスケジューラのリポジトリに報告してください。
利用可能なフラグと説明を確認するには scx_schedulername --help を使ってください。
scx_rusty --help開発者: Andrea Righi (arighi GitHub)
本番環境への対応状況
scx_beerland は局所性とスケーラビリティを優先するスケジューラです。
キャッシュの局所性を保つため、処理を同一 CPU で行うようキープすることを優先しながら、システムが飽和していないときはローカルの DSQ (CPU ごとのランキュー) を使って多数の CPU 間で優れたスケーラビリティを生むことができます。
- 用途
- キャッシュ集約型の処理
- 多数の CPU を持つシステム
- ゲーム: 特定のゲームでとてもよく動作することが知られていますが、結果は異なる場合があります。
- サーバー: スケーラビリティと局所性の最適化により汎用サーバー用途に適しています。
- デスクトップ用途にも使えます。
スケジューラモード
Section titled “スケジューラモード”現時点ではありません。
開発者: Andrea Righi (arighi GitHub)
本番環境への対応状況
インタラクティブな処理を優先する vruntime ベースの sched_ext スケジューラです。柔軟性が高く、適応しやすい設計になっています。
Bpfland はどのコアを使うかを決定する際に、キャッシュレイアウトと同じ L2/L3 キャッシュを共有するコアを考慮するため、キャッシュミスが減ってパフォーマンスが向上します。
- 用途
- ゲーム
- デスクトップ用途
- マルチメディア/オーディオ制作
- 高負荷な処理中でも優れた応答性
- 省電力
- サーバー
スケジューラモード
Section titled “スケジューラモード”- コマンドラインフラグ:
-m performance -w - 説明: スループットを代償に遅延を削減します。オーディオ処理やマルチメディアなどのソフトリアルタイムアプリケーションに適しています。
- コマンドラインフラグ:
-s 20000 -m powersave -I 100 -t 100 - 説明: 電力効率を優先します。効率の低いコア (Intel の E コアなど) を優先します。
- コマンドラインフラグ:
-s 20000 -S - 説明: 厳密なアフィニティのあるタスクを優先します。このオプションはレイテンシを代償にスループットを向上させるため、サーバー用途に適しています。
開発者: RitzDaCat (RitzDaCat GitHub)
- 本番環境への対応状況
scx_cake はネットワークの CAKE アルゴリズムの DRR++ (Deficit Round Robin++) を CPU スケジューリングに適用した実験的な BPF CPU スケジューラです。
- 4階層分類 — EWMA avg_runtime に基づいてタスクを Critical / Interactive / Frame / Bulk (訳注: 重要/操作応答/フレームごと/後回し) に分類
- グローバルアトミックなし — MESI ガード書き込みによる CPU ごとの BSS 配列でバスロックをなくす
- カーネル委任のアイドル選択 — scx_bpf_select_cpu_dfl() で信頼性の高い、*ゼロステールネスな CPU 選択
- LLC 毎 DSQ シャーディング — マルチチップレット CPU において CCD をまたぐ際のロック競合をなくす
- DRR++ デフィシットトラッキング — CPU タスクスケジューリングに適応したネットワーク CAKE のフロー公平性アルゴリズム
最新の AMD および Intel ハードウェアでのゲーム用途向けに設計されています。
- 用途
- ゲーム
4階層システム
Section titled “4階層システム”scx_cake はすべてのタスクを EWMA (指数加重移動平均) ランタイムに基づいて4つの層に自動分類します。分類は自動かつ常に行われ、タスクは動作の変化に応じて層間を移動します。
| 層 | 名前 | avg_runtime | 処理内容の例 | クォンタム | スターベーション |
|---|---|---|---|---|---|
| T0 | Critical | 100µs 未満 | IRQ ハンドラ、入力ドライバ、オーディオ (PipeWire)、ネットワーク | 0.5ms | 3ms |
| T1 | Interactive | 2ms 未満 | コンポジター、ゲーム物理、ゲーム AI、短期ワーカー | 2.0ms | 8ms |
| T2 | Frame | 8ms 未満 | ゲームレンダリングスレッド、動画エンコード | 4.0ms | 40ms |
| T3 | Bulk | 8ms 以上 | コンパイル、バックグラウンドインデックス、バッチジョブ | 8.0ms | 100ms |
分類の仕組み
Section titled “分類の仕組み”- 初期配置:
nice値を基準に配置 —nice < 0→ T0,nice 0-10→ T1,nice > 10→ T3 - ランタイムの優先: 3ストップ後、EWMA avg_runtime が信頼性を持ちます。50ms バーストで実行する nice 値が -5 のタスクは nice 値に関わらず T3 に再分類されます。
- ヒステリシス: 層の境界でのゆれを防ぐ10%のデッドバンド (余裕) があります。昇格には avg_runtime がゲートを明確に下回ることが必要で、降格はすぐに行われます。
- 段階的なバックオフ: 層が3ストップ以上安定すると、再分類頻度が層ごとに下がります。T0 は1024ストップごと、T3 は16ストップごとに再確認が行われます。不安定な状態になると全頻度チェックにリセットされます。
DRR++ デフィシットトラッキング
Section titled “DRR++ デフィシットトラッキング”フロー公平性がネットワーク CAKE をもとにスケジューラ用に改変されています。
- 各タスクはデフィシット (クォンタム + 新フローボーナス ≈ 10ms クレジット) から始まります。
- 各実行ブートはランタイムに比例したデフィシットを消費します。
- デフィシットが枯渇した → 新フローボーナスが削除 → タスクは通常通り競合
- これによりワーカーを起動するゲームなどの新規生成スレッドに即座の応答性を与えつつ、その減衰が自然に起こるようになります。
DVFS (CPU 周波数スケーリング)
Section titled “DVFS (CPU 周波数スケーリング)”各層は RODATA ルックアップテーブルを通じて CPU パフォーマンスターゲットにマッピングされます。
| 層 | ターゲット | 理由 |
|---|---|---|
| T0-T2 | 100% (最大周波数) | ゲーム用途には最大パフォーマンスが必要であるため |
| T3 | 75% | バックグラウンド作業は電力節約のために若干遅くてもOK |
Intel ハイブリッド CPU (has_hybrid = true) では、E コアでの過剰な周波数要求を防ぐために各コアの cpuperf_cap によってターゲットがスケーリングされます。
プロファイル (--profile, -p)
Section titled “プロファイル (--profile, -p)”| プロファイル | クォンタム | スターベーション | 用途 |
|---|---|---|---|
| gaming | 2ms | 100ms | (デフォルト) ほとんどのゲームでバランスがとれる |
| esports | 1ms | 50ms | 競技系 FPS、超低遅延 |
| legacy | 4ms | 200ms | 古い CPU、省電力 |
| default | 2ms | 100ms | gaming の別名 |
CLI 引数
Section titled “CLI 引数”| 引数 | デフォルト | 説明 |
|---|---|---|
--profile, -p <PROFILE> |
gaming |
プリセットプロファイルを選択 |
--quantum <µs> |
profile | マイクロ秒単位のベースタイムスライス |
--new-flow-bonus <µs> |
profile | 新規ウェイクアップタスクへの追加デフィシット |
--starvation <µs> |
profile | 強制プリエンプション前の最大実行時間 |
--verbose, -v |
false |
ライブ TUI 統計表示を有効化 |
--interval <secs> |
1 |
TUI リフレッシュ間隔 |
層ごとのチューニング (ゲームプロファイル)
Section titled “層ごとのチューニング (ゲームプロファイル)”| 層 | クォンタム倍率 | 有効スライス | スターベーション上限 |
|---|---|---|---|
| T0 Critical | 0.75倍 | 1.5ms | 3ms |
| T1 Interactive | 1.0倍 | 2.0ms | 8ms |
| T2 Frame | 1.2倍 | 2.4ms | 40ms |
| T3 Bulk | 1.4倍 | 2.8ms | 100ms |
開発者: Andrea Righi (arighi GitHub)
- 本番環境への対応状況
タスクと CPU の局所性を保つことに最適化された軽量スケジューラです。
システムが飽和していないとき、ローカルの DSQ を使ってタスクを同一 CPU にキープすることを優先します。これにより局所性を保つだけでなく、共有 DSQ と比べてロック競合を減らし、多数の CPU 間での優れたスケーラビリティが実現できます。
- 用途
- 汎用スケジューラ: サーバー用途とデスクトップ用途の両方に向いています。
スケジューラモード
Section titled “スケジューラモード”- コマンドラインフラグ: なし
- 説明:
- コマンドラインフラグ:
-s 700 -S - 説明: 共有 SMT コアにおける競合を減らすことで、スループットを代償にゲームパフォーマンスの安定性を向上させます。
- コマンドラインフラグ:
-m powersave - 説明: 効率の低いコア (Intel の E コアなど) を利用して電力効率を優先します。
- コマンドラインフラグ:
-s 700 -S -m performance -w - 説明: スループットを代償に遅延を削減します。オーディオ処理やマルチメディアなどのソフトリアルタイムアプリケーションに適しています。効率を代償に、利用可能なコア全体でより均一に負荷を分散させます。
- コマンドラインフラグ:
-s 20000 -c 75 -p 250 - 説明: アドレス空間アフィニティを有効にしてキャッシュが重要な処理での局所性とパフォーマンスを改善します。スライス期間を 20ms に設定し、またシステムがビジー状態かどうかを判断するために、スケジューラが CPU 使用率と特定のしきい値を比較するポーリングを行います。
開発者: Andrea Righi (arighi GitHub)
本番環境への対応状況
タスク間の公平性とパフォーマンスの予測可能性の確保に重点をおいたスケジューラです。
各タスクに「レイテンシウェイト」を割り当てるEarliest Deadline First (EDF) ポリシーで動作します。このウェイトはタスクがタイムスライスを使い切る前に CPU を解放する頻度に基づいて動的に調整されます。
CPU を早めに解放するタスクにはより高いレイテンシウェイトが与えられ、タイムスライスを完全に消費するタスクよりも優先されるようになります。
- 用途
- ゲーム
- マルチメディアやリアルタイムオーディオ処理などの低遅延が重要な処理
- 高負荷状態での応答性の確保
- パフォーマンスの一貫性
- サーバー
スケジューラモード
Section titled “スケジューラモード”- コマンドラインフラグ:
-m performance -w -C 0 - 説明: スループットを代償に遅延を削減します。オーディオ処理やマルチメディアなどのソフトリアルタイムアプリケーションに適しています。
- コマンドラインフラグ:
-m all - 説明: ゲームでの高パフォーマンスを目指して最適化します。
- コマンドラインフラグ:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - 説明: 電力効率を優先します。効率の低いコア (Intel の E コアなど) を優先し、10ms ごとに強制アイドルサイクルを導入して省電力を向上させます。
- コマンドラインフラグ:
-m all -s 20000 -S 1000 -I -1 -D -L - 説明: サーバー用途向けにチューニングされています。応答性よりもスループットを優先します。
開発者: Galih Tama (galpt GitHub)
本番環境への対応状況
scx_flow はバジェット (予算) をベースにしたスケジューラで、残りバジェットの量に応じて、4つの O(1) FIFO ティアでタスクを分別します。ヒューリスティクスやスコアリングアルゴリズム、適応的なチューニングも使用せず、残りバジェットのみを判断材料とします。
- 用途
- 一般的なデスクトップやワークステーションでのマルチタスク
- バックグラウンドアプリを開いたままでゲーム
- ビルドやテスト、コンテナを動かしながらの開発作業
- さまざまな処理を一度に行うときでも応答性が重要なとき
- 決定論的で説明可能なスケジューリングが必要なシステム (組み込み制御、ロボティクス、航空電子機器など)
「バジェット」の仕組み
Section titled “「バジェット」の仕組み”すべてのタスクには「応答性バジェット」があると考えてください。タスクがスリープ中 (何もすることがなく待機している間) はバジェットが蓄積され、また起床して実行されるとバジェットを消費します。起床時にまだバジェットが残っているタスクに対しては応答性が重要だとみなし、ティアシステムを完全にスキップして、直前に実行していた CPU へ即座にディスパッチされます。バジェットを使い切ったタスクは、4 つの FIFO ティアのいずれかに再エンキューされます。
4 つのディスパッチティア
Section titled “4 つのディスパッチティア”タスクが起床ではなく再エンキューされる際は、残りバジェットの量によってどのティアに入るかが決まります。
| ティア | バジェットのしきい値 | タスクの例 |
|---|---|---|
| Priority | 1.5ms 以上 | よくスリープし、短時間だけ動くインタラクティブなタスク |
| Normal | 1ms 以上 | バジェットがある程度残っている一般的なタスク |
| Low | 0.5ms 以上 | バジェットが少なくなってきたタスク |
| Deficit | 0.5ms 未満 | バルクワーカーや CPU を消費するタスク、バックグラウンドジョブ |
それぞれのティアは単純な FIFO キューであり、エンキューもデキューも O(1) で行われます。木構造の走査や優先度の再計算は発生しません。
スタベーションも優先順位の逆転も発生しない
Section titled “スタベーションも優先順位の逆転も発生しない”ディスパッチ関数は毎回 Priority ティアから優先的に処理するわけではなく、呼び出しごとに開始ティアをローテーションさせており、gen & 3 によって開始位置が決まります。これにより Deficit ティアは最大 3 回のディスパッチサイクル以内に必ず優先的に処理されるようになります。つまり、インタラクティブな負荷が高い状況でも大量で高負荷の処理を進めることができ、特定のティアが CPU を独占することがないため優先順位の逆転が起こることもありません。
起床時は列をスキップ
Section titled “起床時は列をスキップ”タスクが起床する (スリープしていて、やるべきことができた) 際は、どのティアのキューにも並ばず SCX_DSQ_LOCAL_ON を使って、直前に実行していた CPU へ直接送られます。つまり、キャッシュが温まった状態で即座に処理されます。これがインタラクティブなタスクの応答性を保つ仕組みで、スリープしていた Discord やブラウザのタブはバジェットを持った状態で起床し、ミリ秒ではなくマイクロ秒単位でディスパッチされます。
ピン留めされたタスクは常に最優先
Section titled “ピン留めされたタスクは常に最優先”setaffinity された CPU 間を移動できないタスクは、それ専用にティアシステムよりも絶対的な優先度を持つ CPU ごとの FIFO キューが割り当てられます。指定された CPU 上では、ティアシステムによるどのタスクよりも先にディスパッチされます。
応答性が重要なタスク (キーボード入力、UI の更新、オーディオスレッド、ネットワークのポーリングなど) はほぼ常にバジェットを持った状態で起床し、専用の高速レーンを使います。CPU を多く使うバッチ処理 (コンパイル、ダウンロード、バックグラウンドのインデックス作成など) はバジェットを使い切って Deficit ティアに落ち着くものの、ローテーションするディスパッチのおかげで処理を進めることができます。チューニングは一切不要です。
プロファイル、自動調整、モードの設定も不要
Section titled “プロファイル、自動調整、モードの設定も不要”scx_flow には Gaming, Power Save, Low Latency といったモードはありません。また以前のバージョンと違い、適応的な制御ループもありせん。ローテーションするティアディスパッチとバジェットのしきい値はコンパイル時の定数になっているため、動作はあらかじめ決まっており、決定論的で説明可能で、どのシステムでも同じ挙動になります。バジェットがあれば優先され、なければ Deficit ティアを公平に分け合います。たったこれだけのシンプルなルールで動作しています。
Web UI
Section titled “Web UI”scx_flow が起動すると、自動的に http://localhost:50005 でライブ統計画面が用意されます。特別なフラグを指定する必要はなく、お好きなブラウザでそのまま開くことができます。
ダッシュボードに表示される内容は以下のとおりです。
- 各ティア (Priority / Normal / Low / Deficit) を通過したディスパッチの数
- 実行中のタスク数、稼働時間、ディスパッチ総数などのシステム情報
- インタラクティブな処理とバルク処理のどちらが優勢かを表すわかりやすいティア分布バー
- メトリクスカードをクリックしてスパークラインと棒グラフ付きの履歴画面を表示
- すべての値は 1 秒ごとのポーリングで更新されるため再読み込み不要
ページが読み込まれない場合、スケジューラが停止している可能性があります。(その場合、カーネルは組み込みの EEVDF にフォールバックします)
# Web UI を使わない場合は以下で無効化できますsudo scx_flow --no-webuiscx_loader がソケットファミリーを制限する systemd ハードニング (RestrictAddressFamilies, SocketBindDeny) 付きで実行されている場合、TCP のバインドはブロックされ、scx_flow は /tmp/scx_flow.sock の Unix ソケットにフォールバックされるため、直接ブラウザからダッシュボードにアクセスすることができなくなります。UI が不要であれば一時的に sudo scx_flow --no-webui を実行してエラーを減らすことができます。
CLI 引数
Section titled “CLI 引数”| 引数 | 説明 |
|---|---|
--no-webui |
組み込みの Web UI を無効化 |
-d, --debug |
デバッグレベルのログを有効化 |
-V, --version |
スケジューラのバージョンを表示して終了 |
開発者: Changwoo Min (multics69 GitHub)
- 本番環境への対応状況
Changwoo による LAVD の簡単な紹介
LAVD はまだ開発中の新しいスケジューリングアルゴリズムです。レイテンシが重要で通信量の多いゲーム用途を考えて開発しています。タスク間の CPU 時間の公平性と全体的に優れたスループットを保ちながら、レイテンシスパイクを削減することを目指しています。
- 用途
- ゲーム
- オーディオ制作
- 低遅延が重要な用途
- デスクトップ用途
- 高負荷な処理中でも優れた応答性
- 省電力
LAVD の主な素晴らしい機能のひとつがコアコンパクションです。ざっくり説明すると、CPU 使用率が50%未満の場合、現在アクティブなコアがより長時間、より高い周波数で動作します。一方、アイドルコアは C ステート (スリープ) をより長時間キープして、全体的な消費電力を大幅に削減します。
スケジューラモード
Section titled “スケジューラモード”ゲーム & 低遅延
Section titled “ゲーム & 低遅延”- コマンドラインフラグ:
--performance - 説明: 物理コアを優先して利用可能なすべてのコアを使用することでパフォーマンスを最大化します。
- コマンドラインフラグ:
--powersave - 説明: 合理的なパフォーマンスを保ちながら消費電力を最小化します。物理コアよりも、効率的なコアとスレッドを優先します。
開発者: Will Clingan (willclngn GitHub)
トポロジーを意識した配置を行う、振る舞い分類型のスケジューラです。EWMA (指数移動平均) によるスコアリング (起床頻度、コンテキストスイッチ率、実行時間の分散) に基づいて、タスクを LAT_CRITICAL, INTERACTIVE, BATCH という3つのティアに振り分けます。各ティアはそれぞれ独自のスライス、プリエンプションルール、DSQ ルーティングを持ちます。
順位付けは、ラプラシアン疑似逆行列から計算される CPU トポロジーグラフ上の実効抵抗 (R_eff) によって決まります。CPU ごとの DSQ は R_eff の順にワークスティールされ、キャッシュが温まっている処理は温かい状態のままそのまま保てるようになっています。
sojourn rescue (滞留救済)、CoDel ターゲット、vtime の上限、longrun のしきい値といった、すべてのタイミング定数は単一の tau 値 (フィードラー固有値の逆数) から計算されます。そのため、2コアのノート PC でも32コア以上のサーバーでも、チューニングなしでスケジューラが自己調整します。減衰調和振動子が、ティックごとに rescue pressure (救済圧力) に応じて CoDel のストールターゲットを適応的に調整します。
1Hz で動作する Rust 製の適応制御ループ (6つのエキスパートプロファイルに対する乗法重み更新) が、BPF のヒストグラムテレメトリに基づいてスケジューリングのパラメータを調整します。二重補正を避けるため、BPF 側の振動子の状態と同期しています。永続的なプロセスデータベースが、再起動をまたいでタスクの分類を学習します。また NUMA を意識した設計で、ホットプラグにも適切に対応します。
- 用途
- ゲーム
- デスクトップ用途
- マルチメディア/オーディオ制作
- コードベースのコンパイル
- ZFS / ストレージに負荷がかかる処理
- さまざまな処理を一度に行うとき
- 高負荷な処理中でも優れた応答性
スケジューラモード
Section titled “スケジューラモード”デフォルト (適応)
- コマンドラインフラグ: なし (デフォルトは適応モードで動作)
- 説明: 完全適応モードです。Rust 制御ループがワークロード体制 (LIGHT / MIXED / HEAVY) を検出してスケジューリングパラメーターをリアルタイムで調整します。一般的なデスクトップ用途とゲームに最適です。
BPF のみ
Section titled “BPF のみ”- コマンドラインフラグ:
--no-adaptive - 説明: Rust 適応制御ループを無効にします。BPF スケジューラは静的なチューニング度で動作します。オーバーヘッドが低く、ベンチマークや適応レイヤーが処理内容を過剰補正している場合に有用です。
診断 / デバッグ
Section titled “診断 / デバッグ”- コマンドラインフラグ:
-vまたは--verbose - 説明: 層ごとのディスパッチ数、ソジョーン時間、動作分類統計を含む詳細なテレメトリ出力を有効にします。スケジューリング動作の診断に役立ちます。
- 本番環境への対応状況
- 特定の用途とハードウェアに合わせて正しくチューニングされていることが前提となっています。
開発者: Daniel Hodges (hodgesds GitHub)
LLC 間のピックツー負荷分散に重点を置いた汎用スケジューラです。合理的なレイテンシを保ちながら高いキャッシュ局所性と*ワークコンサーブ性を保ちます。
*訳注: ワークコンサーブ性 (work conservation) … 直訳すると「仕事量保存」。手が空いている CPU がいるなら、待たせている仕事を即座に割り当てるという意味です。- 用途
- サーバー
- デスクトップ環境
- ゲーム (手動チューニングが必要)
スケジューラモード
Section titled “スケジューラモード”- コマンドラインフラグ:
--task-slice true -f --sched-mode performance - 説明: ゲームパフォーマンスの一貫性を向上させ、より高いパフォーマンスのコアへのスケジューリングバイアスを強化します。
- コマンドラインフラグ:
-y -f --task-slice true - 説明: 応答性が重要な処理を割り当てられた CPU に固定させ、スライスタイムの安定性を向上させることで遅延を削減します。
- コマンドラインフラグ:
--sched-mode efficiency - 説明: 電力効率の高いコアを優先することで電力効率を向上させます。
- コマンドラインフラグ:
--keep-running - 説明: CPU がアイドルの場合にタスクがスライスを超えて実行できるようにすることで、サーバー用途の処理を改善します。
開発者: Andrea Righi (arighi Github)
- 本番環境への対応状況
- このスケジューラはまだ実験的であり、本番環境での使用はおすすめしません。
scx_tickless はクラウドコンピューティング、仮想化、高性能コンピューティングワークロード向けのサーバー向けスケジューラです。
スケジューラはすべてのスケジューリングイベントをこれらのイベントを処理するためのプライマリ CPU プールを通じてルーティングすることで動作します。これにより他の CPU でスケジューラのティックを無効にでき、OS ノイズを削減します。
- 用途
- クラウドコンピューティング
- 仮想化
- 高性能コンピューティングワークロード
- サーバー
スケジューラモード
Section titled “スケジューラモード”- コマンドラインフラグ:
-f 5000 -s 5000 - 説明: スケジューラが CPU 競合を検出する頻度を上げてより短いタイムスライスでコンテキストスイッチを起こすことで、ゲームでのパフォーマンスを向上させます。
- コマンドラインフラグ:
-f 50 - 説明: 競合チェックを下げることで電力効率を向上させます。
- コマンドラインフラグ:
-f 5000 -s 1000 - 説明: ゲームプロファイルと同様ですが、スライスをさらに短くしています。
- コマンドラインフラグ:
-f 100 - 説明: スケジューラが CPU 競合を確認する頻度を下げ、応答性を代償にスループットを向上させます。
開発者: Andrea Righi (arighi GitHub)
本番環境への対応状況
パフォーマンスが重要な本番環境では、すべてのスケジューリング判断をユーザー空間に任せることによるコストが多少あるため、ほかのスケジューラの方がパフォーマンスが良いことが多いです。
一方で、完全にユーザー空間で実装されたスケジューラは高度なライブラリ、トレースツール、外部サービス (AI など) との統合の可能性を秘めています。
そのため場合によってはメリットがオーバーヘッドを上回り、本番環境での使用が正当化される可能性もあります。
bpfland との類似点があります。ユーザー空間での実装により、読みやすく理解しやすい設計を目指して作られています。
ユーザー空間スケジューラを使用する場合、わずかにスループット面が不利であることを認識しておいてください。
- 用途
- 低遅延が重要な用途 (ゲーム、ビデオ会議、ライブ配信)
- デスクトップ
開発者: David Vernet (Byte-Lab GitHub)
- 本番環境への対応状況
- 正しくチューニングされていることが前提となっています。
Rusty は幅広い機能を提供しており、さまざまな用途に対して優れた柔軟性があります。その機能のひとつがチューナビリティで、好みや特定の要件に合わせて Rusty をカスタマイズできます。
- 用途
- ゲーム
- 低遅延が重要な用途
- デスクトップ
- マルチメディア/オーディオ制作
- 高負荷ワークロード下での優れた応答性
- 省電力
設定とパフォーマンステスト
Section titled “設定とパフォーマンステスト”LAVD オートパイロット & オートパワー
Section titled “LAVD オートパイロット & オートパワー”Changwoo Min より引用
-
オートパイロットモードでは、スケジューラはシステム負荷、具体的には CPU 使用率に基づいて
Powersave, Balanced, Performanceの電源モードを調整します。 -
オートパワー: システムのエネルギープロファイル (EPP: Energy Performance Preference) に基づいてスケジューラの電源モードを自動的に決定します。
# オートパワーは以下のフラグで有効にできます--autopower# 例scx_lavd --autopowerananicy-cpp と sched-ext
Section titled “ananicy-cpp と sched-ext”ananicy-cpp を無効化・停止するには以下のコマンドを実行してください。
systemctl disable --now ananicy-cppscx_loader 電源プロファイル切り替え
Section titled “scx_loader 電源プロファイル切り替え”CachyOS が提供する power-profiles-daemon パッケージに実装されており、scx_loader の電源プロファイル切り替えをサポートするカスタムパッチが適用されています。
scx_loaderが現在実行中の場合、game-performance を使用するとゲーム起動時に自動的にアクティブなスケジューラがゲームプロファイルに切り替わり、ゲーム終了時にデフォルトプロファイルに戻ります。- KDE Plasma や GNOME の電源プロファイルスイッチャーなどで電源プロファイルを変更すると、
scx_loaderが自動的に対応するスケジューラプロファイルに切り替えます。
| 電源プロファイル | スケジューラプロファイル |
|---|---|
| 省電力 | 省電力 |
| バランス | 自動 |
| パフォーマンス | ゲーム |
cachyos-benchmarker でスケジューラをベンチマーク・比較する
Section titled “cachyos-benchmarker でスケジューラをベンチマーク・比較する”cachyos-benchmarker ツールは異なる CPU スケジューラのパフォーマンスを評価・比較するかんたんな方法です。
さまざまな用途や処理内容のもとで CPU、メモリ、システム全体のパフォーマンスを測定する包括的なベンチマークスイートを実行できます。
内蔵ベンチマーク
| テスト | 測定内容 | ツール |
|---|---|---|
| stress-ng cpu-cache-mem | CPU、キャッシュ、メモリのパフォーマンス | stress-ng |
| FFmpeg コンパイル | 並列ビルドパフォーマンス | make |
| x265 エンコード | 動画エンコードのスループット | x265 |
| argon2 ハッシュ | マルチスレッドパスワードハッシュ | argon2 |
| perf sched msg | コンテキストスイッチと IPC パフォーマンス | perf |
| perf memcpy | メモリスループット memcpy() |
perf |
| 素数計算 | 整数演算と並列処理 | primesieve |
| NAMD | 分子動力学 (科学的ワークロード) | namd3 |
| Blender レンダリング | CPU のみの 3D レンダリング | blender |
| xz 圧縮 | 圧縮スループット | xz |
| カーネル defconfig ビルド | カーネルコンパイルパフォーマンス | make |
| y-cruncher | 数学的精度とメモリストレス | y-cruncher |
cachyos-benchmarker はさまざまな目的で使えます。
- スケジューラの安定性テスト
スケジューラの変更によるフリーズ、クラッシュ、リグレッションを検出するためにフルベンチマークスイートを実行できます。
scx_loaderを使用している場合、フリーズやクラッシュ時のログを以下のコマンドで収集できます。これにより現在のディレクトリにTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logという名前のファイルが作成されます。 - スケジューラパフォーマンスの比較
- スケジューラ間のパフォーマンスの差を評価できます。(例:
BPFLAND vs LAVD)
- スケジューラ間のパフォーマンスの差を評価できます。(例:
- カーネルやスケジューラのアップデートによる影響の測定
- パッチやバージョン変更の前後を比較してパフォーマンスのリグレッションや改善を確認できます。
- 設定チューニングのテスト
- CPU ガバナーの設定、SMT の切り替え、スケジューラフラグの変更などによる影響を評価できます。
- RAM 4 GB 以上
- 空きストレージ 8 GB 以上
- 時間と忍耐 — 遅いシステムでは、フルベンチマークは1時間以上かかることがあります
インストール
Section titled “インストール”cachyos-benchmarker をインストールするには以下のコマンドを実行してください。
sudo pacman -S cachyos-benchmarkerベンチマークの実行
Section titled “ベンチマークの実行”cachyos-benchmarkerを実行してください。Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# ~/cachyos-benchmarker/ を任意のログ保存ディレクトリに置き換えることができます。- 準備作業が完了するまでお待ちください。
- プロンプトにしたがってください。
Do you want to drop page cache now? Root privileges needed! (y/N) y
訳: ページキャッシュを生成しますか?ルート権限が必要です。 (y/N)Please enter a name for this run, or leave empty for default:
訳: テスト名に名前を付けてください。 (空欄の場合はデフォルト名になります):
- テストが完了するまでお待ちください。
- 完了すると以下の処理が行われます。
- ベンチマーク実行の詳細情報を記録した
benchie_<n>_<DATE>.logという名前のログファイルが作成されます。- 例:
benchie_p2dq_2025-09-29-2115.log benchmark_scraper.pyスクリプトが自動実行され、HTML 形式の結果レポートが生成されます。- スクリプトの処理内容:
- 指定ディレクトリ内のすべての
benchie_*.logファイルを読み込み - ベンチマーク名、時間、スコアを抽出
- ソートまたは集約
- 読みやすい結果をターミナルに出力し、ブラウザで開ける HTML ファイルを作成
ターミナル出力例
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1同じスケジューラの2つの異なるブランチを比較したテスト結果の HTML 例
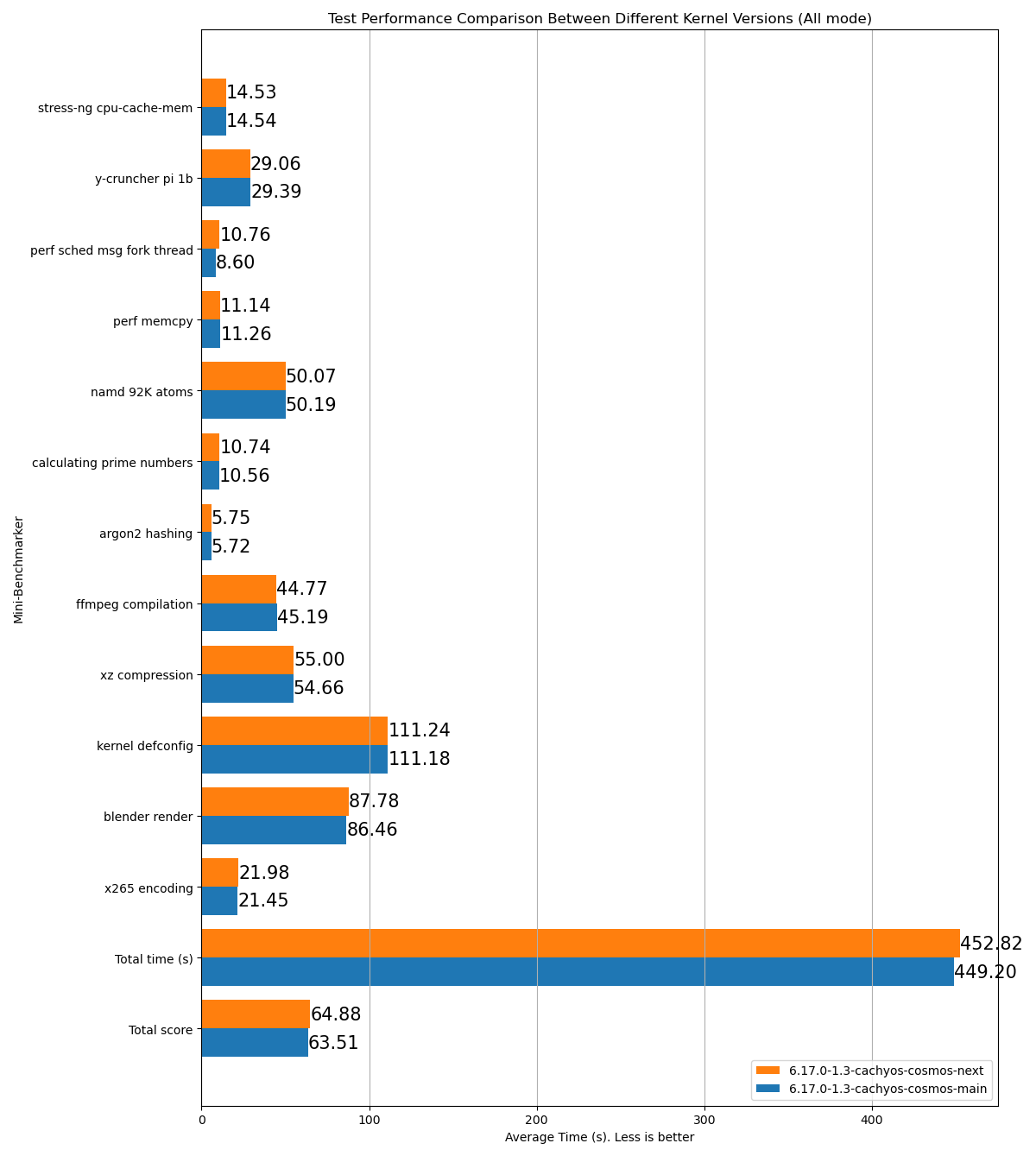
- 指定ディレクトリ内のすべての
- 例:
- ベンチマーク実行の詳細情報を記録した
- 2つ以上のベンチマークを比較するには、
benchmark_scraper.pyを実行する前に.logファイルを同じディレクトリに置いてください。ツールが自動的に検出し、HTML レポートで比較できます。
schbench でスケジューラのレイテンシをテストする
Section titled “schbench でスケジューラのレイテンシをテストする”schbench はサーバー風の処理をシミュレートしてスケジューラのレイテンシを測定するスケジューラベンチマークです。個数を指定できる「ワーカー」と「メッセージ」スレッドを生成し、メッセージスレッドが繰り返しワーカーをウェイクアップします。これらのワーカースレッドのウェイクアップから実行までのレイテンシ分布を測定することで、特に負荷下でのスレッドのウェイクアップ、バランシング、CPU 競合を処理するカーネルの能力に関する重要な調査結果を出力します。
schbench は以下の目的で使えます。
- スケジューラのレイテンシ評価: ウェイクアップ後にスレッドがどれだけ素早くスケジュールされるかを測定
- スケジューラ間のウェイクアップパフォーマンスの比較: コンテキストスイッチとウェイクアップレイテンシの改善やリグレッションを測定
- カーネルやスケジューラのパッチの影響をテストする: チューニングやアップデートがスケジューリングの公平性と応答性に影響するかどうか評価
インストール
Section titled “インストール”schbench は CachyOS リポジトリで利用できます。
sudo pacman -S schbenchベンチマークの実行
Section titled “ベンチマークの実行”通常のレイテンシテストの実行コマンド:
schbench -m 2 -t 8 -r 60この例では以下のパラメーターで実行しています。
- 2つのメッセージスレッド (
-m 2) - メッセージスレッドあたり8つのワーカースレッド (
-t 8) - 合計実行時間 60 秒 (
-r 60)
CPU コア数と希望する負荷レベルに応じてこれらの値を調整できます。
以下は主なオプションの説明です。
| オプション | 説明 |
|---|---|
-C, --calibrate |
キャリブレーションを実行してタイミングを出力 (ベンチマークなし) |
-L, --no-locking |
CPU 作業中のスピンロックを無効にする (デフォルト: ロックあり) |
-m, --message-threads <n> |
メッセージスレッド数 (デフォルト: 1) |
-t, --threads <n> |
メッセージスレッドあたりのワーカースレッド数 (デフォルト: CPU 数) |
-r, --runtime <sec> |
ベンチマーク実行時間 (デフォルト: 30) |
-F, --cache_footprint <KB> |
キャッシュフットプリントサイズ (デフォルト: 256) |
-n, --operations <count> |
実行する「思考時間」操作の数 (デフォルト: 5) |
-A, --auto-rps |
CPU 使用率ターゲットに達するまで秒あたりリクエスト数を自動的に増加させる |
-R, --rps <count> |
秒あたりリクエスト数モード |
-p, --pipe <bytes> |
パイプ転送テストをシミュレートする |
-w, --warmuptime <sec> |
統計収集前のウォームアップ時間 (デフォルト: 0) |
-i, --intervaltime <sec> |
レイテンシ出力間隔 (デフォルト: 10) |
-z, --zerotime <sec> |
レイテンシ統計をゼロにする間隔 (デフォルト: なし) |
それぞれのベンチマークの後、schbench はレイテンシの%を出力します。
出力例
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99結果の読み取り方
Section titled “結果の読み取り方”- ウェイクアップレイテンシ
- シグナル後にスレッドがどれだけ素早くウェイクアップするかを測定します。
- 低い値 (特に 99パーセンタイル) が出た場合はスケジューラの応答性が高いことを表します。
- シグナル後にスレッドがどれだけ素早くウェイクアップするかを測定します。
- リクエストレイテンシ
- スレッド間のリクエスト完了にかかる時間を表します。
- レイテンシが低ければスレッド間通信とスケジューリング効率が良いと言えます。
- スレッド間のリクエスト完了にかかる時間を表します。
- RPS (秒あたりリクエスト数)
- 実効スループットを表します。
- 平均 RPS が高ければスケジューラが指定した設定下でたくさんの作業を行えるという意味です。
- 実効スループットを表します。
まとめ
- 良いスケジューラ はウェイクアップレイテンシやリクエストレイテンシが低いことと RPS 値が一定であることが大切
- 低効率のスケジューラ を見分けるときは高いレイテンシスパイクや時間経過で不安定な RPS 値がサイン
ゲームのベンチマークに関する推奨事項
Section titled “ゲームのベンチマークに関する推奨事項”異なるスケジューラのパフォーマンスを比較するためにゲームをベンチマークしたい場合、より正確な結果を得るためのコツを一部ご紹介します。
- 組み込みベンチマークを活用しよう 多くの現代的なゲームには組み込みのベンチマークツールが含まれています。毎回同じ処理内容を実行することで一貫した結果を出すよう設計されています。
- 組み込みベンチマークを持つゲームの一覧はこちらのウェブサイトをご覧ください。
- 一貫した設定 テストを実行する際、毎回ゲームの設定 (解像度、グラフィックス品質など) が同じであることを確認してください。
- バックグラウンドアプリを閉じよう バックグラウンドで実行されているほかのアプリケーションがパフォーマンスに影響することがあります。不要なプログラムを閉じてなるべく影響しないようにしましょう。
- 組み込みベンチマークを使わない場合は、それぞれのテストで同じ操作をゲーム内で行うようにしましょう。(例: 同じ経路をたどる、戦闘状況と方法をそろえる)
- エイムが少し変わるだけでもパフォーマンス結果が異なることがあります。
- 何度もテストしよう 変動を考慮するためにベンチマークを複数回実行して平均をとりましょう。
- パフォーマンス監視ツールを活用しよう MangoHud や GOverlay などのツールは FPS、フレーム時間、CPU/GPU 使用率などのリアルタイムのパフォーマンス統計を計測できます。
- キーボードショートカットやマクロを活用しよう
- 例: ゲーム内でリアルタイムに異なるスケジューラを切り替えたりモードを変更するキーバインド
- これは scxctl などのツールや、アクティブなスケジューラとそのモードを変更するカスタムスクリプトで実現できます。
- 例: ゲーム内でリアルタイムに異なるスケジューラを切り替えたりモードを変更するキーバインド
ベンチマークの投稿と共有
Section titled “ベンチマークの投稿と共有”このウェブサイトにはコミュニティが異なるスケジューラや各種設定でテストしたベンチマークの一覧があります。
自分のベンチマークを投稿するには Discord アカウントをウェブサイトに連携する必要があります。
New benchmark ボタンをクリックして必要な情報を記入してください。
- 同じゲームで別のスケジューラや設定を使った複数の結果を投稿できます。
- MangoHud と Afterburner のログに対応しています。
- タイトルまたは説明で検索できます。
scx_loader の設定
Section titled “scx_loader の設定”デフォルトのスケジューラを設定する (起動時に自動適用)
Section titled “デフォルトのスケジューラを設定する (起動時に自動適用)”ブート時など scx_loader が開始された時点で使用するスケジューラを設定するには、以下の手順にしたがってください。
-
設定ファイルの例をコピーして設定ディレクトリにコピーしてください。
Terminal window sudo mkdir -p /etc/scx_loadersudo cp /usr/share/scx_loader/config.toml /etc/scx_loader/config.toml -
お好みのエディタで設定ファイルを編集してください。
Terminal window sudo nano /etc/scx_loader/config.toml -
デフォルトのスケジューラとモードを設定してください。以下の例では
scx_pandemoniumをAutoで設定しています。# ブート時など scx_loader が開始された時点で使用するスケジューラを指定default_sched = "scx_pandemonium"# ブート時など scx_loader が開始された時点で使用するモードを指定default_mode = "Auto" -
サービスを有効化して開始してください。
Terminal window sudo systemctl enable --now scx_loader.service
設定ファイルの優先順位
Section titled “設定ファイルの優先順位”scx_loader は以下の順番で設定ファイルを検索します。
/etc/scx_loader/config.toml(設定はここがおすすめ)/etc/scx_loader.toml/usr/share/scx_loader/config.toml(標準のテンプレート)/usr/share/scx_loader.toml
スケジューラの引数をカスタマイズ
Section titled “スケジューラの引数をカスタマイズ”設定ファイルに [scheds.scx_name] の項目を追加することで、スケジューラやモードごとに引数をカスタマイズすることができます。
詳しい情報や設定方法の例は scx_loader 設定ドキュメントをご覧ください。
scx.service から scx_loader への移行ガイド
Section titled “scx.service から scx_loader への移行ガイド”まず scx.service ファイルの構造と scx_loader 設定ファイルの構造をくらべることから始めましょう。
以前に LAVD を以下のような古い scx.service で実行していた場合…
# List of scx_schedulers: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Set custom flags for the schedulerSCX_FLAGS='--performance'scx_loader 設定ファイルでの同等の設定は以下のようになります。
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]以下のガイドにしたがって scx systemd サービス から新しい scx_loader ツールへかんたんに移行できます。
-
scx.service を無効にして scx_loader.service を有効化 systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
scx_loader の設定ファイルを作成してデフォルト構造を追加する # Micro エディターが新しいファイルを作成します。sudo micro /etc/scx_loader.toml# 以下の行を追加してください。default_sched = "scx_bpfland" # ブート時に scx_loader が起動するスケジューラに変更してくださいdefault_mode = "Auto" # 可能な値: "Auto", "Gaming", "LowLatency", "PowerSave"# CTRL + S で変更を保存し、CTRL + Q で Micro を終了してください。 -
scx_loader を再起動する systemctl restart scx_loader.service- これで、scx_loader が希望するスケジューラを読み込んで起動します。
scx_loader でのデバッグ
Section titled “scx_loader でのデバッグ”-
サービスの状態を確認する systemctl status scx_loader.service -
すべてのサービスのログエントリを表示する journalctl -u scx_loader.service -
現在のセッションのログのみを表示する journalctl -u scx_loader.service -b 0
より詳細なログを取得するには以下の手順にしたがってください。
-
サービスファイルを編集する sudo systemctl edit scx_loader.service -
[Service] セクションの下に以下の行を追加する Environment=RUST_LOG=trace -
サービスを再起動する sudo systemctl restart scx_loader.service - 再度ログを確認すると詳細なデバッグ情報を読むことができます。
よくある質問
Section titled “よくある質問”色々ありすぎる… なぜこれ一本なスケジューラを作らない?
Section titled “色々ありすぎる… なぜこれ一本なスケジューラを作らない?”主な理由は CPU スケジューリングにおいて、一本でなんでも解決する方法というのは存在しないからです。環境や用途に応じてそれぞれの要件と優先事項があるため、ある用途や処理内容に最適化されたスケジューラが別の用途や処理内容でうまく機能しないということは多々あります。
CPU スケジューラは用途に合わせた靴だと考えてください。例えばサーバー用途に最適化されたスケジューラでゲームを実行すると、パフォーマンスが下がったり、遅延が大きくなる可能性があります。一方ゲーム向けに設計されたスケジューラをサーバーで使用すると、非効率なリソースの利用とスループットの低下につながる可能性があります。
ここで sched-ext の魔法です。制約というのはもはや問題になりません。
なぜ○○スケジューラがほかよりもパフォーマンスが悪い?
Section titled “なぜ○○スケジューラがほかよりもパフォーマンスが悪い?”- 比較するときには多くの条件を考慮する必要があります。例えば、タスクのウェイトをどのように測定するのか、応答性が求められるタスクをそうでないタスクより優先するのか… 最終的に、この点はスケジューラそれぞれの設計の趣旨に左右されます。
○○の場合には✕✕スケジューラが最適だと言われているのに、なぜ自分の環境ではうまくいかない?
Section titled “○○の場合には✕✕スケジューラが最適だと言われているのに、なぜ自分の環境ではうまくいかない?”- ひとつ前の回答と同じく、CPU の種類とコアレイアウト、コア間でキャッシュを共有する方法などの設計が、スケジューラの効率の低下につながることがあります。
- だからこそ、いろいろためせるのが sched-ext フレームワークの魅力のひとつです。怖がらずにいろいろためしてみて、自分に合うものを見つけましょう。
例: FPS の安定性、最大パフォーマンス、高負荷処理での応答性など
スケジューラの用途がかなり似ていることがあるのはなぜ?
Section titled “スケジューラの用途がかなり似ていることがあるのはなぜ?”主にこれらが多目的スケジューラだからです。すべての分野で優れているわけではなくても、さまざまな用途に対応できます。
- どう自分にぴったりのスケジューラを決めるのかと言っても、実際に試してみようという以外に言えることはありません。
一部のユーザーが CachyOS Discord でテストしているスケジューラが見当たない
Section titled “一部のユーザーが CachyOS Discord でテストしているスケジューラが見当たない”scx-scheds-git という名前の scx-scheds パッケージの最新版を使っていることを確認してください。
- その理由のひとつとして、そのスケジューラがまだ開発されたばかりでユーザーによってテスト中であるため、まだ
scx-scheds-gitパッケージに追加されていない可能性があります。
スケジューラが突然クラッシュした。不安定なのか?
Section titled “スケジューラが突然クラッシュした。不安定なのか?”- 以下の理由が考えられます。
以前カーネルマネージャーの GUI で scx_loader を使用していたが、移行手順は必要?
Section titled “以前カーネルマネージャーの GUI で scx_loader を使用していたが、移行手順は必要?”- カーネルマネージャーがすでに移行プロセスを処理しているため、不要です。
- ただし
/etc/default/scxにカスタムフラグを追加しており、引き続き使用したい場合を除きます。
- ただし
- Sched_ext YouTube 再生リスト
- LWN: The extensible scheduler class (2023年2月)
- arighi のブログ: Implement your own kernel CPU scheduler in Ubuntu with sched_ext (2023年7月)
- David Vernet の講演: Kernel Recipes 2023 - sched_ext: pluggable scheduling in the Linux kernel (2023年9月)
- Changwoo のブログ: sched_ext: a BPF-extensible scheduler class (Part 1) (2023年12月)
- arighi のブログ: Getting started with sched_ext development (2024年4月)
- Changwoo のブログ: sched_ext: scheduler architecture and interfaces (Part 2) (2024年6月)
- arighi の YouTube チャンネル: scx_bpfland Linux scheduler demo: topology awareness (2024年8月)
- David Vernet の講演: Kernel Recipes 2024 - Scheduling with superpowers: Using sched_ext to get big perf gains (2024年9月)