Tutorial sched-ext
A Extensible Scheduler Class (mais conhecida como sched-ext) é uma funcionalidade do kernel Linux que permite a implementação de escalonadores de threads do kernel em BPF (Berkeley Package Filter) e o seu carregamento dinâmico. Essencialmente, isto permite que os utilizadores finais alterem os seus escalonadores em userspace sem a necessidade de compilar outro kernel apenas para ter um escalonador diferente.
-
Os escalonadores podem ser encontrados nos pacotes
scx-schedsescx-scheds-git.Terminal window # Ramo estável + ferramentas scx_loader e scxctl.sudo pacman -S scx-scheds scx-tools# Ramo de desenvolvimento (Este ramo inclui as alterações mais recentes do ramo master) + ferramentas scx_loader e scxctl.sudo pacman -S scx-scheds-git scx-tools-git
Como Iniciar e Gerir o Escalonador
Seção intitulada “Como Iniciar e Gerir o Escalonador”- Para iniciar o escalonador, abra o seu terminal e introduza o seguinte comando:
Exemplo de como iniciar o rusty sudo scx_rusty
Isto irá iniciar o escalonador rusty e desativar o escalonador predefinido.
Para parar o escalonador. Prima CTRL + C e o escalonador será então interrompido e o escalonador predefinido do kernel assumirá o controlo novamente.
O scxctl é um cliente CLI DBUS para interagir com o scx_loader.
- Funcionalidades:
- Obter o escalonador e o modo atuais
- Listar todos os escalonadores disponíveis
- Iniciar um escalonador num determinado modo, ou com determinados argumentos
- Alternar entre escalonadores e modos
- Parar o escalonador em execução
- Reiniciar o escalonador em execução
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUso: scxctl <COMANDO>
Comandos: get Obter informações sobre o escalonador em execução list Listar todos os escalonadores suportados start Iniciar um escalonador num modo ou com argumentos switch Alternar entre escalonadores ou modos, opcionalmente com argumentos stop Parar o escalonador atual restart Reiniciar o escalonador atual com a configuração original restore Restaurar o escalonador predefinido a partir da configuração help Imprimir esta mensagem ou a ajuda do(s) subcomando(s) indicado(s)
Opções: -h, --help Imprimir a ajuda -V, --version Imprimir a versãoComo o nome indica, é um utilitário que funciona como um carregador e gestor para a framework sched-ext utilizando a interface D-Bus.
Embora não requeira o systemd, este pode ainda assim ser utilizado em conjunto com ele. Consulte o guia de transição para referência.
- Tem a capacidade de parar, iniciar, reiniciar, ler informações sobre um escalonador scx e muito mais.
- Pode utilizar ferramentas como o
dbus-sendou ogdbuspara comunicar com ele.
- Pode utilizar ferramentas como o
- Este guia explica como utilizar o scx_loader com o comando dbus-send.
-
Iniciar o scx_rusty com os seus argumentos predefinidos dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Iniciar um escalonador com argumentos # Este exemplo inicia o scx_bpfland com as seguintes flags: -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Parar o escalonador atualmente em execução dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Alternar para o escalonador predefinido # O scx_loader irá alternar para o escalonador predefinido definido no ficheiro de configuração do scx_loaderdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Alternar para outro escalonador no Modo 2 dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# Isto alterna para o scx_lavd com o modo de escalonador 2, o que significa que inicia o LAVD em modo de poupança de energia (powersaving) -
Alternar para outro escalonador com argumentos dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Obter o escalonador atualmente em execução dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Obter uma lista dos escalonadores suportados dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Pode aceder e configurá-los através do botão sched-ext scheduler config.
O SCX Manager é uma ferramenta GUI (interface gráfica) independente derivada do CachyOS Kernel Manager. Permite aos utilizadores gerir a framework sched-ext e os seus escalonadores através do scx_loader.
Funcionalidades:
- Verificar qual o escalonador atualmente ativo
- Selecionar um escalonador ou perfil: (Auto, Gaming, Poupança de energia, Baixa Latência ou Servidor)
- Definir flags adicionais
- Desativar o escalonador atual
Captura de ecrã

Guia do Escalonador: Perfis e Casos de Uso
Seção intitulada “Guia do Escalonador: Perfis e Casos de Uso”Como existem muitos escalonadores por onde escolher, queremos dar uma pequena introdução sobre os escalonadores disponíveis.
Sinta-se à vontade para reportar qualquer problema ou feedback no repositório do respetivo escalonador.
Utilize scx_nome_do_escalonador --help para ver as flags disponíveis e uma breve descrição do que fazem.
scx_rusty --helpDesenvolvido por: Andrea Righi (arighi GitHub)
Pronto para Produção?
O scx_beerland é um escalonador desenhado para priorizar a localidade e a escalabilidade.
Prioriza manter as tarefas no mesmo CPU para preservar a localidade da cache, garantindo ao mesmo tempo uma boa escalabilidade em sistemas com muitos CPUs através do uso de DSQs locais (filas de execução por CPU) quando o sistema não está saturado.
- Casos de uso:
- Cargas de trabalho intensivas em cache
- Sistemas com um grande número de CPUs
- Gaming: Conhecido por funcionar surpreendentemente bem em certos jogos, embora os resultados possam variar
- Servidor: Bom para cargas gerais devido às otimizações de escalabilidade e localidade.
- Também pode ser usado para uso diário em desktop.
Modos do Escalonador
Seção intitulada “Modos do Escalonador”Nenhum de momento.
Desenvolvido por: Andrea Righi (arighi GitHub)
Pronto para Produção?
Um escalonador sched_ext baseado em vruntime que prioriza cargas de trabalho interativas. Altamente flexível e fácil de adaptar.
Ao decidir quais núcleos usar, o Bpfland leva em consideração o layout da cache e quais núcleos partilham a mesma cache L2/L3, resultando em menos falhas de cache (cache misses) e, consequentemente, mais desempenho.
- Casos de uso:
- Gaming
- Uso de desktop
- Produção multimédia/áudio
- Excelente interatividade sob cargas de trabalho intensivas
- Poupança de energia
- Servidor
Modos do Escalonador
Seção intitulada “Modos do Escalonador”Baixa Latência (Low Latency)
Seção intitulada “Baixa Latência (Low Latency)”- Flags de Linha de Comando:
-m performance -w - Descrição: Destinado a reduzir a latência à custa do rendimento (throughput). Adequado para aplicações de tempo real suave (soft real-time), como processamento de áudio e multimédia.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags de Linha de Comando:
-s 20000 -m powersave -I 100 -t 100 - Descrição: Prioriza a eficiência energética. Favorece núcleos menos potentes (ex: E-cores em Intel).
Servidor (Server)
Seção intitulada “Servidor (Server)”- Flags de Linha de Comando:
-s 20000 -S - Descrição: Prioriza tarefas com afinidade estrita. Esta opção pode aumentar o rendimento à custa da latência, sendo mais adequada para cargas de trabalho de servidor.
Desenvolvido por: RitzDaCat (RitzDaCat GitHub)
- Pronto para Produção?
O scx_cake é um escalonador de CPU BPF experimental que adapta o algoritmo DRR++ (Deficit Round Robin++) do CAKE de rede para o escalonamento de CPU.
- Classificação de 4 Níveis — Tarefas ordenadas por avg_runtime EWMA em Crítico / Interativo / Frame / Bulk
- Zero Atómicos Globais — Arrays BSS por CPU com escritas protegidas por MESI eliminam o bloqueio de barramento (bus locking)
- Seleção de Ociosidade Delegada pelo Kernel — scx_bpf_select_cpu_dfl() para uma seleção de CPU autoritária e sem latência
- Particionamento DSQ por LLC — Elimina a contenção de bloqueio entre CCDs em CPUs multi-chiplet
- Rastreio de Défice DRR++ — Algoritmo de equidade de fluxo do CAKE de rede adaptado para o escalonamento de tarefas de CPU
Concebido para cargas de trabalho de jogos em hardware AMD e Intel moderno.
- Casos de uso:
- Jogos
Sistema de 4 Níveis
Seção intitulada “Sistema de 4 Níveis”O scx_cake classifica cada tarefa num de quatro níveis com base no seu runtime EWMA (Média Móvel Ponderada Exponencial). A classificação é automática e contínua — as tarefas movem-se entre níveis à medida que o seu comportamento muda.
Portões de Nível
Seção intitulada “Portões de Nível”| Nível | Nome | avg_runtime | Carga de Trabalho Típica | Quantum | Inanição (Starvation) |
|---|---|---|---|---|---|
| T0 | Crítico | < 100µs | Handlers de IRQ, drivers de input, áudio (PipeWire), rede | 0.5ms | 3ms |
| T1 | Interativo | < 2ms | Compositores, física de jogos, IA de jogos, workers curtos | 2.0ms | 8ms |
| T2 | Frame | < 8ms | Threads de renderização de jogos, codificação de vídeo | 4.0ms | 40ms |
| T3 | Bulk | ≥ 8ms | Compilação, indexação em fundo, trabalhos em lote | 8.0ms | 100ms |
[!TIP] Nenhuma tarefa de jogo deve estar em T3. As threads de renderização de jogos correm 2-8ms por frame → T2. Física/IA correm 0.5-2ms → T1. Handlers de input correm < 100µs → T0. Apenas tarefas a realizar 8ms+ de trabalho contínuo de CPU (compilação de shaders, ecrãs de carregamento) vão para T3.
Como funciona a Classificação
Seção intitulada “Como funciona a Classificação”- Posicionamento inicial: Com base no valor
nice—nice < 0→ T0,nice 0-10→ T1,nice > 10→ T3 - Autoridade de runtime: Após ~3 paragens, o avg_runtime EWMA torna-se autoritário. Uma tarefa com nice -5 que corra em picos de 50ms será reclassificada para T3 independentemente do valor nice.
- Histerese: Uma zona morta de 10% evita oscilações nos limites dos níveis. A promoção requer um avg_runtime claramente abaixo do limite; a despromoção é imediata.
- Backoff graduado: Uma vez que um nível está estável durante 3+ paragens consecutivas, a frequência de reclassificação diminui por nível: T0 verifica novamente a cada 1024ª paragem, T3 a cada 16ª. A instabilidade repõe a verificação para a frequência total.
Rastreio de Défice DRR++
Seção intitulada “Rastreio de Défice DRR++”Adaptado da equidade de fluxo do CAKE de rede:
- Cada tarefa começa com um défice (quantum + bónus de novo fluxo ≈ 10ms de crédito)
- Cada ciclo de execução consome défice proporcional ao runtime
- Quando o défice esgota → bónus de novo fluxo é removido → a tarefa compete normalmente
- Isto confere às threads recém-criadas (um jogo a lançar um worker) uma capacidade de resposta instantânea que decai naturalmente
DVFS (Escalonamento de Frequência de CPU)
Seção intitulada “DVFS (Escalonamento de Frequência de CPU)”Cada nível mapeia para um alvo de desempenho de CPU através de uma tabela de pesquisa RODATA:
| Nível | Alvo | Justificação |
|---|---|---|
| T0-T2 | 100% (frequência máx) | Cargas de jogo precisam de desempenho total |
| T3 | 75% | Trabalho em fundo pode correr mais devagar para poupar energia |
Em CPUs híbridos Intel (has_hybrid = true), os alvos são ajustados pela cpuperf_cap de cada núcleo para evitar pedir frequência excessiva em E-cores.
Perfis (--profile, -p)
Seção intitulada “Perfis (--profile, -p)”| Perfil | Quantum | Inanição | Caso de Uso |
|---|---|---|---|
| gaming | 2ms | 100ms | (Predefinido) Equilibrado para a maioria dos jogos |
| esports | 1ms | 50ms | FPS competitivo, latência ultra-baixa |
| legacy | 4ms | 200ms | CPUs antigos, poupança de bateria |
| default | 2ms | 100ms | Alias para gaming |
Argumentos CLI
Seção intitulada “Argumentos CLI”| Argumento | Predef. | Descrição |
|---|---|---|
--profile, -p <PERFIL> |
gaming |
Selecionar perfil predefinido |
--quantum <µs> |
perfil | Fatia de tempo base em microssegundos |
--new-flow-bonus <µs> |
perfil | Défice extra para tarefas recém-acordadas |
--starvation <µs> |
perfil | Tempo de execução máx antes de preempção forçada |
--verbose, -v |
false |
Ativar visualização de estatísticas TUI em tempo real |
--interval <secs> |
1 |
Intervalo de atualização da TUI |
Afinação por Nível (Perfil Gaming)
Seção intitulada “Afinação por Nível (Perfil Gaming)”| Nível | Multiplicador de Quantum | Fatia Efetiva | Limite de Inanição |
|---|---|---|---|
| T0 Crítico | 0.75x | 1.5ms | 3ms |
| T1 Interativo | 1.0x | 2.0ms | 8ms |
| T2 Frame | 1.2x | 2.4ms | 40ms |
| T3 Bulk | 1.4x | 2.8ms | 100ms |
Desenvolvido por: Andrea Righi (arighi GitHub)
Pronto para Produção?
Escalonador leve otimizado para preservar a localidade tarefa-para-CPU.
Quando o sistema não está saturado, o escalonador prioriza manter as tarefas no mesmo CPU. Isto reduz a contenção de bloqueios (locking) em comparação com filas partilhadas, permitindo uma escalabilidade excelente em muitos CPUs.
- Casos de uso:
- Escalonador de propósito geral: adapta-se tanto a cargas de servidor como de desktop.
Modos do Escalonador
Seção intitulada “Modos do Escalonador”- Flags:
-s 20000 -d -c 0 -p 0 - Descrição: Sacrifica a localidade e eficiência para uma distribuição uniforme entre todos os CPUs. Inclina-se para interatividade.
- Flags:
-c 0 -p 0 - Descrição: Desativa a monitorização de carga do CPU e força o escalonamento baseado em prazos (deadlines) para melhorar a resposta.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags:
-m powersave -d -p 5000 - Descrição: Favorece a eficiência e núcleos E-cores. Desativa despertares diferidos.
Baixa Latência (Low Latency)
Seção intitulada “Baixa Latência (Low Latency)”- Flags:
-m performance -c 0 -p 0 -w - Descrição: Foca na previsibilidade de desempenho através de otimizações de despertar síncrono.
Servidor (Server)
Seção intitulada “Servidor (Server)”- Flags:
-s 20000 - Descrição: Ativa a afinidade de espaço de endereçamento para melhorar o desempenho em cargas sensíveis à cache.
Desenvolvido por: Andrea Righi (arighi GitHub)
Pronto para Produção?
Um escalonador que se foca em garantir a justiça (fairness) entre tarefas e a previsibilidade de desempenho.
Opera utilizando uma política Earliest Deadline First (EDF), onde a cada tarefa é atribuído um peso de “latência”. Este peso é ajustado dinamicamente com base na frequência com que uma tarefa liberta o CPU antes de esgotar a sua fatia de tempo (time slice).
Tarefas que libertam o CPU cedo recebem um peso de latência maior, sendo priorizadas sobre tarefas que consomem totalmente o seu tempo de execução.
- Casos de uso:
- Gaming
- Cargas sensíveis à latência (multimédia ou áudio em tempo real)
- Necessidade de responsividade em situações de sobrecarga
- Consistência de desempenho
- Servidor
Modos do Escalonador
Seção intitulada “Modos do Escalonador”Baixa Latência (Low Latency)
Seção intitulada “Baixa Latência (Low Latency)”- Flags:
-m performance -w -C 0 - Descrição: Reduz a latência à custa do rendimento. Ideal para áudio e multimédia.
- Flags:
-m all - Descrição: Otimiza para alto desempenho em jogos.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Descrição: Prioriza a eficiência. Favorece núcleos menos potentes e introduz um ciclo de repouso forçado a cada 10ms.
Servidor (Server)
Seção intitulada “Servidor (Server)”- Flags:
-m all -s 20000 -S 1000 -I -1 -D -L - Descrição: Ajustado para servidores. Troca responsividade por rendimento bruto.
Desenvolvido por: Changwoo Min (multics69 GitHub)
Pronto para Produção?
LAVD é um novo algoritmo motivado por cargas de gaming, que são críticas em latência e pesadas em comunicação. Visa minimizar picos de latência mantendo um bom rendimento global.
- Casos de uso:
- Gaming e Produção de Áudio
- Cargas sensíveis à latência e uso de desktop
- Excelente interatividade sob carga intensa
Uma das capacidades principais é a Core Compaction (Compactação de Núcleos): Quando o uso de CPU é < 50%, os núcleos ativos correm por mais tempo e a maior frequência, enquanto os núcleos inativos permanecem em C-State (Sleep) por mais tempo, poupando energia.
Modos do Escalonador
Seção intitulada “Modos do Escalonador”Gaming & Baixa Latência
Seção intitulada “Gaming & Baixa Latência”- Flags:
--performance - Descrição: Maximiza o desempenho usando todos os núcleos disponíveis, priorizando núcleos físicos.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags:
--powersave - Descrição: Minimiza o consumo mantendo um desempenho razoável. Prioriza núcleos eficientes e threads sobre núcleos físicos.
Desenvolvido por: Will Clingan (willclngn GitHub)
Um escalonador de classificação comportamental que utiliza pontuação baseada em EWMA (frequência de wakeup, taxa de mudança de contexto, variância de tempo de execução) para organizar as tarefas em três níveis de despacho — LAT_CRITICAL, INTERACTIVE e BATCH — cada um com o seu próprio time slice, regras de preempção e encaminhamento DSQ. Um mecanismo de resgate de permanência (sojourn rescue), inspirado no CoDel, monitoriza os tempos de espera da fila batch e resgata tarefas antigas antes que bloqueiem, com limiares que se adaptam à taxa de despacho e ao número de núcleos. A deteção de rajadas dual (detetor de ponto de mudança CUSUM + contador de taxa de wakeup) lida com tempestades de forks, e um ciclo de controlo adaptativo em Rust ajusta os parâmetros de escalonamento uma vez por segundo, com base na deteção do regime de carga de trabalho e na telemetria de histogramas BPF.
Os compositores (KWin, GNOME Shell, Hyprland, Sway, entre outros) são automaticamente promovidos para LAT_CRITICAL. Uma base de dados de processos persistente memoriza as classificações das tarefas entre reinícios.
- Casos de uso:
- Jogos
- Uso de computador de secretária
- Produção multimédia/áudio
- Compilação de código
- Interatividade sob cargas de trabalho intensivas
- Cargas de trabalho mistas
Modos do Escalonador
Seção intitulada “Modos do Escalonador”Predefinido (Adaptativo)
Seção intitulada “Predefinido (Adaptativo)”- Argumentos da linha de comandos: (nenhum — corre em modo adaptativo por defeito)
- Descrição: Modo totalmente adaptativo. O ciclo de controlo em Rust deteta o regime de carga de trabalho (LIGHT / MIXED / HEAVY) e ajusta os parâmetros de escalonamento em tempo real. Ideal para uso geral em computador e jogos.
Apenas BPF
Seção intitulada “Apenas BPF”- Argumentos da linha de comandos:
--no-adaptive - Descrição: Desativa o ciclo de controlo adaptativo em Rust. O escalonador BPF funciona com parâmetros estáticos. Menor sobrecarga (overhead), útil para benchmarking ou caso a camada adaptativa esteja a corrigir excessivamente a sua carga de trabalho.
Detalhado / Depuração
Seção intitulada “Detalhado / Depuração”- Argumentos da linha de comandos:
-vou--verbose - Descrição: Ativa a saída de telemetria detalhada, incluindo contagens de despacho por nível, tempos de permanência e estatísticas de classificação comportamental. Útil para diagnosticar o comportamento do escalonamento.
Pronto para Produção?
- Sim, se ajustado ao seu hardware e carga de trabalho.
Desenvolvido por: Daniel Hodges (hodgesds GitHub)
Escalonador de propósito geral que se foca no equilíbrio de carga “escolha dois” entre LLCs. Mantém alta localidade de cache enquanto providencia latência razoável.
Modos do Escalonador
Seção intitulada “Modos do Escalonador”- Flags:
--task-slice true -f --sched-mode performance - Descrição: Melhora a consistência em jogos e favorece núcleos de alto desempenho.
Baixa Latência (Low Latency)
Seção intitulada “Baixa Latência (Low Latency)”- Flags:
-y -f --task-slice true - Descrição: Faz com que tarefas interativas “prendam” mais ao CPU original.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags:
--sched-mode efficiency - Descrição: Prioriza núcleos energeticamente eficientes.
Servidor (Server)
Seção intitulada “Servidor (Server)”- Flags:
--keep-running - Descrição: Permite que tarefas corram além da sua fatia se o CPU estiver ocioso.
Desenvolvido por: Andrea Righi (arighi Github)
Pronto para Produção?
- Este escalonador ainda é experimental e não recomendado para uso em produção.
Orientado a servidores, cloud e virtualização. Funciona enviando eventos de escalonamento através de um grupo de CPUs primários, permitindo desativar o “tick” nos outros CPUs para reduzir o ruído do SO.
Modos do Escalonador
Seção intitulada “Modos do Escalonador”- Flags:
-f 5000 -s 5000 - Descrição: Aumenta a frequência de deteção de contenção.
Poupança de Energia (Power Save)
Seção intitulada “Poupança de Energia (Power Save)”- Flags:
-f 50 - Descrição: Reduz as verificações de contenção.
Desenvolvido por: Andrea Righi (arighi GitHub)
Pronto para Produção?
Para cenários de produção críticos em termos de desempenho, outros escalonadores provavelmente exibirão melhor performance, visto que delegar todas as decisões de escalonamento para o espaço de utilizador (user-space) tem um certo custo (mesmo que mínimo).
No entanto, um escalonador totalmente implementado no espaço de utilizador permite uma integração fluida com bibliotecas sofisticadas, ferramentas de rastreio, serviços externos (ex: IA), etc.
Por isso, podem existir situações onde os benefícios superam o overhead, justificando o seu uso em produção.
-
Partilha semelhanças com o bpfland.
-
Criado para ser fácil de ler e compreender devido à implementação em userspace.
-
Nota: Existe uma ligeira desvantagem no rendimento ao usar um escalonador em userspace.
-
Casos de uso:
- Cargas de trabalho de baixa latência (Gaming, videoconferências e live streaming)
- Uso de desktop
Desenvolvido por: David Vernet (Byte-Lab GitHub)
Pronto para Produção?
- Sim, se for ajustado corretamente.
O Rusty oferece uma vasta gama de funcionalidades e uma grande capacidade de ajuste (tunability), permitindo personalizar o escalonador para requisitos muito específicos.
- Casos de utilização:
- Gaming / Jogos
- Cargas de trabalho sensíveis à latência
- Utilização em desktop
- Produção multimédia/áudio
- Excelente interatividade sob cargas de trabalho intensivas
- Poupança de energia
Configuração e Testes de Desempenho
Seção intitulada “Configuração e Testes de Desempenho”LAVD Autopilot & Autopower
Seção intitulada “LAVD Autopilot & Autopower”Citações de Changwoo Min:
- No modo Autopilot, o escalonador ajusta o seu modo (Powersave, Balanced ou Performance) com base na carga do sistema (utilização de CPU).
- Autopower: Decide automaticamente o modo com base no perfil de energia do sistema (EPP - Energy Performance Preference).
# O Autopower pode ser ativado pela seguinte flag:--autopower# ex:scx_lavd --autopowerananicy-cpp & sched-ext
Seção intitulada “ananicy-cpp & sched-ext”Para desativar/parar o ananicy-cpp, execute o seguinte comando:
systemctl disable --now ananicy-cppMudança de Perfil de Energia no scx_loader
Seção intitulada “Mudança de Perfil de Energia no scx_loader”Implementado no pacote power-profiles-daemon fornecido pelo CachyOS, que inclui um patch personalizado para suportar a mudança de perfis de energia do scx_loader.
- Se o
scx_loaderestiver a ser executado, quando o game-performance for utilizado, ele alternará automaticamente o escalonador ativo para o perfilGamingao iniciar um jogo, e voltará ao perfil predefinido quando o jogo for fechado. - Ao alternar entre perfis de energia (ex: no KDE Plasma ou GNOME utilizando o seletor de perfil de energia), o
scx_loadermudará automaticamente para o perfil de escalonador correspondente:
| Perfil de Energia | Perfil do Escalonador |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Benchmarking e comparação de escalonadores com cachyos-benchmarker
Seção intitulada “Benchmarking e comparação de escalonadores com cachyos-benchmarker”A ferramenta cachyos-benchmarker oferece uma forma fácil de avaliar e comparar o desempenho de diferentes escalonadores de CPU.
Esta ferramenta executa um conjunto abrangente de testes para medir o CPU, a memória e o desempenho geral do sistema sob várias cargas de trabalho.
Estão incluídos os seguintes benchmarks:
| Teste | Mede | Ferramenta |
|---|---|---|
| stress-ng cpu-cache-mem | Desempenho de CPU, cache e memória | stress-ng |
| FFmpeg compilation | Desempenho de compilação paralela | make |
| x265 encoding | Rendimento de codificação de vídeo | x265 |
| argon2 hashing | Hashing de passwords multithreaded | argon2 |
| perf sched msg | Troca de contexto e desempenho de IPC | perf |
| perf memcpy | Rendimento de memória memcpy() |
perf |
| prime calculation | Aritmética de inteiros e paralelismo | primesieve |
| NAMD | Dinâmica molecular (carga científica) | namd3 |
| Blender render | Renderização 3D apenas por CPU | blender |
| xz compression | Rendimento de compressão | xz |
| Kernel defconfig build | Desempenho de compilação do Kernel | make |
| y-cruncher | Precisão matemática e stress de memória | y-cruncher |
O cachyos-benchmarker pode ser utilizado para vários fins, incluindo:
- Testar a estabilidade do escalonador Execute o conjunto completo de benchmarks para detetar bloqueios (stalls), falhas (crashes) ou regressões introduzidas por alterações no escalonador.
- Recolher registos
Se estiver a utilizar o
scx_loader, pode recolher registos em caso de bloqueio ou falha com:Isto criará um ficheiro chamadoTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logno seu diretório atual. - Comparar o desempenho dos escalonadores
- Avalie as diferenças de desempenho entre escalonadores. Ex:
BPFLAND vs LAVD.
- Avalie as diferenças de desempenho entre escalonadores. Ex:
- Medir o efeito de atualizações do kernel ou do escalonador
- Compare execuções antes e depois de aplicar patches ou alterações de versão para verificar regressões ou melhorias de desempenho.
- Testar ajustes de configuração
- Avalie o impacto de alterações como as definições do regulador de CPU (governor), alternância de SMT ou flags modificadas do escalonador.
Requisitos
Seção intitulada “Requisitos”- 4 GB de RAM ou mais
- Pelo menos 8 GB de espaço livre em disco
- Tempo e paciência – o benchmark completo pode demorar mais de uma hora em sistemas mais lentos
Instalação
Seção intitulada “Instalação”Para instalar o cachyos-benchmarker, execute o seguinte comando:
sudo pacman -S cachyos-benchmarkerExecutar o benchmark
Seção intitulada “Executar o benchmark”- Execute o
cachyos-benchmarker:Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# Pode substituir ~/cachyos-benchmarker/ por qualquer diretório onde deseje que os registos sejam guardados. - Aguarde até que os passos de preparação terminem.
- Siga as instruções no terminal:
Do you want to drop page cache now? Root privileges needed! (y/N) y(Deseja limpar a cache de páginas agora? Requer privilégios de root!)Please enter a name for this run, or leave empty for default:(Por favor, introduza um nome para esta execução ou deixe em branco para o predefinido:)
- Aguarde que os testes terminem.
- Assim que terminar, acontecerá o seguinte:
- Criação de um ficheiro de registo com um nome semelhante a
benchie_<nome>_<DATA>.log, que contém informações detalhadas sobre a execução do benchmark.- Exemplo:
benchie_p2dq_2025-09-29-2115.log - O script
benchmark_scraper.pyserá executado automaticamente para gerar um relatório de resumo em formato HTML. - O que faz o script?:
- Lê todos os ficheiros
benchie_*.logno diretório especificado. - Extrai os nomes dos benchmarks, tempos e pontuações.
- Ordena ou agrega os dados.
- Exibe um resumo limpo dos resultados no seu terminal e cria um ficheiro HTML que pode ser aberto num navegador.
Exemplo de saída do terminal:
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54cálculo de números primos: 11.126hashing argon2: 6.62compilação ffmpeg: 53.38compressão xz: 61.13kernel defconfig: 130.73renderização blender: 96.29codificação x265: 24.99Tempo total (s): 506.72Pontuação total: 70.71Nome: p2dqData: 2025-09-29-2115Sistema: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemória: RAM do Sistema: total: 32 GiB disponível: 30.61 GiB usada: 7.54 GiB (24.6%)Dispositivo-1: Channel-A DIMM 0 tipo: LPDDR5 tamanho: 8 GiB velocidade: 7500 MT/sDispositivo-2: Channel-B DIMM 0 tipo: LPDDR5 tamanho: 8 GiB velocidade: 7500 MT/sDispositivo-3: Channel-C DIMM 0 tipo: LPDDR5 tamanho: 8 GiB velocidade: 7500 MT/sDispositivo-4: Channel-D DIMM 0 tipo: LPDDR5 tamanho: 8 GiB velocidade: 7500 MT/sCPU: Info: 8-core modelo: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 tipo: MT MCP cache: L2: 8 MiBVelocidade (MHz): média: 3366 min/max: 419/5138 núcleos: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366Escalonador SCX: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersão SCX: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersão : 0.5.1-1Exemplo em HTML de um resultado de teste comparando dois ramos diferentes do mesmo escalonador:
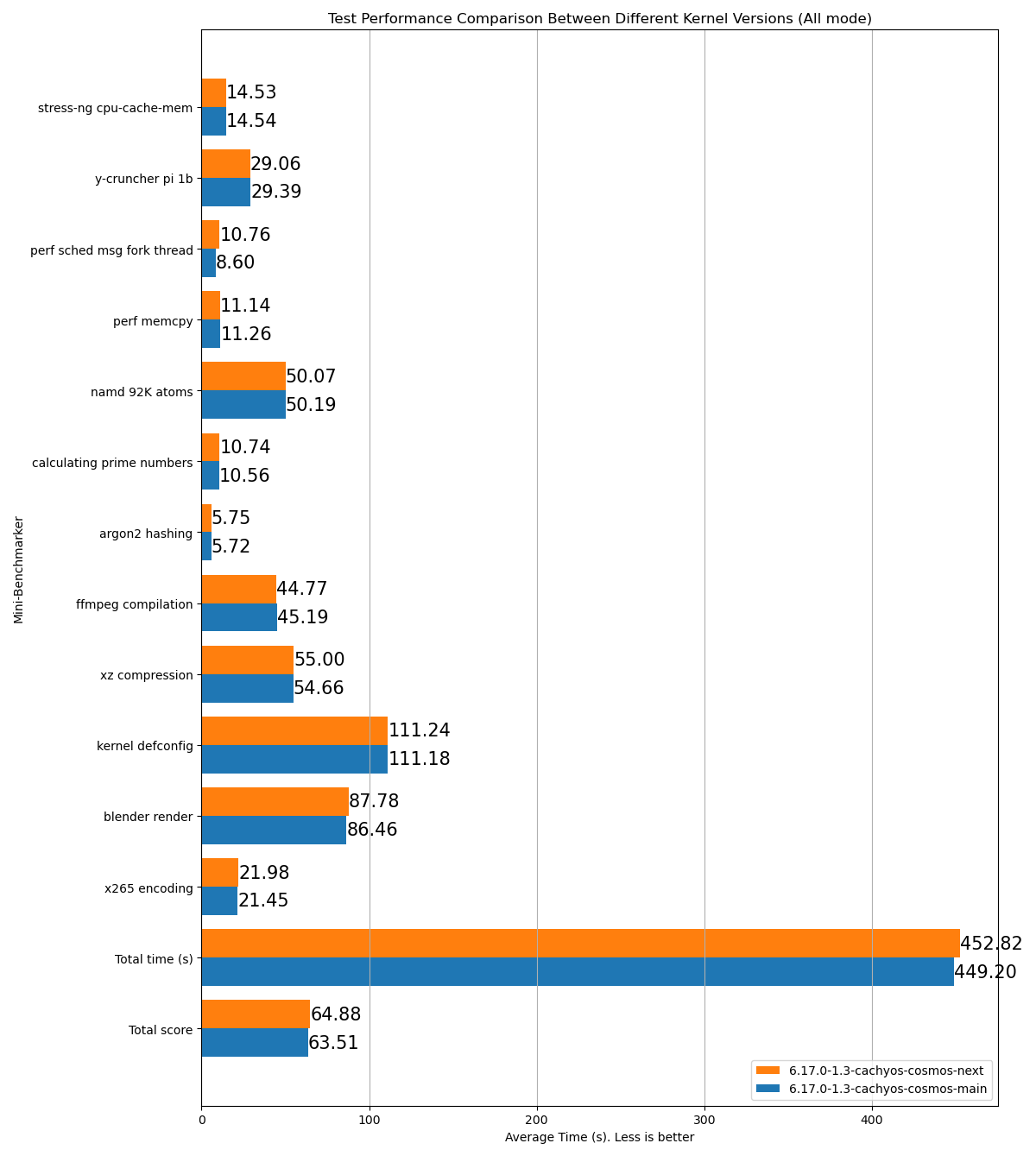
- Lê todos os ficheiros
- Exemplo:
- Criação de um ficheiro de registo com um nome semelhante a
- Para comparar duas ou mais execuções, coloque os ficheiros
.logno mesmo diretório antes de executar obenchmark_scraper.py. A ferramenta irá detetá-los e compará-los automaticamente no relatório HTML.
Testar a latência do escalonador com o schbench
Seção intitulada “Testar a latência do escalonador com o schbench”O schbench é um benchmark de escalonador desenhado para medir a latência do escalonador sob uma carga de trabalho simulada de estilo servidor. Este cria um número configurável de threads “worker” (trabalhadoras) e “message” (mensagens), onde as mensagens acordam repetidamente os workers. Ao medir a distribuição da latência desde o despertar até à execução destas threads, o schbench fornece informações críticas sobre a capacidade do kernel em lidar com o despertar de threads, o equilíbrio de carga (balancing) e a contenção de CPU, especialmente sob carga.
Casos de uso
Seção intitulada “Casos de uso”Pode utilizar o schbench para:
- Avaliar a latência do escalonador: Identificar quão rapidamente as threads são escalonadas após acordarem.
- Comparar o desempenho de despertar (wakeup) entre escalonadores: Detetar melhorias ou regressões na troca de contexto e na latência de despertar.
- Testar o efeito de patches no kernel ou no escalonador: Avaliar se ajustes ou atualizações afetam a justiça (fairness) e a responsividade do escalonamento.
Instalação
Seção intitulada “Instalação”O schbench está disponível nos repositórios do CachyOS:
sudo pacman -S schbenchExecutar o benchmark
Seção intitulada “Executar o benchmark”Uma forma simples de executar o schbench para um teste de latência geral é:
schbench -m 2 -t 8 -r 60Este exemplo executa:
- 2 threads de mensagem (
-m 2) - 8 threads trabalhadoras (worker threads) por thread de mensagem (
-t 8) - durante um tempo total de 60 segundos (
-r 60)
Podes ajustar estes valores dependendo do número de núcleos do teu CPU e do nível de carga desejado.
Aqui está uma tabela que explica algumas das principais opções:
| Opção | Descrição |
|---|---|
-C, --calibrate |
Executa a calibração e reporta o tempo (sem benchmark). |
-L, --no-locking |
Desativa os spinlocks durante o trabalho de CPU (padrão: bloqueio ativado). |
-m, --message-threads <n> |
Número de threads de mensagem (padrão: 1). |
-t, --threads <n> |
Threads trabalhadoras por thread de mensagem (padrão: número de CPUs). |
-r, --runtime <seg> |
Duração do benchmark (padrão: 30). |
-F, --cache_footprint <KB> |
Tamanho da pegada (footprint) da cache (padrão: 256). |
-n, --operations <count> |
Número de operações de “tempo de reflexão” a realizar (padrão: 5). |
-A, --auto-rps |
Aumenta automaticamente o RPS até atingir o alvo de utilização de CPU. |
-R, --rps <count> |
Modo de requisições por segundo. |
-p, --pipe <bytes> |
Simula um teste de transferência por pipe. |
-w, --warmuptime <seg> |
Duração do aquecimento antes de recolher estatísticas (padrão: 0). |
-i, --intervaltime <seg> |
Intervalo para exibir as latências (padrão: 10). |
-z, --zerotime <seg> |
Intervalo para reiniciar as estatísticas de latência (padrão: nunca). |
Compreender os resultados
Seção intitulada “Compreender os resultados”Após cada execução, o schbench exibe os percentis de latência como:
Exemplo de saída (Output)
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Como interpretar os resultados
Seção intitulada “Como interpretar os resultados”- Wakeup Latencies (Latências de Despertar):
- Mede a rapidez com que as threads acordam após serem sinalizadas.
- Valores mais baixos aqui (especialmente no percentil 99) significam que o escalonador é mais responsivo.
- Mede a rapidez com que as threads acordam após serem sinalizadas.
- Request Latencies (Latências de Requisição):
- Representa o tempo necessário para completar requisições entre threads.
- Uma latência mais baixa indica melhor comunicação entre threads e maior eficiência de escalonamento.
- Representa o tempo necessário para completar requisições entre threads.
- RPS (Requisições Por Segundo):
- Mostra o rendimento (throughput) sustentado:
- Um RPS médio mais elevado indica que o escalonador consegue lidar com mais trabalho por segundo sob a configuração dada.
- Mostra o rendimento (throughput) sustentado:
Em conclusão:
- Um bom escalonador apresentará latências de despertar e de requisição baixas com um RPS consistente.
- Um escalonador menos eficiente pode exibir picos de latência altos ou valores de RPS instáveis ao longo do tempo.
Recomendações para benchmarking de jogos
Seção intitulada “Recomendações para benchmarking de jogos”Se o seu desejo é testar jogos para comparar o desempenho de diferentes escalonadores, aqui estão algumas dicas para obter os resultados mais precisos:
- Utilize benchmarks integrados: Muitos jogos modernos incluem ferramentas de benchmark internas. Estas são desenhadas para fornecer resultados consistentes ao correr a mesma sequência de eventos em cada execução.
- Consulte este website para uma lista de jogos que incluem benchmarks integrados.
- Configurações consistentes: Certifique-se de que as definições do jogo (resolução, qualidade gráfica, etc.) são as mesmas em cada teste.
- Feche aplicações em segundo plano: Outras aplicações a correr em fundo podem afetar o desempenho. Feche programas desnecessários para minimizar o seu impacto.
- Consistência manual: Se não estiver a usar um benchmark integrado, tente realizar as mesmas ações no jogo em cada execução (seguir o mesmo caminho, combates semelhantes, etc.).
- Até o simples facto de não apontar para o mesmo local exato pode levar a variações nos resultados.
- Múltiplas execuções: Realize o benchmark várias vezes e utilize a média para compensar a variabilidade.
- Ferramentas de monitorização: Ferramentas como o MangoHud ou GOverlay podem fornecer métricas em tempo real, como FPS, frame times e utilização de CPU/GPU.
- Atalhos e Macros:
- Pode criar um atalho de teclado para alternar entre diferentes escalonadores ou mudar os seus modos “na hora” enquanto joga.
- Isto pode ser feito usando uma ferramenta como o scxctl ou através de scripts personalizados.
- Pode criar um atalho de teclado para alternar entre diferentes escalonadores ou mudar os seus modos “na hora” enquanto joga.
Upload e partilha de benchmarks
Seção intitulada “Upload e partilha de benchmarks”Este website contém uma lista de benchmarks feitos pela comunidade testando diferentes escalonadores e configurações.
Para carregar os seus próprios benchmarks, deverá associar a sua conta do Discord ao site.
Depois, clique no botão New benchmark e preencha a informação necessária:
- Pode carregar múltiplos resultados para o mesmo jogo usando diferentes escalonadores.
- Aceita registos (logs) do MangoHud e Afterburner.
- Permite pesquisa por título ou descrição.
Transição do scx.service para o scx_loader: Um Guia Abrangente
Seção intitulada “Transição do scx.service para o scx_loader: Um Guia Abrangente”Vamos começar com uma comparação direta entre a estrutura do ficheiro scx.service e a estrutura do ficheiro de configuração do scx_loader.
Se anteriormente tinha o LAVD a correr com o antigo scx.service, como no exemplo abaixo:
# Lista de escalonadores scx: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Definir flags personalizadas para o escalonadorSCX_FLAGS='--performance'Então, o equivalente no ficheiro de configuração do scx_loader será:
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Para mais informações sobre como configurar o ficheiro scx_loader
Siga o guia abaixo para uma transição fácil do scx systemd service para o novo utilitário scx_loader.
-
Desativar o scx.service em favor do scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Criar o ficheiro de configuração para o scx_loader e adicionar a estrutura predefinida # O editor Micro irá criar um novo ficheiro.sudo micro /etc/scx_loader.toml# Adicione as seguintes linhas:default_sched = "scx_bpfland" # Edite esta linha para o escalonador que deseja que o scx_loader inicie no arranquedefault_mode = "Auto" # Valores possíveis: "Auto", "Gaming", "LowLatency", "PowerSave".# Pressione CTRL + S para guardar as alterações e CTRL + Q para sair do Micro. -
Restarting the scx_loader systemctl restart scx_loader.service- Concluído, o scx_loader irá agora carregar e iniciar o escalonador pretendido.
Depuração (Debugging) no scx_loader
Seção intitulada “Depuração (Debugging) no scx_loader”-
Verificar o estado do serviço systemctl status scx_loader.service -
Visualizar todas as entradas de registo (logs) do serviço journalctl -u scx_loader.service -
Visualizar apenas os registos (logs) da sessão atual. journalctl -u scx_loader.service -b 0
Para obter um registo (log) mais detalhado, siga estes passos.
-
Editar o ficheiro de serviço sudo systemctl edit scx_loader.service -
Adicionar a seguinte linha sob a secção [Service] Environment=RUST_LOG=trace -
Reiniciar o serviço sudo systemctl restart scx_loader.service - Verifique os registos (logs) novamente para obter informações de depuração mais detalhadas.
Por que razão o escalonador X tem um desempenho pior do que o outro?
Seção intitulada “Por que razão o escalonador X tem um desempenho pior do que o outro?”- Existem muitas variáveis a considerar ao compará-los. Por exemplo, como medem o peso de uma tarefa? Priorizam tarefas interativas sobre as não interativas? Em última análise, depende das suas escolhas de design.
Por que é que todos dizem que o escalonador X é o melhor para o caso X, mas não funciona tão bem para mim?
Seção intitulada “Por que é que todos dizem que o escalonador X é o melhor para o caso X, mas não funciona tão bem para mim?”- Tal como na resposta anterior, a escolha do CPU e o seu design, como o layout dos núcleos, a forma como partilham a cache entre os núcleos e outros fatores relacionados, podem levar o escalonador a operar de forma menos eficiente.
- É por isso que ter escolhas é um dos destaques da framework sched-ext, por isso não tenha medo de experimentar um e ver qual funciona melhor para o seu caso de uso.
Exemplos: estabilidade de fps, desempenho máximo, capacidade de resposta sob cargas de trabalho intensivas, etc.
Os casos de uso destes escalonadores são bastante semelhantes… porquê?
Seção intitulada “Os casos de uso destes escalonadores são bastante semelhantes… porquê?”Principalmente porque são escalonadores de uso geral (multipurpose), o que significa que podem acomodar uma variedade de cargas de trabalho, mesmo que possam não exceder-se em todas as áreas.
- Para determinar qual o escalonador que melhor se adapta a si, não há melhor conselho do que experimentá-lo por si próprio.
Por que me falta um escalonador que alguns utilizadores estão a mencionar ou a testar no servidor Discord da CachyOS?
Seção intitulada “Por que me falta um escalonador que alguns utilizadores estão a mencionar ou a testar no servidor Discord da CachyOS?”Certifique-se de que está a usar a versão de desenvolvimento (bleeding edge) do pacote scx-scheds, denominada scx-scheds-git.
- Uma das razões será que esse escalonador é muito recente e está atualmente a ser testado pelos utilizadores, portanto, ainda não foi adicionado ao pacote
scx-scheds-git.
Por que é que o escalonador crashou subitamente? É instável?
Seção intitulada “Por que é que o escalonador crashou subitamente? É instável?”- Podem existir algumas razões para isto ter acontecido:
- Uma das razões mais comuns é que estava a usar o ananicy-cpp juntamente com o escalonador. É por isso que adicionámos este aviso
- Outra razão pode ser que a carga de trabalho que estava a executar excedeu os limites e a capacidade do escalonador, fazendo-o bloquear (stall).
- Exemplo de uma carga de trabalho irracional:
hackbench
- Exemplo de uma carga de trabalho irracional:
- Ou a razão mais óbvia: encontrou um bug no escalonador. Se for o caso, por favor reporte-o como um problema (issue) no seu GitHub ou informe os desenvolvedores no canal
sched-extdo Discord da CachyOS.
Já utilizei anteriormente o scx_loader na interface gráfica do Kernel Manager. Ainda preciso de seguir os passos de transição?
Seção intitulada “Já utilizei anteriormente o scx_loader na interface gráfica do Kernel Manager. Ainda preciso de seguir os passos de transição?”- Neste caso particular, não, não é necessário porque o Kernel Manager já lida com o processo de transição.
- A menos que tenha adicionado anteriormente flags personalizadas em
/etc/default/scxe ainda queira utilizá-las.
- A menos que tenha adicionado anteriormente flags personalizadas em
Saiba Mais
Seção intitulada “Saiba Mais”- Playlist de YT do Sched_ext
- LWN: The extensible scheduler class (Fevereiro, 2023)
- Blog de arighi: Implement your own kernel CPU scheduler in Ubuntu with sched_ext (Julho, 2023)
- Palestra de David Vernet: Kernel Recipes 2023 - sched_ext: pluggable scheduling in the Linux kernel (Setembro, 2023)
- Blog de Changwoo: sched_ext: a BPF-extensible scheduler class (Parte 1) (Dezembro, 2023)
- Blog de arighi: Getting started with sched_ext development (Abril, 2024)
- Blog de Changwoo: sched_ext: scheduler architecture and interfaces (Parte 2) (Junho, 2024)
- Canal de YT de arighi: scx_bpfland Linux scheduler demo: topology awareness (Agosto, 2024)
- Palestra de David Vernet: Kernel Recipes 2024 - Scheduling with superpowers: Using sched_ext to get big perf gains (Setembro, 2024)