Samouczek sched-ext
Extensible Scheduler Class (lepiej znany jako sched-ext) to funkcja jądra Linuksa, która umożliwia implementację harmonogramów wątków jądra w
BPF (Berkeley Package Filter) i ich dynamiczne ładowanie. Zasadniczo pozwala to użytkownikom końcowym na zmianę swoich harmonogramów w przestrzeni użytkownika bez
konieczności budowania nowego jądra tylko po to, by mieć inny harmonogram.
-
Harmonogramy można znaleźć w pakietach
scx-schedsiscx-scheds-git.Terminal window # Stabilna gałąź + narzędzia scx_loader i scxctl.sudo pacman -S scx-scheds scx-tools# Gałąź „Bleeding edge” (ta gałąź zawiera najnowsze zmiany z gałęzi master.) + narzędzia scx_loader i scxctl.sudo pacman -S scx-scheds-git scx-tools-git
Jak uruchamiać harmonogram i zarządzać nim
Dział zatytułowany „Jak uruchamiać harmonogram i zarządzać nim”- Aby uruchomić harmonogram, otwórz terminal i wpisz następujące polecenie:
Przykład uruchomienia rusty sudo scx_rusty
To polecenie uruchomi harmonogram rusty i odłączy domyślny harmonogram.
Aby zatrzymać harmonogram, naciśnij CTRL + C, a harmonogram zostanie zatrzymany, a domyślny harmonogram jądra ponownie przejmie kontrolę.
scxctl to klient CLI DBUS do interakcji z scx_loader.
- Funkcje:
- Uzyskaj informacje o bieżącym harmonogramie i trybie
- Wyświetl listę wszystkich dostępnych harmonogramów
- Uruchom harmonogram w danym trybie lub z podanymi argumentami
- Przełączaj się między harmonogramami i trybami
- Zatrzymaj działający harmonogram
- Zrestartuj działający harmonogram
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUsage: scxctl <COMMAND>
Commands: get Get the info on the running scheduler list List all supported schedulers start Start a scheduler in a mode or with arguments switch Switch schedulers or modes, optionally with arguments stop Stop the current scheduler restart Restart the current scheduler with original configuration restore Restore the default scheduler from configuration help Print this message or the help of the given subcommand(s)
Options: -h, --help Print help -V, --version Print versionJak sama nazwa wskazuje, jest to narzędzie, które funkcjonuje jako ładowarka i menedżer dla frameworka sched-ext przy użyciu interfejsu D-Bus.
Chociaż nie wymaga systemd, nadal może być używany w połączeniu z nim. Sprawdź przewodnik po przejściu w celach informacyjnych.
- Ma możliwość zatrzymywania, uruchamiania, ponownego uruchamiania, odczytywania informacji o harmonogramie scx i nie tylko.
- Możesz używać narzędzi takich jak
dbus-sendlubgdbusdo komunikacji z nim.
- Możesz używać narzędzi takich jak
- Ten przewodnik wyjaśnia, jak używać scx_loader z poleceniem dbus-send.
-
Uruchamianie scx_rusty z jego domyślnymi argumentami dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Uruchamianie harmonogramu z argumentami # Ten przykład uruchamia scx_bpfland z następującymi flagami: -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Zatrzymywanie aktualnie działającego harmonogramu dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Przełącz na domyślny harmonogram # scx_loader przełączy się na domyślny harmonogram ustawiony w pliku konfiguracyjnym scx_loaderdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Przełączanie na inny harmonogram w Trybie 2 dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# To przełącza na scx_lavd w trybie harmonogramu 2, co oznacza uruchomienie LAVD w trybie oszczędzania energii -
Przełączanie na inny harmonogram z argumentami dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Pobieranie informacji o aktualnie działającym harmonogramie dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Pobieranie listy obsługiwanych harmonogramów dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Możesz uzyskać do nich dostęp i je skonfigurować za pomocą przycisku sched-ext scheduler config.
Menedżer SCX to samodzielne narzędzie GUI pochodzące z Menedżera jądra CachyOS. Pozwala użytkownikom zarządzać frameworkiem sched-ext i jego harmonogramami za pośrednictwem scx_loader.
Funkcje:
- Sprawdź, który harmonogram jest aktualnie aktywny
- Wybierz harmonogram lub profil: (Auto, Gaming, Oszczędzanie energii, Niskie opóźnienia lub Serwer)
- Ustaw dodatkowe flagi
- Wyłącz bieżący harmonogram
Zrzut ekranu

Przewodnik po schedulerach: Profile i przypadki użycia
Dział zatytułowany „Przewodnik po schedulerach: Profile i przypadki użycia”Ponieważ do wyboru jest wiele schedulerów, chcemy przedstawić krótkie wprowadzenie do dostępnych opcji.
Zachęcamy do zgłaszania wszelkich problemów lub opinii w repozytorium danego schedulera.
Użyj scx_nazwaschedulera --help, aby zobaczyć dostępne flagi i krótki opis ich działania.
scx_rusty --helpDeweloper: Andrea Righi (arighi GitHub)
Gotowy do użytku produkcyjnego?
Scheduler sched_ext oparty na vruntime, który priorytetyzuje obciążenia interaktywne. Bardzo elastyczny i łatwy w adaptacji.
Bpfland, podejmując decyzje o tym, których rdzeni użyć, bierze pod uwagę ich układ pamięci podręcznej oraz to, które rdzenie dzielą tę samą pamięć podręczną L2/L3, co prowadzi do mniejszej liczby chybionych trafień w pamięci podręcznej = większej wydajności.
- Przypadki użycia:
- Gaming
- Użytek na komputerach stacjonarnych
- Produkcja multimediów/audio
- Doskonała interaktywność pod intensywnym obciążeniem
- Oszczędzanie energii
- Serwer
Tryby schedulera
Dział zatytułowany „Tryby schedulera”Niskie opóźnienia (Low Latency)
Dział zatytułowany „Niskie opóźnienia (Low Latency)”- Flagi wiersza poleceń:
-m performance -w - Opis: Ma na celu obniżenie opóźnień kosztem przepustowości. Odpowiedni dla aplikacji miękkiego czasu rzeczywistego, takich jak przetwarzanie audio i multimedia.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
-s 20000 -m powersave -I 100 -t 100 - Opis: Priorytetyzuje wydajność energetyczną. Preferuje mniej wydajne rdzenie (np. rdzenie E w procesorach Intela).
Serwer (Server)
Dział zatytułowany „Serwer (Server)”- Flagi wiersza poleceń:
-s 20000 -S - Opis: Priorytetyzuje zadania ze ścisłą koligacją. Ta opcja może zwiększyć przepustowość kosztem opóźnień i jest bardziej odpowiednia dla obciążeń serwerowych.
Deweloper: Andrea Righi (arighi GitHub)
Gotowy do użytku produkcyjnego?
scx_beerland to scheduler zaprojektowany w celu priorytetyzacji lokalności i skalowalności.
Priorytetyzuje utrzymywanie zadań na tym samym procesorze w celu zachowania lokalności pamięci podręcznej, jednocześnie zapewniając dobrą skalowalność na wielu procesorach poprzez użycie lokalnych DSQ (kolejek uruchomieniowych per-CPU), gdy system nie jest przeciążony.
- Przypadki użycia:
- Obciążenia intensywnie korzystające z pamięci podręcznej
- Systemy z dużą liczbą procesorów
- Gaming: Wiadomo, że działa zaskakująco dobrze w niektórych grach, chociaż Twoje doświadczenia mogą być różne
- Serwer: Dobry dla ogólnych obciążeń serwerowych ze względu na optymalizację skalowalności i lokalności.
- Może być również używany na komputerach stacjonarnych.
Tryby schedulera
Dział zatytułowany „Tryby schedulera”Brak na chwilę obecną.
Deweloper: Andrea Righi (arighi GitHub)
Gotowy do użytku produkcyjnego?
W scenariuszach produkcyjnych o krytycznym znaczeniu dla wydajności inne schedulery prawdopodobnie wykażą lepszą wydajność, ponieważ przeniesienie wszystkich decyzji dotyczących szeregowania do przestrzeni użytkownika wiąże się z pewnym kosztem (nawet jeśli jest on minimalny).
Jednakże, scheduler w całości zaimplementowany w przestrzeni użytkownika ma potencjał do bezproblemowej integracji z zaawansowanymi bibliotekami, narzędziami do śledzenia, usługami zewnętrznymi (np. AI) itp.
Dlatego mogą istnieć sytuacje, w których korzyści przewyższają narzut, uzasadniając użycie tego schedulera w środowisku produkcyjnym.
Dzieli podobieństwa z bpfland, stworzony z myślą o łatwości czytania i zrozumienia jego działania dzięki implementacji w przestrzeni użytkownika.
Pamiętaj, że używanie schedulera w przestrzeni użytkownika wiąże się z niewielką wadą w postaci mniejszej przepustowości.
- Przypadki użycia:
- Obciążenia o niskich opóźnieniach (gaming, wideokonferencje i transmisje na żywo)
- Użytek na komputerach stacjonarnych
Deweloper: Andrea Righi (arighi GitHub)
Gotowy do użytku produkcyjnego?
Scheduler, który skupia się na zapewnieniu sprawiedliwości między zadaniami i przewidywalności wydajności.
Działa na zasadzie earliest deadline first (EDF), gdzie każdemu zadaniu przypisana jest waga „opóźnienia”. Waga ta jest dynamicznie dostosowywana w zależności od tego, jak często zadanie zwalnia procesor przed wykorzystaniem pełnego przydziału czasu.
Zadania, które wcześnie zwalniają procesor, otrzymują wyższą wagę opóźnienia, co priorytetyzuje je nad zadaniami, które w pełni zużywają swój przydział czasu.
- Przypadki użycia:
- Gaming
- Obciążenia wrażliwe na opóźnienia, takie jak multimedia czy przetwarzanie audio w czasie rzeczywistym
- Potrzeba responsywności w sytuacjach dużego obciążenia
- Spójność wydajności
- Serwer
Tryby schedulera
Dział zatytułowany „Tryby schedulera”Niskie opóźnienia (Low Latency)
Dział zatytułowany „Niskie opóźnienia (Low Latency)”- Flagi wiersza poleceń:
-m performance -w -C 0 - Opis: Ma na celu obniżenie opóźnień kosztem przepustowości. Odpowiedni dla aplikacji miękkiego czasu rzeczywistego, takich jak przetwarzanie audio i multimedia.
- Flagi wiersza poleceń:
-m all - Opis: Optymalizuje pod kątem wysokiej wydajności w grach.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Opis: Priorytetyzuje wydajność energetyczną. Preferuje mniej wydajne rdzenie (np. rdzenie E w procesorach Intela) i wprowadza wymuszony cykl bezczynności co 10 ms w celu zwiększenia oszczędności energii.
Serwer (Server)
Dział zatytułowany „Serwer (Server)”- Flagi wiersza poleceń:
-m all -s 20000 -S 1000 -I -1 -D -L - Opis: Dostrojony do obciążeń serwerowych. Wymienia responsywność na przepustowość.
Deweloper: Andrea Righi (arighi GitHub)
- Gotowy do użytku produkcyjnego?
Lekki scheduler zoptymalizowany pod kątem zachowania lokalności zadanie-do-CPU.
Gdy system nie jest przeciążony, scheduler priorytetyzuje utrzymywanie zadań na tym samym procesorze przy użyciu lokalnych DSQ. To nie tylko utrzymuje lokalność, ale także zmniejsza rywalizację o blokady w porównaniu do współdzielonych DSQ, umożliwiając dobrą skalowalność na wielu procesorach.
- Przypadki użycia:
- Scheduler ogólnego przeznaczenia: scheduler powinien dostosowywać się zarówno do obciążeń serwerowych, jak i stacjonarnych.
Tryby schedulera
Dział zatytułowany „Tryby schedulera”- Flagi wiersza poleceń:
-d - Opis: Wyłącza odroczone wybudzanie. Zmniejsza przepustowość i wydajność dla niektórych obciążeń, jednocześnie zmniejszając zużycie energii.
- Flagi wiersza poleceń:
-c 0 -p 0 - Opis: Wyłącza śledzenie obciążenia procesora i zawsze wymusza szeregowanie oparte na terminach w celu poprawy responsywności.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
-m powersave -d -p 5000 - Opis: Priorytetyzuje wydajność energetyczną. Preferuje mniej wydajne rdzenie (np. rdzenie E w procesorach Intela) i wyłącza odroczone wybudzanie, zmniejszając przepustowość przy jednoczesnym zwiększeniu wydajności energetycznej. Odpytywanie o obciążenie procesora zwiększone do 5 ms.
Niskie opóźnienia (Low Latency)
Dział zatytułowany „Niskie opóźnienia (Low Latency)”- Flagi wiersza poleceń:
-m performance -c 0 -p 0 -w - Opis: Ma na celu obniżenie opóźnień kosztem przepustowości. Odpowiedni dla aplikacji miękkiego czasu rzeczywistego, takich jak przetwarzanie audio i multimedia. Zawsze wymusza szeregowanie oparte na terminach i synchroniczne optymalizacje wybudzania w celu poprawy przewidywalności wydajności.
Serwer (Server)
Dział zatytułowany „Serwer (Server)”- Flagi wiersza poleceń:
-s 20000 - Opis: Włącza koligację przestrzeni adresowej w celu poprawy lokalności i wydajności w niektórych obciążeniach wrażliwych na pamięć podręczną. Odpytywanie zwiększone do 20 ms.
Deweloper: Changwoo Min (multics69 GitHub).
- Gotowy do użytku produkcyjnego?
Krótkie wprowadzenie do LAVD od Changwoo:
LAVD to nowy algorytm szeregowania, który jest wciąż w fazie rozwoju. Jest zmotywowany obciążeniami gamingowymi, które są krytyczne pod względem opóźnień i intensywne komunikacyjnie. Jego celem jest minimalizacja skoków opóźnień przy jednoczesnym utrzymaniu ogólnie dobrej przepustowości i sprawiedliwego wykorzystania czasu procesora przez zadania.
- Przypadki użycia:
- Gaming
- Produkcja audio
- Obciążenia wrażliwe na opóźnienia
- Użytek na komputerach stacjonarnych
- Doskonała interaktywność pod intensywnym obciążeniem
- Oszczędzanie energii
Jedną z głównych i niesamowitych możliwości, jakie oferuje LAVD, jest kompakcja rdzeni, która, nie wchodząc w szczegóły techniczne: Gdy użycie procesora < 50%, aktualnie aktywne rdzenie będą działać dłużej i z wyższą częstotliwością. Tymczasem bezczynne rdzenie pozostaną w stanie C (uśpienia) przez znacznie dłuższy czas, co prowadzi do mniejszego ogólnego zużycia energii.
Tryby schedulera
Dział zatytułowany „Tryby schedulera”Gaming i niskie opóźnienia (Gaming & Low Latency)
Dział zatytułowany „Gaming i niskie opóźnienia (Gaming & Low Latency)”- Flagi wiersza poleceń:
--performance - Opis: Maksymalizuje wydajność, używając wszystkich dostępnych rdzeni, priorytetyzując rdzenie fizyczne.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
--powersave - Opis: Minimalizuje zużycie energii przy zachowaniu rozsądnej wydajności. Priorytetyzuje wydajne rdzenie i wątki nad rdzeniami fizycznymi.
Deweloper: David Vernet (Byte-Lab GitHub)
- Gotowy do użytku produkcyjnego?
- Tak. Jeśli jest poprawnie dostrojony,
Rusty oferuje szeroki zakres funkcji, które zwiększają jego możliwości, zapewniając większą elastyczność w różnych przypadkach użycia. Jedną z tych funkcji jest możliwość dostrajania, co pozwala dostosować Rusty do własnych preferencji i specyficznych wymagań.
- Przypadki użycia:
- Gaming
- Obciążenia wrażliwe na opóźnienia
- Użytek na komputerach stacjonarnych
- Produkcja multimediów/audio
- Doskonała interaktywność pod intensywnym obciążeniem
- Oszczędzanie energii
- Gotowy do użytku produkcyjnego?
- Tak. Jeśli jest dostrojony do konkretnego obciążenia i sprzętu.
Deweloper: Daniel Hodges (hodgesds GitHub)
Scheduler ogólnego przeznaczenia, który skupia się na balansowaniu obciążenia typu „wybierz dwa” (pick two) między pamięciami podręcznymi ostatniego poziomu (LLC). Utrzymuje wysoką lokalność pamięci podręcznej i oszczędność pracy, zapewniając jednocześnie rozsądne opóźnienia.
- Przypadki użycia:
- Serwer
- Środowiska stacjonarne
- Gaming (z pewnym ręcznym dostrajaniem)
Tryby schedulera
Dział zatytułowany „Tryby schedulera”- Flagi wiersza poleceń:
--task-slice true -f --sched-mode performance - Opis: Poprawia spójność wydajności w grach i zwiększa tendencję do szeregowania na rdzeniach o wyższej wydajności.
Niskie opóźnienia (Low Latency)
Dział zatytułowany „Niskie opóźnienia (Low Latency)”- Flagi wiersza poleceń:
-y -f --task-slice true - Opis: Obniża opóźnienia, sprawiając, że zadania interaktywne bardziej trzymają się procesora, do którego zostały przypisane, i zwiększając stabilność przydziału czasu.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
--sched-mode efficiency - Opis: Zwiększa wydajność energetyczną, priorytetyzując rdzenie o niskim poborze mocy.
Serwer (Server)
Dział zatytułowany „Serwer (Server)”- Flagi wiersza poleceń:
--keep-running - Opis: Poprawia wydajność obciążeń serwerowych, pozwalając zadaniom działać dłużej niż ich przydział czasu, jeśli procesor jest bezczynny.
Deweloper: Andrea Righi (arighi Github)
- Gotowy do użytku produkcyjnego?
- Ten scheduler jest wciąż eksperymentalny i nie jest zalecany do użytku produkcyjnego.
scx_tickless to scheduler zorientowany na serwery, zaprojektowany z myślą o chmurze obliczeniowej, wirtualizacji i obciążeniach obliczeniowych wysokiej wydajności.
Scheduler działa poprzez kierowanie wszystkich zdarzeń szeregowania przez pulę głównych procesorów przypisanych do obsługi tych zdarzeń. Pozwala to na wyłączenie tyknięcia schedulera na innych procesorach, zmniejszając szum systemu operacyjnego.
- Przypadki użycia:
- Chmura obliczeniowa
- Wirtualizacja
- Obciążenia obliczeniowe wysokiej wydajności
- Serwer
Tryby schedulera
Dział zatytułowany „Tryby schedulera”- Flagi wiersza poleceń:
-f 5000 -s 5000 - Opis: Zwiększa wydajność w grach poprzez zwiększenie częstotliwości wykrywania przez scheduler rywalizacji o procesor i wywoływania przełączeń kontekstu z krótszym przydziałem czasu.
Oszczędzanie energii (Power Save)
Dział zatytułowany „Oszczędzanie energii (Power Save)”- Flagi wiersza poleceń:
-f 50 - Opis: Zwiększa wydajność energetyczną poprzez obniżenie częstotliwości sprawdzania rywalizacji.
Niskie opóźnienia (Low Latency)
Dział zatytułowany „Niskie opóźnienia (Low Latency)”- Flagi wiersza poleceń:
-f 5000 -s 1000 - Opis: Podobny do profilu gamingowego, ale z jeszcze bardziej zmniejszonym przydziałem czasu.
Serwer (Server)
Dział zatytułowany „Serwer (Server)”- Flagi wiersza poleceń:
-f 100 - Opis: Zmniejszona częstotliwość sprawdzania rywalizacji o procesor przez scheduler w celu poprawy przepustowości kosztem responsywności.
Konfiguracja i testowanie wydajności
Dział zatytułowany „Konfiguracja i testowanie wydajności”Autopilot i Autopower LAVD
Dział zatytułowany „Autopilot i Autopower LAVD”Cytaty z Changwoo Mina:
-
W trybie autopilota, scheduler dostosowuje swój tryb zasilania (
Powersave,BalancedlubPerformance) w oparciu o obciążenie systemu, a konkretnie o wykorzystanie procesora. -
Autopower: Automatycznie decyduje o trybie zasilania schedulera w oparciu o profil energetyczny systemu, czyli EPP (Energy Performance Preference).
# Autopower można aktywować za pomocą następującej flagi:--autopower# np.:scx_lavd --autopowerananicy-cpp i sched-ext
Dział zatytułowany „ananicy-cpp i sched-ext”Aby wyłączyć/zatrzymać ananicy-cpp, uruchom następujące polecenie:
systemctl disable --now ananicy-cppPrzełączanie profili zasilania scx_loader
Dział zatytułowany „Przełączanie profili zasilania scx_loader”Zaimplementowane w pakiecie power-profiles-daemon dostarczanym przez CachyOS, który zawiera niestandardową łatkę w celu obsługi przełączania profili zasilania scx_loader.
- Jeśli
scx_loaderjest aktualnie uruchomiony, przy użyciu game-performance automatycznie przełączy aktywny harmonogram na profilGaming, gdy gra zostanie uruchomiona, i powróci do profilu domyślnego po zamknięciu gry. - Podczas zmiany profili zasilania, np. w KDE Plasma lub GNOME za pomocą przełącznika profili zasilania,
scx_loaderautomatycznie przełączy się na odpowiedni profil harmonogramu:
| Power Profile | Scheduler Profile |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Porównywanie i testowanie wydajności schedulerów za pomocą cachyos-benchmarker
Dział zatytułowany „Porównywanie i testowanie wydajności schedulerów za pomocą cachyos-benchmarker”Narzędzie cachyos-benchmarker zapewnia łatwy sposób na ocenę i porównanie wydajności różnych schedulerów procesora.
Uruchamia ono kompleksowy zestaw testów porównawczych w celu pomiaru wydajności procesora, pamięci i ogólnej wydajności systemu w różnych warunkach obciążenia.
Zawarte są następujące testy:
| Test | Mierzy | Narzędzie |
|---|---|---|
| stress-ng cpu-cache-mem | Wydajność procesora, pamięci podręcznej i pamięci | stress-ng |
| Kompilacja FFmpeg | Wydajność budowania równoległego | make |
| Kodowanie x265 | Przepustowość kodowania wideo | x265 |
| Haszowanie argon2 | Wielowątkowe haszowanie haseł | argon2 |
| perf sched msg | Wydajność przełączania kontekstu i IPC | perf |
| perf memcpy | Przepustowość pamięci memcpy() |
perf |
| Obliczanie liczb pierwszych | Arytmetyka liczb całkowitych i równoległość | primesieve |
| NAMD | Dynamika molekularna (obciążenie naukowe) | namd3 |
| Renderowanie w Blenderze | Renderowanie 3D tylko przy użyciu procesora | blender |
| Kompresja xz | Przepustowość kompresji | xz |
| Budowanie defconfig jądra | Wydajność kompilacji jądra | make |
| y-cruncher | Precyzja matematyczna i obciążenie pamięci | y-cruncher |
cachyos-benchmarker może być używany do kilku celów, w tym:
- Testowanie stabilności schedulera
Uruchom pełny zestaw testów porównawczych, aby wykryć zacięcia, awarie lub regresje wprowadzone przez zmiany w schedulerze.
Jeśli używasz
scx_loader, możesz zebrać logi w przypadku zacięcia lub awarii za pomocą:Spowoduje to utworzenie pliku o nazwieTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logw bieżącym katalogu. - Porównywanie wydajności schedulerów
- Ocena różnic w wydajności między schedulerami, np.
BPFLAND vs LAVD
- Ocena różnic w wydajności między schedulerami, np.
- Mierzenie efektu aktualizacji jądra lub schedulera
- Porównanie przebiegów przed i po zastosowaniu łatek lub zmian wersji w celu sprawdzenia regresji lub poprawy wydajności.
- Testowanie modyfikacji konfiguracji
- Ocena wpływu zmian, takich jak ustawienia zarządcy procesora, przełączanie SMT lub zmodyfikowane flagi schedulera.
Wymagania
Dział zatytułowany „Wymagania”- 4 GB RAM lub więcej
- Co najmniej 8 GB wolnego miejsca na dysku
- Czas i cierpliwość - pełny test może trwać ponad godzinę na wolniejszych systemach
Instalacja
Dział zatytułowany „Instalacja”Aby zainstalować cachyos-benchmarker, uruchom następujące polecenie:
sudo pacman -S cachyos-benchmarkerUruchamianie testu
Dział zatytułowany „Uruchamianie testu”- Uruchom
cachyos-benchmarker:Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# Możesz zastąpić ~/cachyos-benchmarker/ dowolnym katalogiem, w którym chcesz zapisać logi. - Poczekaj, aż zakończą się kroki przygotowawcze.
- Postępuj zgodnie z instrukcjami:
Do you want to drop page cache now? Root privileges needed! (y/N) y(Czy chcesz teraz wyczyścić page cache? Wymagane uprawnienia roota! (t/N) t)Please enter a name for this run, or leave empty for default:(Wprowadź nazwę dla tego przebiegu lub pozostaw puste dla domyślnej:)
- Poczekaj na zakończenie testów.
- Po zakończeniu, nastąpią następujące czynności:
- Utworzenie pliku dziennika o nazwie podobnej do
benchie_<nazwa>_<DATA>.log, który zawiera szczegółowe informacje o przebiegu testu.- Przykład:
benchie_p2dq_2025-09-29-2115.log - Skrypt
benchmark_scraper.pyzostanie automatycznie wykonany, aby wygenerować raport podsumowujący w formacie HTML. - Co robi skrypt?:
- Odczytuje wszystkie pliki
benchie_*.logw określonym katalogu. - Wyodrębnia nazwy testów, czasy i wyniki.
- Sortuje lub agreguje je.
- Wyświetla czyste podsumowanie wyników w terminalu i tworzy plik HTML, który można otworzyć w przeglądarce.
Przykład wyniku w terminalu:
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1Przykład HTML wyniku testu porównującego dwie różne gałęzie tego samego schedulera:
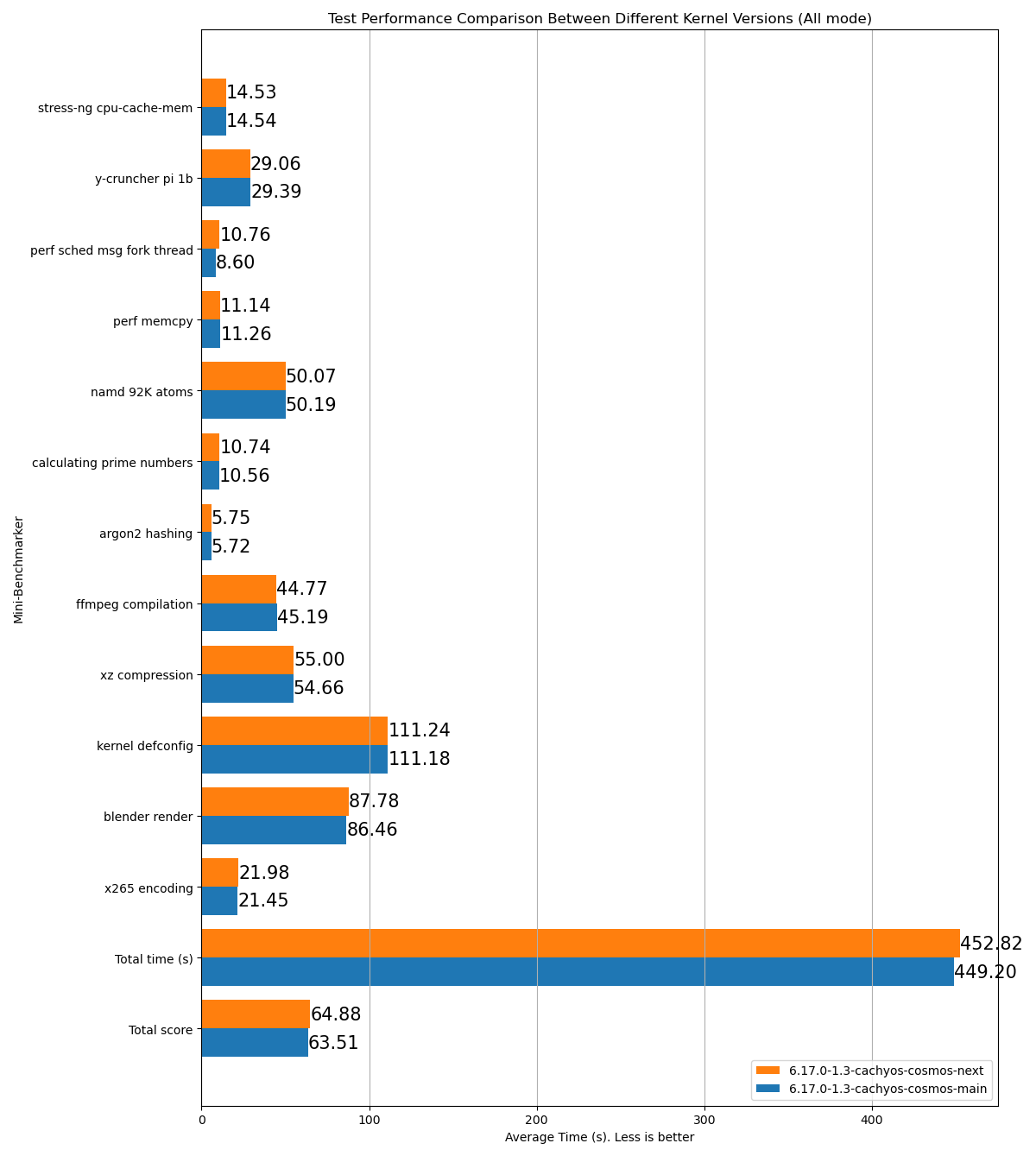
- Odczytuje wszystkie pliki
- Przykład:
- Utworzenie pliku dziennika o nazwie podobnej do
- Aby porównać dwa lub więcej przebiegów, umieść pliki
.logw tym samym katalogu przed uruchomieniembenchmark_scraper.py. Narzędzie automatycznie je wykryje i porówna w raporcie HTML.
Testowanie opóźnień schedulera za pomocą schbench
Dział zatytułowany „Testowanie opóźnień schedulera za pomocą schbench”schbench to benchmark schedulera zaprojektowany do pomiaru opóźnień schedulera w symulowanym obciążeniu w stylu serwerowym. Tworzy on konfigurowalną liczbę wątków „roboczych” i „wiadomości”, gdzie wiadomości wielokrotnie budzą wątki robocze. Mierząc rozkład opóźnień od wybudzenia do wykonania tych wątków roboczych, dostarcza on kluczowych informacji o zdolności jądra do obsługi wybudzeń wątków, równoważenia obciążenia i rywalizacji o CPU, zwłaszcza pod obciążeniem.
Zastosowania
Dział zatytułowany „Zastosowania”Możesz użyć schbench do:
- Oceny opóźnień schedulera: Określenia, jak szybko wątki są planowane po wybudzeniu.
- Porównywania wydajności wybudzania między schedulerami: Wykrywania poprawy lub regresji w przełączaniu kontekstu i opóźnieniach wybudzania.
- Testowania wpływu łatek na jądro lub scheduler: Oceny, czy dostrajanie lub aktualizacje wpływają na sprawiedliwość i responsywność planowania.
Instalacja
Dział zatytułowany „Instalacja”schbench jest dostępny w repozytoriach CachyOS:
sudo pacman -S schbenchUruchamianie testu
Dział zatytułowany „Uruchamianie testu”Prosty sposób na uruchomienie schbench w celu ogólnego testu opóźnień to:
schbench -m 2 -t 8 -r 60Ten przykład uruchamia:
- 2 wątki wiadomości (
-m 2) - 8 wątków roboczych na każdy wątek wiadomości (
-t 8) - na łączny czas 60 sekund (
-r 60)
Możesz dostosować te wartości w zależności od liczby rdzeni procesora i pożądanego poziomu obciążenia.
Oto tabela wyjaśniająca niektóre z kluczowych opcji:
| Opcja | Opis |
|---|---|
-C, --calibrate |
Uruchom kalibrację i podaj wyniki pomiaru czasu (bez testu). |
-L, --no-locking |
Wyłącz spinlocki podczas pracy CPU (domyślnie: blokowanie włączone). |
-m, --message-threads <n> |
Liczba wątków wiadomości (domyślnie: 1). |
-t, --threads <n> |
Wątki robocze na wątek wiadomości (domyślnie: liczba procesorów). |
-r, --runtime <sec> |
Czas trwania testu (domyślnie: 30). |
-F, --cache_footprint <KB> |
Rozmiar śladu pamięci podręcznej (domyślnie: 256). |
-n, --operations <count> |
Liczba operacji “czasu namysłu” do wykonania (domyślnie: 5). |
-A, --auto-rps |
Automatycznie zwiększaj RPS, aż do osiągnięcia docelowego wykorzystania CPU. |
-R, --rps <count> |
Tryb żądań na sekundę. |
-p, --pipe <bytes> |
Symuluj test transferu przez potok. |
-w, --warmuptime <sec> |
Czas rozgrzewki przed zbieraniem statystyk (domyślnie: 0). |
-i, --intervaltime <sec> |
Interwał wyświetlania opóźnień (domyślnie: 10). |
-z, --zerotime <sec> |
Interwał zerowania statystyk opóźnień (domyślnie: nigdy). |
Zrozumienie wyników
Dział zatytułowany „Zrozumienie wyników”Po każdym przebiegu schbench wyświetla percentyle opóźnień, takie jak:
Przykład wyniku
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Jak interpretować wyniki
Dział zatytułowany „Jak interpretować wyniki”- Opóźnienia wybudzania (Wakeup Latencies):
- Mierzy, jak szybko wątki budzą się po otrzymaniu sygnału.
- Niższe wartości tutaj (szczególnie 99. percentyl) oznaczają, że scheduler jest bardziej responsywny.
- Mierzy, jak szybko wątki budzą się po otrzymaniu sygnału.
- Opóźnienia żądań (Request Latencies):
- Reprezentuje czas potrzebny na ukończenie żądań między wątkami.
- Niższe opóźnienie wskazuje na lepszą komunikację międzywątkową i wydajność planowania.
- Reprezentuje czas potrzebny na ukończenie żądań między wątkami.
- RPS (Żądania na sekundę):
- Pokazuje utrzymaną przepustowość:
- Wyższa średnia RPS wskazuje, że scheduler może obsłużyć więcej pracy na sekundę w danej konfiguracji.
- Pokazuje utrzymaną przepustowość:
Podsumowując:
- Dobry scheduler będzie wykazywał niskie opóźnienia wybudzania i żądań ze stabilnym RPS.
- Mniej wydajny scheduler może wykazywać wysokie skoki opóźnień lub niestabilne wartości RPS w czasie.
Zalecenia dotyczące testowania wydajności gier
Dział zatytułowany „Zalecenia dotyczące testowania wydajności gier”Jeśli chcesz testować wydajność gier w celu porównania, jak działają różne schedulery, oto kilka wskazówek, aby uzyskać jak najdokładniejsze wyniki:
- Używaj wbudowanych benchmarków: Wiele nowoczesnych gier posiada wbudowane narzędzia do testowania wydajności. Są one zaprojektowane tak, aby zapewniać spójne wyniki, uruchamiając za każdym razem tę samą sekwencję zdarzeń.
- Sprawdź tę stronę internetową w poszukiwaniu listy gier, które zawierają wbudowane benchmarki.
- Spójne ustawienia: Upewnij się, że ustawienia gry (rozdzielczość, jakość grafiki itp.) są takie same dla każdego testu.
- Zamknij aplikacje działające w tle: Inne aplikacje działające w tle mogą wpływać na wydajność. Zamknij niepotrzebne programy, aby zminimalizować ich wpływ.
- Jeśli nie używasz wbudowanego benchmarku, staraj się wykonywać te same czynności w grze podczas każdego testu. Może to obejmować podążanie tą samą ścieżką, angażowanie się w podobne scenariusze walki lub wykonywanie tych samych zadań.
- Nawet celowanie w inne miejsce może prowadzić do różnych wyników wydajności.
- Wiele przebiegów: Wykonaj wiele przebiegów testu i weź średnią, aby uwzględnić zmienność.
- Używaj narzędzi do monitorowania wydajności: Narzędzia takie jak MangoHud czy GOverlay mogą dostarczać metryki wydajności w czasie rzeczywistym, takie jak FPS, czasy klatek oraz użycie CPU/GPU.
- Wykorzystaj skróty klawiaturowe lub makra:
- Jednym z przykładów jest utworzenie skrótu klawiszowego, za pomocą którego można przełączać się między różnymi schedulerami lub zmieniać ich tryby w locie podczas gry.
- Można to zrobić za pomocą narzędzia takiego jak scxctl lub tworząc niestandardowe skrypty, które zmieniają aktywny scheduler i jego tryb.
- Jednym z przykładów jest utworzenie skrótu klawiszowego, za pomocą którego można przełączać się między różnymi schedulerami lub zmieniać ich tryby w locie podczas gry.
Przesyłanie i udostępnianie swoich testów
Dział zatytułowany „Przesyłanie i udostępnianie swoich testów”Ta strona internetowa zawiera listę testów wykonanych przez społeczność przy użyciu różnych schedulerów lub testujących różne ustawienia.
Aby przesłać własne testy, musisz połączyć swoje konto Discord ze stroną, a następnie możesz przesłać własne benchmarki.
Następnie kliknij przycisk New benchmark i wypełnij wymagane informacje.
- Możesz przesłać wiele wyników dla tej samej gry, używając różnych schedulerów lub ustawień.
- Akceptuje logi zarówno z MangoHud, jak i Afterburner.
- Umożliwia wyszukiwanie po tytule lub opisie.
Przejście z scx.service na scx_loader: Kompleksowy przewodnik
Dział zatytułowany „Przejście z scx.service na scx_loader: Kompleksowy przewodnik”Zacznijmy od szczegółowego porównania struktury pliku scx.service ze strukturą pliku konfiguracyjnego scx_loader.
Jeśli wcześniej używałeś LAVD ze starym scx.service, jak w poniższym przykładzie:
# Lista harmonogramów scx: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Ustaw niestandardowe flagi dla harmonogramuSCX_FLAGS='--performance'Wówczas odpowiednik w pliku konfiguracyjnym scx_loader będzie wyglądał następująco:
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Więcej informacji na temat konfiguracji pliku scx_loader
Postępuj zgodnie z poniższym przewodnikiem, aby łatwo przejść z usługi systemd scx na nowe narzędzie scx_loader.
-
Wyłączanie scx.service na rzecz scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Tworzenie pliku konfiguracyjnego dla scx_loader i dodawanie domyślnej struktury # Edytor Micro utworzy nowy plik.sudo micro /etc/scx_loader.toml# Dodaj następujące linie:default_sched = "scx_bpfland" # Zmień tę linię na harmonogram, który scx_loader ma uruchamiać przy starcie systemudefault_mode = "Auto" # Możliwe wartości: "Auto", "Gaming", "LowLatency", "PowerSave".# Naciśnij CTRL + S, aby zapisać zmiany i CTRL + Q, aby wyjść z Micro. -
Ponowne uruchamianie scx_loader systemctl restart scx_loader.service- Gotowe, scx_loader załaduje i uruchomi teraz wybrany harmonogram.
Debugowanie w scx_loader
Dział zatytułowany „Debugowanie w scx_loader”-
Sprawdzanie statusu usługi systemctl status scx_loader.service -
Wyświetlanie wszystkich wpisów dziennika usługi journalctl -u scx_loader.service -
Wyświetlanie logów tylko z bieżącej sesji. journalctl -u scx_loader.service -b 0
Aby uzyskać bardziej szczegółowy log, wykonaj następujące kroki.
-
Edytuj plik usługi sudo systemctl edit scx_loader.service -
Dodaj następującą linię w sekcji [Service] Environment=RUST_LOG=trace -
Uruchom ponownie usługę sudo systemctl restart scx_loader.service - Sprawdź ponownie logi, aby uzyskać bardziej szczegółowe informacje do debugowania.
Dlaczego harmonogram X działa gorzej niż inny?
Dział zatytułowany „Dlaczego harmonogram X działa gorzej niż inny?”- Jest wiele zmiennych, które należy wziąć pod uwagę podczas ich porównywania. Na przykład, jak mierzą wagę zadania? Czy priorytetyzują zadania interaktywne nad nieinteraktywnymi? Ostatecznie zależy to od ich założeń projektowych.
Dlaczego wszyscy mówią, że harmonogram X jest najlepszy w przypadku Y, ale u mnie nie działa tak dobrze?
Dział zatytułowany „Dlaczego wszyscy mówią, że harmonogram X jest najlepszy w przypadku Y, ale u mnie nie działa tak dobrze?”- Podobnie jak w poprzedniej odpowiedzi, wybór procesora i jego konstrukcja, taka jak układ rdzeni, sposób współdzielenia pamięci podręcznej między rdzeniami i inne powiązane czynniki, mogą prowadzić do mniej wydajnej pracy harmonogramu.
- Dlatego posiadanie wyboru jest jedną z głównych zalet frameworka sched-ext, więc nie bój się próbować i sprawdzać, co działa najlepiej w Twoim przypadku.
Przykłady: stabilność FPS, maksymalna wydajność, responsywność pod intensywnym obciążeniem itp.
Zastosowania tych harmonogramów są dość podobne… dlaczego tak jest?
Dział zatytułowany „Zastosowania tych harmonogramów są dość podobne… dlaczego tak jest?”Głównie dlatego, że są to harmonogramy wielozadaniowe, co oznacza, że mogą obsługiwać różnorodne obciążenia, nawet jeśli nie celują w każdym obszarze.
- Aby ustalić, który harmonogram jest dla Ciebie najlepszy, nie ma lepszej rady niż wypróbowanie go samemu.
Dlaczego brakuje mi harmonogramu, o którym niektórzy użytkownicy wspominają lub który testują na serwerze Discord CachyOS?
Dział zatytułowany „Dlaczego brakuje mi harmonogramu, o którym niektórzy użytkownicy wspominają lub który testują na serwerze Discord CachyOS?”Upewnij się, że używasz najnowszej, rozwojowej wersji pakietu scx-scheds o nazwie scx-scheds-git
- Jednym z powodów może być to, że ten harmonogram jest bardzo nowy i jest obecnie testowany przez użytkowników, dlatego nie został jeszcze dodany do pakietu
scx-scheds-git.
Dlaczego harmonogram nagle się zawiesił? Czy jest niestabilny?
Dział zatytułowany „Dlaczego harmonogram nagle się zawiesił? Czy jest niestabilny?”- Może być kilka powodów, dlaczego tak się stało:
- Jednym z najczęstszych powodów jest używanie ananicy-cpp jednocześnie z harmonogramem. Dlatego dodaliśmy to ostrzeżenie
- Innym powodem może być to, że obciążenie, które uruchamiałeś, przekroczyło limity i możliwości harmonogramu, powodując jego zatrzymanie.
- Przykład nierozsądnego obciążenia:
hackbench
- Przykład nierozsądnego obciążenia:
- Lub bardziej oczywisty powód: znalazłeś błąd w harmonogramie. Jeśli tak, zgłoś go jako problem w ich GitHubie lub poinformuj ich
o tym na kanale Discord CachyOS
sched-ext
Używałem wcześniej scx_loader w GUI Menedżera Jądra. Czy nadal muszę postępować zgodnie z krokami przejścia?
Dział zatytułowany „Używałem wcześniej scx_loader w GUI Menedżera Jądra. Czy nadal muszę postępować zgodnie z krokami przejścia?”- W tym konkretnym przypadku nie, nie jest to konieczne, ponieważ Menedżer Jądra już obsługuje proces przejścia.
- Chyba że wcześniej dodałeś niestandardowe flagi w
/etc/default/scxi nadal chcesz ich używać.
- Chyba że wcześniej dodałeś niestandardowe flagi w
Dowiedz się więcej
Dział zatytułowany „Dowiedz się więcej”- Playlista YT o Sched_ext
- LWN: Rozszerzalna klasa harmonogramu (Luty, 2023)
- Blog arighi: Zaimplementuj własny harmonogram CPU jądra w Ubuntu za pomocą sched_ext (Lipiec, 2023)
- Wykład Davida Verneta: Kernel Recipes 2023 - sched_ext: wtyczkowe planowanie w jądrze Linux (Wrzesień, 2023)
- Blog Changwoo: sched_ext: rozszerzalna klasa harmonogramu za pomocą BPF (Część 1) (Grudzień, 2023)
- Blog arighi: Pierwsze kroki z rozwojem sched_ext (Kwiecień, 2024)
- Blog Changwoo: sched_ext: architektura i interfejsy harmonogramu (Część 2) (Czerwiec, 2024)
- Kanał YT arighi: Demo harmonogramu Linux scx_bpfland: świadomość topologii (Sierpień, 2024)
- Wykład Davida Verneta: Kernel Recipes 2024 - Planowanie z supermocami: Używanie sched_ext do uzyskania dużych zysków wydajności (Wrzesień, 2024)