Tutoriel sched-ext
La classe d’ordonnanceur extensible (mieux connue sous le nom de sched-ext) est une fonctionnalité du noyau Linux qui permet d’implémenter des ordonnanceurs de threads du noyau en
BPF (Berkeley Package Filter) et de les charger dynamiquement. Essentiellement, cela permet aux utilisateurs finaux de changer leurs ordonnanceurs dans l’espace utilisateur sans
avoir besoin de recompiler un autre noyau juste pour avoir un ordonnanceur différent.
-
Les ordonnanceurs se trouvent dans les paquets
scx-schedsetscx-scheds-git.Terminal window # Branche stable + outils scx_loader et scxctl.sudo pacman -S scx-scheds scx-tools# Branche de pointe (Cette branche inclut les derniers changements de la branche master.) + outils scx_loader et scxctl.sudo pacman -S scx-scheds-git scx-tools-git
Comment lancer et gérer l’ordonnanceur
Section intitulée « Comment lancer et gérer l’ordonnanceur »- Pour démarrer l’ordonnanceur, ouvrez votre terminal et entrez la commande suivante :
Exemple de démarrage de rusty sudo scx_rusty
Cela lancera l’ordonnanceur rusty et détachera l’ordonnanceur par défaut.
Pour arrêter l’ordonnanceur. Appuyez sur CTRL + C ; l’ordonnanceur sera alors arrêté et l’ordonnanceur par défaut du noyau reprendra le contrôle.
scxctl est un client DBUS en ligne de commande pour interagir avec scx_loader.
- Fonctionnalités :
- Obtenir l’ordonnanceur et le mode actuels
- Lister tous les ordonnanceurs disponibles
- Démarrer un ordonnanceur dans un mode donné, ou avec des arguments donnés
- Basculer entre les ordonnanceurs et les modes
- Arrêter l’ordonnanceur en cours d’exécution
- Redémarrer l’ordonnanceur en cours d’exécution
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUsage: scxctl <COMMAND>
Commands: get Get the info on the running scheduler list List all supported schedulers start Start a scheduler in a mode or with arguments switch Switch schedulers or modes, optionally with arguments stop Stop the current scheduler restart Restart the current scheduler with original configuration restore Restore the default scheduler from configuration help Print this message or the help of the given subcommand(s)
Options: -h, --help Print help -V, --version Print versionComme son nom l’indique, c’est un utilitaire qui fonctionne comme un chargeur et un gestionnaire pour le framework sched-ext en utilisant l’interface D-Bus.
Bien qu’il не nécessite pas systemd, il peut tout de même être utilisé conjointement avec lui. Consultez le guide de transition pour référence.
- A la capacité d’arrêter, démarrer, redémarrer, lire des informations sur un ordonnanceur scx et plus encore.
- Vous pouvez utiliser des outils comme
dbus-sendougdbuspour communiquer avec lui.
- Vous pouvez utiliser des outils comme
- Ce guide explique comment utiliser scx_loader avec la commande dbus-send.
-
Démarrage de scx_rusty avec ses arguments par défaut dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Démarrage d'un ordonnanceur avec des arguments # Cet exemple démarre scx_bpfland avec les options suivantes : -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Arrêt de l'ordonnanceur en cours d'exécution dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Passer à l'ordonnanceur par défaut # scx_loader passera à l'ordonnanceur par défaut défini dans le fichier de configuration de scx_loaderdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Passage à un autre ordonnanceur en Mode 2 dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# Ceci passe à scx_lavd avec le mode d'ordonnancement 2, ce qui signifie qu'il démarre LAVD en mode économie d'énergie -
Passage à un autre ordonnanceur avec des arguments dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Obtention de l'ordonnanceur en cours d'exécution dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Obtention d'une liste des ordonnanceurs pris en charge dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Vous pouvez y accéder et les configurer via le bouton sched-ext scheduler config.
SCX Manager est un outil GUI autonome dérivé du CachyOS Kernel Manager. Il permet aux utilisateurs de gérer le framework sched-ext et ses ordonnanceurs via scx_loader.
Fonctionnalités :
- Vérifier quel ordonnanceur est actuellement actif
- Sélectionner un ordonnanceur ou un profil : (Auto, Gaming, Économie d’énergie, Faible latence ou Serveur)
- Définir des options supplémentaires
- Désactiver l’ordonnanceur actuel
Capture d’écran

Guide du planificateur : Profils et cas d’utilisation
Section intitulée « Guide du planificateur : Profils et cas d’utilisation »Étant donné le grand nombre de planificateurs disponibles, nous souhaitons vous présenter brièvement ceux qui sont à votre disposition.
N’hésitez pas à signaler tout problème ou à donner votre avis sur le dépôt de chaque planificateur.
Utilisez scx_nomduplanificateur --help pour voir les options disponibles et une brève description de ce qu’elles font.
scx_rusty --helpDéveloppé par : Andrea Righi (arighi GitHub)
Prêt pour la production ?
Un planificateur sched_ext basé sur le vruntime qui priorise les charges de travail interactives. Très flexible et facile à adapter.
Lorsque Bpfland prend des décisions sur les cœurs à utiliser, il prend en considération leur configuration de cache et les cœurs qui partagent le même cache L2/L3, ce qui entraîne moins d’échecs de cache et donc plus de performance.
- Cas d’utilisation :
- Jeux vidéo
- Utilisation bureautique
- Production multimédia/audio
- Grande interactivité sous des charges de travail intensives
- Économie d’énergie
- Serveur
Modes du planificateur
Section intitulée « Modes du planificateur »Faible Latence
Section intitulée « Faible Latence »- Options de ligne de commande :
-m performance -w - Description : Vise à réduire la latence au détriment du débit. Convient aux applications temps réel souples comme le traitement audio et le multimédia.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
-s 20000 -m powersave -I 100 -t 100 - Description : Priorise l’efficacité énergétique. Favorise les cœurs moins performants (par ex. les E-cores sur Intel).
- Options de ligne de commande :
-s 20000 -S - Description : Priorise les tâches avec une affinité stricte. Cette option peut augmenter le débit au détriment de la latence et est plus adaptée aux charges de travail de serveur.
Développé par : Andrea Righi (arighi GitHub)
Prêt pour la production ?
scx_beerland est un planificateur conçu pour prioriser la localité et la scalabilité.
Il priorise le maintien des tâches sur le même CPU pour préserver la localité du cache, tout en assurant une bonne scalabilité sur de nombreux CPUs en utilisant des DSQ locaux (files d’attente par CPU) lorsque le système n’est pas saturé.
- Cas d’utilisation :
- Charges de travail intensives en cache
- Systèmes avec un grand nombre de CPUs
- Jeux vidéo : Il est connu pour fonctionner étonnamment bien dans certains jeux, bien que les résultats puissent varier
- Serveur : Bon pour les charges de travail de serveur à usage général en raison de ses optimisations de scalabilité et de localité.
- Peut également être utilisé pour une utilisation bureautique.
Modes du planificateur
Section intitulée « Modes du planificateur »Aucun pour le moment.
Développé par : Andrea Righi (arighi GitHub)
Prêt pour la production ?
Pour les scénarios de production critiques en termes de performance, d’autres planificateurs sont susceptibles d’offrir de meilleures performances, car le déport de toutes les décisions de planification vers l’espace utilisateur a un certain coût (même s’il est minime).
Cependant, un planificateur entièrement implémenté en espace utilisateur offre le potentiel d’une intégration transparente avec des bibliothèques sophistiquées, des outils de traçage, des services externes (par ex., l’IA), etc.
Par conséquent, il peut y avoir des situations où les avantages l’emportent sur la surcharge, justifiant l’utilisation de ce planificateur dans un environnement de production.
Partage des similitudes avec bpfland, conçu dans l’intention d’être facile à lire et à comprendre grâce à son implémentation en espace utilisateur.
Gardez à l’esprit qu’il y a un léger désavantage de débit lors de l’utilisation d’un planificateur en espace utilisateur.
- Cas d’utilisation :
- Charges de travail à faible latence (Jeux vidéo, visioconférences et streaming en direct)
- Utilisation bureautique
Développé par : Andrea Righi (arighi GitHub)
Prêt pour la production ?
Un planificateur qui se concentre sur l’équité entre les tâches et la prévisibilité des performances.
Il fonctionne selon une politique earliest deadline first (EDF), où chaque tâche se voit attribuer un poids de “latence”. Ce poids est ajusté dynamiquement en fonction de la fréquence à laquelle une tâche libère le CPU avant la fin de son quantum de temps.
Les tâches qui libèrent le CPU prématurément reçoivent un poids de latence plus élevé, les priorisant par rapport aux tâches qui consomment entièrement leur quantum de temps.
- Cas d’utilisation :
- Jeux vidéo
- Charges de travail sensibles à la latence telles que le multimédia ou le traitement audio en temps réel
- Besoin de réactivité dans des situations de surcharge
- Constance des performances
- Serveur
Modes du planificateur
Section intitulée « Modes du planificateur »Faible Latence
Section intitulée « Faible Latence »- Options de ligne de commande :
-m performance -w -C 0 - Description : Vise à réduire la latence au détriment du débit. Convient aux applications temps réel souples comme le traitement audio et le multimédia.
Jeux vidéo
Section intitulée « Jeux vidéo »- Options de ligne de commande :
-m all - Description : Optimise pour une haute performance dans les jeux.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Description : Priorise l’efficacité énergétique. Favorise les cœurs moins performants (par ex., les E-cores sur Intel) et introduit un cycle d’inactivité forcé toutes les 10 ms pour augmenter les économies d’énergie.
- Options de ligne de commande :
-m all -s 20000 -S 1000 -I -1 -D -L - Description : Réglé pour les charges de travail de serveur. Échange la réactivité contre le débit.
Développé par : Andrea Righi (arighi GitHub)
- Prêt pour la production ?
Planificateur léger optimisé pour préserver la localité tâche-CPU.
Lorsque le système n’est pas saturé, le planificateur priorise le maintien des tâches sur le même CPU en utilisant des DSQ locaux. Cela maintient non seulement la localité, mais réduit également la contention de verrouillage par rapport aux DSQ partagés, permettant une bonne scalabilité sur de nombreux CPUs.
- Cas d’utilisation :
- Planificateur à usage général : le planificateur devrait s’adapter aussi bien aux charges de travail de serveur qu’à celles de bureau.
Modes du planificateur
Section intitulée « Modes du planificateur »- Options de ligne de commande :
-d - Description : Désactive les réveils différés. Réduit le débit et les performances pour certaines charges de travail tout en diminuant la consommation d’énergie.
Jeux vidéo
Section intitulée « Jeux vidéo »- Options de ligne de commande :
-c 0 -p 0 - Description : Désactive le suivi de la charge du CPU et impose toujours une planification basée sur l’échéance pour améliorer la réactivité.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
-m powersave -d -p 5000 - Description : Priorise l’efficacité énergétique. Favorise les cœurs moins performants (par ex., les E-cores sur Intel) et désactive les réveils différés, réduisant le débit tout en augmentant l’efficacité énergétique. La consultation de la charge du CPU est augmentée à 5 ms.
Faible Latence
Section intitulée « Faible Latence »- Options de ligne de commande :
-m performance -c 0 -p 0 -w - Description : Vise à réduire la latence au détriment du débit. Convient aux applications temps réel souples comme le traitement audio et le multimédia. Impose toujours une planification basée sur l’échéance et des optimisations de réveil synchrone pour améliorer la prévisibilité des performances.
- Options de ligne de commande :
-s 20000 - Description : Active l’affinité d’espace d’adressage pour améliorer la localité et les performances dans certaines charges de travail sensibles au cache. La consultation est augmentée à 20 ms.
Développé par : Changwoo Min (multics69 GitHub).
- Prêt pour la production ?
Brève introduction à LAVD par Changwoo :
LAVD est un nouvel algorithme de planification qui est encore en développement. Il est motivé par les charges de travail de jeu, qui sont critiques en termes de latence et intensives en communication. Il vise à minimiser les pics de latence tout en maintenant un bon débit global et une utilisation équitable du temps CPU entre les tâches.
- Cas d’utilisation :
- Jeux vidéo
- Production Audio
- Charges de travail sensibles à la latence
- Utilisation bureautique
- Grande interactivité sous des charges de travail intensives
- Économie d’énergie
L’une des capacités principales et impressionnantes de LAVD est le Compactage des Cœurs, ce qui, sans entrer dans les détails techniques : Lorsque l’utilisation du CPU est < 50%, les cœurs actuellement actifs fonctionneront plus longtemps et à une fréquence plus élevée. Pendant ce temps, les cœurs inactifs resteront en C-State (veille) pendant une durée beaucoup plus longue, ce qui permet de réduire la consommation d’énergie globale.
Modes du planificateur
Section intitulée « Modes du planificateur »Jeux vidéo & Faible Latence
Section intitulée « Jeux vidéo & Faible Latence »- Options de ligne de commande :
--performance - Description : Maximise les performances en utilisant tous les cœurs disponibles, en priorisant les cœurs physiques.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
--powersave - Description : Minimise la consommation d’énergie tout en maintenant des performances raisonnables. Priorise les cœurs et les threads efficaces par rapport aux cœurs physiques.
Développé par : David Vernet (Byte-Lab GitHub)
- Prêt pour la production ?
- Oui. S’il est correctement réglé.
Rusty offre une large gamme de fonctionnalités qui améliorent ses capacités, offrant une plus grande flexibilité pour divers cas d’utilisation. L’une de ces fonctionnalités est la possibilité de le régler, vous permettant de personnaliser Rusty en fonction de vos préférences et de vos besoins spécifiques.
- Cas d’utilisation :
- Jeux vidéo
- Charges de travail sensibles à la latence
- Utilisation bureautique
- Production multimédia/audio
- Grande interactivité sous des charges de travail intensives
- Économie d’énergie
- Prêt pour la production ?
- Oui. S’il est correctement réglé pour votre charge de travail et votre matériel spécifiques.
Développé par : Daniel Hodges (hodgesds GitHub)
Un planificateur à usage général qui se concentre sur l’équilibrage de charge “pick two” entre les LLCs. Maintient une haute localité de cache et la conservation du travail tout en offrant une latence raisonnable.
- Cas d’utilisation :
- Serveur
- Environnements de bureau
- Jeux vidéo (avec quelques réglages manuels)
Modes du planificateur
Section intitulée « Modes du planificateur »Jeux vidéo
Section intitulée « Jeux vidéo »- Options de ligne de commande :
--task-slice true -f --sched-mode performance - Description : Améliore la constance des performances de jeu et augmente la tendance à planifier sur les cœurs les plus performants.
Faible Latence
Section intitulée « Faible Latence »- Options de ligne de commande :
-y -f --task-slice true - Description : Réduit la latence en faisant en sorte que les tâches interactives restent davantage sur le CPU qui leur a été assigné et en augmentant la stabilité du quantum de temps.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
--sched-mode efficiency - Description : Améliore l’efficacité énergétique en priorisant les cœurs économes en énergie.
- Options de ligne de commande :
--keep-running - Description : Améliore les charges de travail de serveur en permettant aux tâches de s’exécuter au-delà de leur quantum si le CPU est inactif.
Développé par : Andrea Righi (arighi Github)
- Prêt pour la production ?
- Ce planificateur est encore expérimental et n’est pas recommandé pour une utilisation en production.
scx_tickless est un planificateur orienté serveur conçu pour le cloud computing, la virtualisation et les charges de travail de calcul haute performance.
Le planificateur fonctionne en routant tous les événements de planification à travers un pool de CPUs primaires assignés à la gestion de ces événements. Cela permet de désactiver le tick du planificateur sur les autres CPUs, réduisant ainsi le bruit du système d’exploitation.
- Cas d’utilisation :
- Cloud computing
- Virtualisation
- Charges de travail de calcul haute performance
- Serveur
Modes du planificateur
Section intitulée « Modes du planificateur »Jeux vidéo
Section intitulée « Jeux vidéo »- Options de ligne de commande :
-f 5000 -s 5000 - Description : Améliore les performances de jeu en augmentant la fréquence à laquelle le planificateur détecte la contention du CPU et déclenche des changements de contexte avec un quantum de temps plus court.
Économie d’Énergie
Section intitulée « Économie d’Énergie »- Options de ligne de commande :
-f 50 - Description : Améliore l’efficacité énergétique en réduisant les vérifications de contention.
Faible Latence
Section intitulée « Faible Latence »- Options de ligne de commande :
-f 5000 -s 1000 - Description : Similaire au profil de jeu mais avec un quantum encore plus réduit.
- Options de ligne de commande :
-f 100 - Description : Réduit la fréquence à laquelle le planificateur vérifie la contention du CPU pour améliorer le débit au détriment de la réactivité.
Configuration et tests de performance
Section intitulée « Configuration et tests de performance »LAVD Autopilot & Autopower
Section intitulée « LAVD Autopilot & Autopower »Citations de Changwoo Min :
-
En mode pilote automatique, l’ordonnanceur ajuste son mode d’énergie (
Powersave,BalancedouPerformance) en fonction de la charge du système, plus précisément l’utilisation du CPU. -
Autopower : Décide automatiquement du mode d’énergie de l’ordonnanceur en fonction du profil énergétique du système, alias EPP (Energy Performance Preference).
# Autopower peut être activé par le drapeau suivant :--autopower# par ex. :scx_lavd --autopowerananicy-cpp & sched-ext
Section intitulée « ananicy-cpp & sched-ext »Pour désactiver/arrêter ananicy-cpp, exécutez la commande suivante :
systemctl disable --now ananicy-cppChangement de profil d’alimentation de scx_loader
Section intitulée « Changement de profil d’alimentation de scx_loader »Implémenté dans le paquet power-profiles-daemon fourni par CachyOS, qui inclut un patch personnalisé pour prendre en charge le changement de profil d’alimentation de scx_loader.
- Si
scx_loaderest en cours d’exécution, lorsque game-performance est utilisé, il basculera automatiquement l’ordonnanceur actif sur le profilGamingau lancement d’un jeu, et reviendra au profil par défaut lorsque le jeu est fermé. - Lors du changement entre les profils d’alimentation, par exemple dans KDE Plasma ou GNOME via le sélecteur de profil d’alimentation,
scx_loaderbasculera automatiquement vers le profil d’ordonnanceur correspondant :
| Power Profile | Scheduler Profile |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Benchmarking et comparaison des ordonnanceurs avec cachyos-benchmarker
Section intitulée « Benchmarking et comparaison des ordonnanceurs avec cachyos-benchmarker »L’outil cachyos-benchmarker offre un moyen simple d’évaluer et de comparer les performances des différents ordonnanceurs de CPU.
Il exécute une suite complète de benchmarks pour mesurer les performances du CPU, de la mémoire et du système global sous diverses charges de travail.
Les benchmarks suivants sont inclus :
| Test | Mesure | Outil |
|---|---|---|
| stress-ng cpu-cache-mem | Performances CPU, cache et mémoire | stress-ng |
| Compilation FFmpeg | Performances de compilation parallèle | make |
| Encodage x265 | Débit d’encodage vidéo | x265 |
| Hachage argon2 | Hachage de mot de passe multithread | argon2 |
| perf sched msg | Changement de contexte et performance IPC | perf |
| perf memcpy | Débit mémoire memcpy() |
perf |
| Calcul de nombres premiers | Arithmétique entière et parallélisme | primesieve |
| NAMD | Dynamique moléculaire (charge de travail scientifique) | namd3 |
| Rendu Blender | Rendu 3D uniquement sur CPU | blender |
| Compression xz | Débit de compression | xz |
| Compilation Kernel defconfig | Performances de compilation du noyau | make |
| y-cruncher | Précision mathématique et stress mémoire | y-cruncher |
cachyos-benchmarker peut être utilisé à plusieurs fins, notamment :
- Tester la stabilité de l’ordonnanceur
Exécuter la suite de benchmarks complète pour détecter les blocages, les plantages ou les régressions introduits par les modifications de l’ordonnanceur.
Si vous utilisez
scx_loader, vous pouvez collecter les journaux en cas de blocage ou de plantage avec :Cela créera un fichier nomméTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logdans votre répertoire actuel. - Comparer les performances des ordonnanceurs
- Évaluer les différences de performance entre les ordonnanceurs. Par ex.
BPFLAND vs LAVD
- Évaluer les différences de performance entre les ordonnanceurs. Par ex.
- Mesurer l’effet des mises à jour du noyau ou de l’ordonnanceur
- Comparer les exécutions avant and après l’application de correctifs ou de changements de version pour vérifier les régressions ou les améliorations de performance.
- Tester les ajustements de configuration
- Évaluer l’impact des changements tels que les paramètres du gouverneur CPU, l’activation/désactivation du SMT, ou les drapeaux modifiés de l’ordonnanceur.
Prérequis
Section intitulée « Prérequis »- 4 Go de RAM ou plus
- Au moins 8 Go d’espace de stockage libre
- Du temps et de la patience - le benchmark complet peut prendre plus d’une heure sur les systèmes plus lents
Installation
Section intitulée « Installation »Pour installer cachyos-benchmarker, exécutez la commande suivante :
sudo pacman -S cachyos-benchmarkerLancer le benchmark
Section intitulée « Lancer le benchmark »- Exécutez
cachyos-benchmarker:Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# Vous pouvez remplacer ~/cachyos-benchmarker/ par n'importe quel répertoire où vous souhaitez enregistrer les journaux. - Attendez que les étapes de préparation se terminent.
- Suivez les instructions :
Do you want to drop page cache now? Root privileges needed! (y/N) y(Voulez-vous vider le cache des pages maintenant ? Privilèges root requis ! (o/N) o)Please enter a name for this run, or leave empty for default:(Veuillez entrer un nom pour cette exécution, ou laisser vide pour le nom par défaut :)
- Attendez la fin des tests.
- Une fois terminé, voici ce qui se passera :
- Création d’un fichier journal avec un nom comme
benchie_<nom>_<DATE>.logqui contient des informations détaillées sur l’exécution du benchmark.- Exemple :
benchie_p2dq_2025-09-29-2115.log - Le script
benchmark_scraper.pys’exécutera automatiquement pour générer un rapport de synthèse au format HTML. - Que fait le script ? :
- Lit tous les fichiers
benchie_*.logdans le répertoire spécifié. - Extrait les noms, temps et scores des benchmarks.
- Les trie ou les agrège.
- Affiche un résumé clair des résultats dans votre terminal et crée un fichier HTML qui peut être ouvert dans un navigateur.
Exemple de sortie du terminal :
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1Exemple HTML d’un résultat de test comparant deux branches différentes du même ordonnanceur :
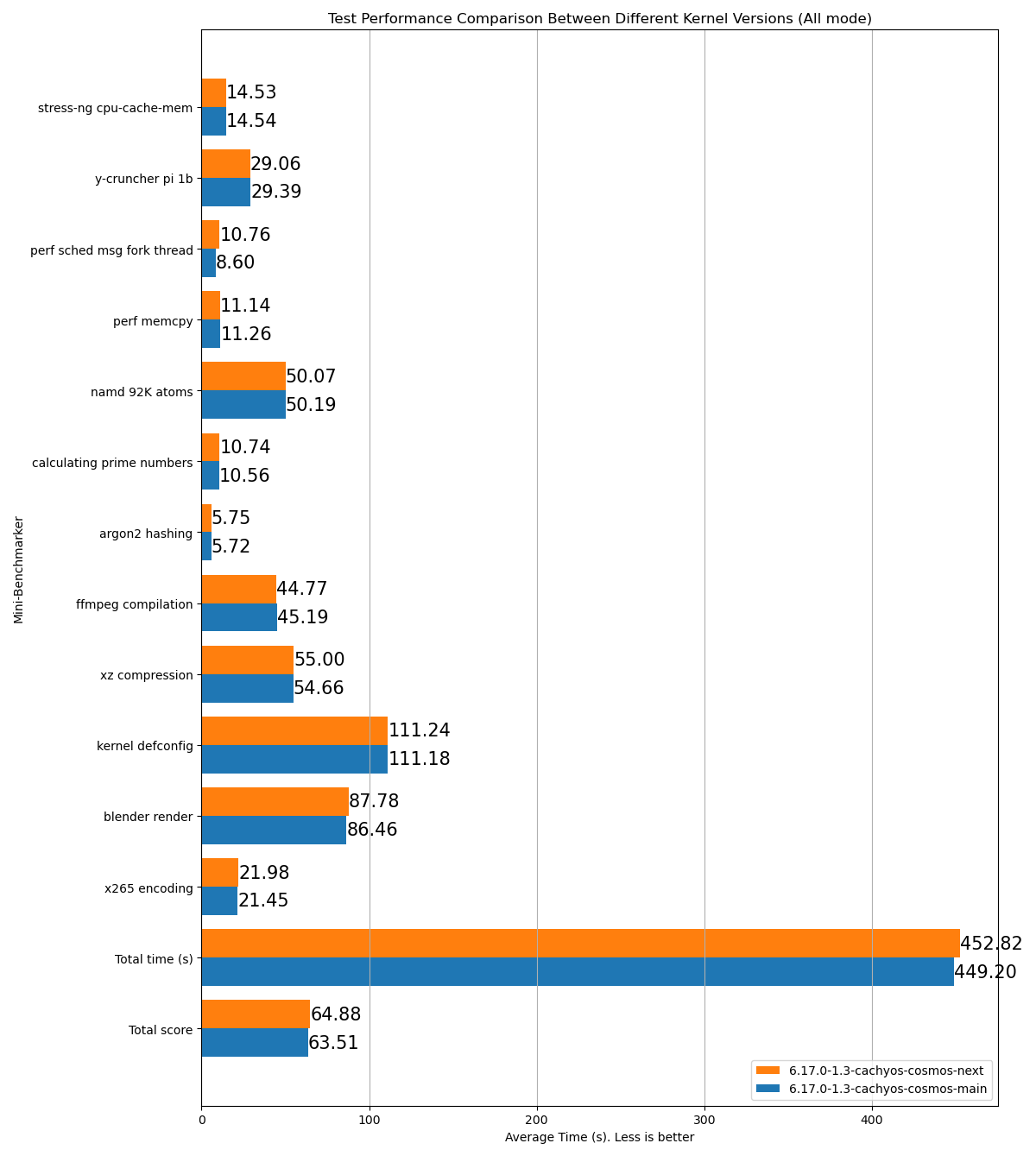
- Lit tous les fichiers
- Exemple :
- Création d’un fichier journal avec un nom comme
- Pour comparer deux exécutions ou plus, placez les fichiers
.logdans le même répertoire avant de lancerbenchmark_scraper.py. L’outil les détectera et les comparera automatiquement dans le rapport HTML.
Tester la latence de l’ordonnanceur avec schbench
Section intitulée « Tester la latence de l’ordonnanceur avec schbench »schbench est un benchmark d’ordonnanceur conçu pour mesurer la latence de l’ordonnancement dans une simulation de charge de travail de type serveur. Il crée un nombre configurable de threads “workers” (travailleurs) et “messages”, où les messages réveillent à plusieurs reprises les workers. En mesurant la distribution de la latence entre le réveil et l’exécution de ces threads workers, il fournit un aperçu critique de la capacité d’un noyau à gérer les réveils de threads, l’équilibrage et la contention du CPU, en particulier sous charge.
Cas d’utilisation
Section intitulée « Cas d’utilisation »Vous pouvez utiliser schbench pour :
- Évaluer la latence de l’ordonnanceur : Identifier à quelle vitesse les threads sont ordonnancés après leur réveil.
- Comparer les performances de réveil entre les ordonnanceurs : Détecter les améliorations ou les régressions dans la commutation de contexte et la latence de réveil.
- Tester l’effet des correctifs du noyau ou de l’ordonnanceur : Évaluer si les réglages ou les mises à jour affectent l’équité et la réactivité de l’ordonnancement.
Installation
Section intitulée « Installation »schbench est disponible dans les dépôts CachyOS :
sudo pacman -S schbenchLancer le benchmark
Section intitulée « Lancer le benchmark »Une manière simple de lancer schbench pour un test de latence général est :
schbench -m 2 -t 8 -r 60Cet exemple exécute :
- 2 threads de message (
-m 2) - 8 threads workers par thread de message (
-t 8) - pendant une durée totale de 60 secondes (
-r 60)
Vous pouvez ajuster ces valeurs en fonction du nombre de cœurs de votre CPU et du niveau de charge souhaité.
Voici un tableau expliquant certaines des options clés :
| Option | Description |
|---|---|
-C, --calibrate |
Exécute la calibration et rapporte le temps (pas de benchmark). |
-L, --no-locking |
Désactive les spinlocks pendant le travail du CPU (par défaut : verrouillage activé). |
-m, --message-threads <n> |
Nombre de threads de message (par défaut : 1). |
-t, --threads <n> |
Threads workers par thread de message (par défaut : nombre de CPU). |
-r, --runtime <sec> |
Durée du benchmark (par défaut : 30). |
-F, --cache_footprint <KB> |
Taille de l’empreinte cache (par défaut : 256). |
-n, --operations <count> |
Nombre d’opérations de “temps de réflexion” à effectuer (par défaut : 5). |
-A, --auto-rps |
Augmente automatiquement le RPS jusqu’à ce que la cible d’utilisation du CPU soit atteinte. |
-R, --rps <count> |
Mode requêtes par seconde. |
-p, --pipe <bytes> |
Simule un test de transfert par pipe. |
-w, --warmuptime <sec> |
Durée de préchauffage avant de collecter les statistiques (par défaut : 0). |
-i, --intervaltime <sec> |
Intervalle pour afficher les latences (par défaut : 10). |
-z, --zerotime <sec> |
Intervalle pour remettre à zéro les statistiques de latence (par défaut : jamais). |
Comprendre la sortie
Section intitulée « Comprendre la sortie »Après chaque exécution, schbench affiche les percentiles de latence comme :
Exemple de sortie
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Comment interpréter les résultats
Section intitulée « Comment interpréter les résultats »- Latences de réveil (Wakeup Latencies) :
- Mesure la rapidité avec laquelle les threads se réveillent après avoir été signalés.
- Des valeurs plus basses ici (surtout le 99e percentile) signifient que l’ordonnanceur est plus réactif.
- Mesure la rapidité avec laquelle les threads se réveillent après avoir été signalés.
- Latences des requêtes (Request Latencies) :
- Représente le temps nécessaire pour compléter les requêtes entre les threads.
- Une latence plus faible indique une meilleure communication inter-threads et une meilleure efficacité de l’ordonnancement.
- Représente le temps nécessaire pour compléter les requêtes entre les threads.
- RPS (Requêtes Par Seconde) :
- Montre le débit soutenu :
- Un RPS moyen plus élevé indique que l’ordonnanceur peut gérer plus de travail par seconde avec la configuration donnée.
- Montre le débit soutenu :
En conclusion :
- Un bon ordonnanceur affichera de faibles latences de réveil et de requête avec un RPS constant.
- Un ordonnanceur moins efficace pourrait présenter des pics de latence élevés ou des valeurs de RPS instables dans le temps.
Recommandations pour le benchmarking des jeux
Section intitulée « Recommandations pour le benchmarking des jeux »Si votre souhait est de benchmarker des jeux pour comparer les performances des différents ordonnanceurs, voici quelques conseils pour obtenir les résultats les plus précis :
- Utilisez les benchmarks intégrés : De nombreux jeux modernes sont livrés avec des outils de benchmarking intégrés. Ceux-ci sont conçus pour fournir des résultats cohérents en exécutant la même séquence d’événements à chaque fois.
- Consultez ce site web pour une liste de jeux qui incluent des benchmarks intégrés.
- Paramètres cohérents : Assurez-vous que les paramètres du jeu (résolution, qualité graphique, etc.) sont les mêmes pour chaque test.
- Fermez les applications en arrière-plan : D’autres applications fonctionnant en arrière-plan peuvent affecter les performances. Fermez les programmes inutiles pour minimiser leur impact.
- Si vous n’utilisez pas un benchmark intégré, essayez d’effectuer les mêmes actions dans le jeu pour chaque test. Cela peut inclure de suivre le même chemin, de s’engager dans des scénarios de combat similaires ou d’effectuer les mêmes tâches.
- Le simple fait de ne pas viser le même endroit peut entraîner des résultats de performance différents.
- Plusieurs exécutions : Effectuez plusieurs exécutions du benchmark et prenez la moyenne pour tenir compte de la variabilité.
- Utilisez des outils de suivi des performances : Des outils comme MangoHud ou GOverlay peuvent fournir des métriques de performance en temps réel telles que les FPS, les temps de trame et l’utilisation du CPU/GPU.
- Profitez des raccourcis clavier ou des macros :
- Un exemple est de créer un raccourci clavier qui vous permet de basculer entre différents ordonnanceurs ou de changer leurs modes à la volée en jeu.
- Cela peut être fait en utilisant un outil comme scxctl ou en créant des scripts personnalisés qui changent l’ordonnanceur actif et son mode.
- Un exemple est de créer un raccourci clavier qui vous permet de basculer entre différents ordonnanceurs ou de changer leurs modes à la volée en jeu.
Télécharger et partager vos benchmarks
Section intitulée « Télécharger et partager vos benchmarks »Ce site web contient une liste de benchmarks réalisés par la communauté utilisant différents ordonnanceurs ou testant divers paramètres.
Pour télécharger vos propres benchmarks, vous devrez lier votre compte Discord au site web, puis vous pourrez soumettre vos propres benchmarks.
Cliquez ensuite sur le bouton New benchmark et remplissez les informations requises.
- Vous pouvez télécharger plusieurs résultats pour le même jeu en utilisant différents ordonnanceurs ou paramètres.
- Accepte les journaux MangoHud et Afterburner.
- Permet la recherche par titre ou description.
Transition de scx.service à scx_loader : Un guide complet
Section intitulée « Transition de scx.service à scx_loader : Un guide complet »Commençons par une comparaison détaillée entre la structure du fichier scx.service et celle du fichier de configuration scx_loader.
Si vous utilisiez précédemment LAVD avec l’ancien scx.service comme dans l’exemple ci-dessous :
# Liste des ordonnanceurs scx_schedulers : scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Définir des options personnalisées pour l'ordonnanceurSCX_FLAGS='--performance'Alors l’équivalent dans le fichier de configuration scx_loader ressemblera à ceci :
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Pour plus d’informations sur la configuration du fichier scx_loader
Suivez le guide ci-dessous pour une transition facile du service systemd scx vers le nouvel utilitaire scx_loader.
-
Désactivation de scx.service au profit de scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Création du fichier de configuration pour scx_loader et ajout de la structure par défaut # L'éditeur Micro va créer un nouveau fichier.sudo micro /etc/scx_loader.toml# Ajoutez les lignes suivantes :default_sched = "scx_bpfland" # Modifiez cette ligne pour l'ordonnanceur que vous voulez que scx_loader démarre au démarragedefault_mode = "Auto" # Valeurs possibles : "Auto", "Gaming", "LowLatency", "PowerSave".# Appuyez sur CTRL + S pour enregistrer les modifications et CTRL + Q pour quitter Micro. -
Redémarrage de scx_loader systemctl restart scx_loader.service- Vous avez terminé, le scx_loader va maintenant charger et démarrer l’ordonnanceur souhaité.
Débogage dans scx_loader
Section intitulée « Débogage dans scx_loader »-
Vérification du statut du service systemctl status scx_loader.service -
Affichage de toutes les entrées de journal du service journalctl -u scx_loader.service -
Affichage uniquement des journaux de la session actuelle. journalctl -u scx_loader.service -b 0
Afin d’obtenir un journal plus détaillé, suivez ces étapes.
-
Modifier le fichier de service sudo systemctl edit scx_loader.service -
Ajouter la ligne suivante sous la section [Service] Environment=RUST_LOG=trace -
Redémarrer le service sudo systemctl restart scx_loader.service - Vérifiez à nouveau les journaux pour des informations de débogage plus détaillées.
Pourquoi l’ordonnanceur X est-il moins performant que l’autre ?
Section intitulée « Pourquoi l’ordonnanceur X est-il moins performant que l’autre ? »- Il y a de nombreuses variables à prendre en compte lors de leur comparaison. Par exemple, comment mesurent-ils le poids d’une tâche ? Donnent-ils la priorité aux tâches interactives par rapport aux tâches non interactives ? En fin de compte, cela dépend de leurs choix de conception.
Pourquoi tout le monde dit que cet ordonnanceur X est le meilleur pour le cas Y, mais il n’est pas aussi performant pour moi ?
Section intitulée « Pourquoi tout le monde dit que cet ordonnanceur X est le meilleur pour le cas Y, mais il n’est pas aussi performant pour moi ? »- Comme pour la réponse précédente, le choix du processeur et sa conception, comme l’agencement des cœurs, la manière dont ils partagent le cache entre les cœurs et d’autres facteurs connexes, peuvent entraîner un fonctionnement moins efficace de l’ordonnanceur.
- C’est pourquoi avoir le choix est l’un des points forts du framework sched-ext, alors n’ayez pas peur d’en essayer un pour voir lequel fonctionne le mieux pour votre cas d’utilisation.
Exemples : stabilité des FPS, performances maximales, réactivité sous des charges de travail intensives, etc.
Les cas d’utilisation de ces ordonnanceurs sont assez similaires… pourquoi ?
Section intitulée « Les cas d’utilisation de ces ordonnanceurs sont assez similaires… pourquoi ? »Principalement parce qu’il s’agit d’ordonnanceurs polyvalents, ce qui signifie qu’ils peuvent gérer une variété de charges de travail, même s’ils n’excellent pas dans tous les domaines.
- Pour déterminer quel ordonnanceur vous convient le mieux, il n’y a pas de meilleur conseil que de l’essayer vous-même.
Pourquoi me manque-t-il un ordonnanceur que certains utilisateurs mentionnent ou testent sur le serveur Discord de CachyOS ?
Section intitulée « Pourquoi me manque-t-il un ordonnanceur que certains utilisateurs mentionnent ou testent sur le serveur Discord de CachyOS ? »Assurez-vous que vous utilisez la version la plus récente du paquet scx-scheds, nommée scx-scheds-git.
- L’une des raisons pourrait être que cet ordonnanceur est très récent et est actuellement en cours de test par les utilisateurs, il n’a donc pas encore été ajouté au paquet
scx-scheds-git.
Pourquoi l’ordonnanceur a-t-il soudainement planté ? Est-il instable ?
Section intitulée « Pourquoi l’ordonnanceur a-t-il soudainement planté ? Est-il instable ? »- Il pourrait y avoir plusieurs raisons à cela :
- L’une des raisons les plus courantes est que vous utilisiez ananicy-cpp en même temps que l’ordonnanceur. C’est pourquoi nous avons ajouté cet avertissement
- Une autre raison pourrait être que la charge de travail que vous exécutiez a dépassé les limites et la capacité de l’ordonnanceur, le faisant caler.
- Exemple de charge de travail déraisonnable :
hackbench
- Exemple de charge de travail déraisonnable :
- Ou la raison la plus évidente, vous avez trouvé un bug dans l’ordonnanceur. Si c’est le cas, veuillez le signaler comme un problème sur leur GitHub ou leur en faire part
sur le canal Discord de CachyOS
sched-ext.
J’ai déjà utilisé scx_loader dans l’interface graphique du gestionnaire de noyau. Dois-je quand même suivre les étapes de transition ?
Section intitulée « J’ai déjà utilisé scx_loader dans l’interface graphique du gestionnaire de noyau. Dois-je quand même suivre les étapes de transition ? »- Dans ce cas particulier, non, ce n’est pas nécessaire car le gestionnaire de noyau gère déjà le processus de transition.
- Sauf si vous avez précédemment ajouté des options personnalisées dans
/etc/default/scxet que vous souhaitez toujours les utiliser.
- Sauf si vous avez précédemment ajouté des options personnalisées dans
En savoir plus
Section intitulée « En savoir plus »- Playlist YT Sched_ext
- LWN: The extensible scheduler class (février, 2023)
- Blog d’arighi : Implement your own kernel CPU scheduler in Ubuntu with sched_ext (juillet, 2023)
- Présentation de David Vernet : Kernel Recipes 2023 - sched_ext: pluggable scheduling in the Linux kernel (septembre, 2023)
- Blog de Changwoo : sched_ext: a BPF-extensible scheduler class (Part 1) (décembre, 2023)
- Blog d’arighi : Getting started with sched_ext development (avril, 2024)
- Blog de Changwoo : sched_ext: scheduler architecture and interfaces (Part 2) (juin, 2024)
- Chaîne YT d’arighi : scx_bpfland Linux scheduler demo: topology awareness (août, 2024)
- Présentation de David Vernet : Kernel Recipes 2024 - Scheduling with superpowers: Using sched_ext to get big perf gains (septembre, 2024)