Tutorial de sched-ext
La Clase de Planificador Extensible (más conocida como sched-ext) es una característica del kernel de Linux que permite implementar planificadores de hilos del kernel en
BPF (Berkeley Packet Filter) y cargarlos dinámicamente. Esencialmente, esto permite a los usuarios finales cambiar sus planificadores en el espacio de usuario sin
la necesidad de compilar otro kernel solo para tener un planificador diferente.
-
Los planificadores se pueden encontrar en los paquetes
scx-schedsyscx-scheds-git.Terminal window # Rama estable + herramientas scx_loader y scxctl.sudo pacman -S scx-scheds scx-tools# Rama de vanguardia (esta rama incluye los últimos cambios de la rama master.) + herramientas scx_loader y scxctl.sudo pacman -S scx-scheds-git scx-tools-git
Cómo Lanzar y Gestionar el Planificador
Sección titulada «Cómo Lanzar y Gestionar el Planificador»- Para iniciar el planificador, abre tu terminal e introduce el siguiente comando:
Ejemplo de cómo iniciar rusty sudo scx_rusty
Esto lanzará el planificador rusty y desvinculará el planificador por defecto.
Para detener el planificador. Presiona CTRL + C y el planificador se detendrá, y el planificador por defecto del kernel tomará el control de nuevo.
scxctl es un cliente CLI de DBUS para interactuar con scx_loader.
- Características:
- Obtener el planificador y modo actual
- Listar todos los planificadores disponibles
- Iniciar un planificador en un modo dado, o con argumentos dados
- Cambiar entre planificadores y modos
- Detener el planificador en ejecución
- Reiniciar el planificador en ejecución
scxctl start --sched flash --mode gamingscxctl stopscxctl restorescxctl switch --sched bpfland --mode gamingscxctl start --sched cosmos --args="-c,75,-m,0-15"scxctl switch --sched flash --args="-s,20000"$ scxctl --helpUsage: scxctl <COMMAND>
Commands: get Get the info on the running scheduler list List all supported schedulers start Start a scheduler in a mode or with arguments switch Switch schedulers or modes, optionally with arguments stop Stop the current scheduler restart Restart the current scheduler with original configuration restore Restore the default scheduler from configuration help Print this message or the help of the given subcommand(s)
Options: -h, --help Print help -V, --version Print versionComo su nombre indica, es una utilidad que funciona como cargador y gestor para el framework sched-ext usando la interfaz D-Bus.
Aunque no requiere systemd, puede utilizarse junto con él. Consulta la guía de transición como referencia.
- Tiene la capacidad de detener, iniciar, reiniciar, leer información sobre un planificador scx y más.
- Puedes usar herramientas como
dbus-sendogdbuspara comunicarte con él.
- Puedes usar herramientas como
- Esta guía explica cómo usar scx_loader con el comando dbus-send.
-
Iniciando scx_rusty con sus argumentos por defecto dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartScheduler string:scx_rusty uint32:0 -
Iniciando un planificador con argumentos # Este ejemplo inicia scx_bpfland con las siguientes flags: -k -c 0dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StartSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Deteniendo el planificador actualmente en ejecución dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.StopScheduler -
Cambiar al planificador por defecto # scx_loader cambiará al planificador por defecto establecido en el archivo de configuración de scx_loaderdbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.RestoreDefault -
Cambiando a otro planificador en Modo 2 dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchScheduler string:scx_lavd uint32:2# Esto cambia a scx_lavd con el modo de planificador 2, lo que significa que inicia LAVD en modo de ahorro de energía -
Cambiando a otro planificador con argumentos dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.scx.Loader.SwitchSchedulerWithArgs string:scx_bpfland array:string:"-k","-c","0" -
Obteniendo el planificador actualmente en ejecución dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:CurrentScheduler -
Obteniendo una lista de los planificadores soportados dbus-send --system --print-reply --dest=org.scx.Loader /org/scx/Loader org.freedesktop.DBus.Properties.Get string:org.scx.Loader string:SupportedSchedulers
-
Puedes acceder y configurarlos a través del botón sched-ext scheduler config.
SCX Manager es una herramienta gráfica independiente derivada del CachyOS Kernel Manager. Permite a los usuarios gestionar el framework sched-ext y sus planificadores a través de scx_loader.
Características:
- Comprobar qué planificador está activo actualmente
- Seleccionar un planificador o perfil: (Auto, Gaming, Ahorro de energía, Baja latencia o Servidor)
- Establecer flags adicionales
- Deshabilitar el planificador actual
Captura de pantalla

Guía de Planificadores: Perfiles y Casos de Uso
Sección titulada «Guía de Planificadores: Perfiles y Casos de Uso»Dado que hay muchos planificadores para elegir, queremos dar una pequeña introducción sobre los planificadores disponibles.
No dudes en reportar cualquier problema o dar tu opinión en el repositorio de cada planificador.
Usa scx_nombredelplanificador --help para ver las opciones disponibles y una breve descripción de lo que hacen.
scx_rusty --helpDesarrollado por: Andrea Righi (arighi GitHub)
¿Listo para producción?
Un planificador de sched_ext basado en vruntime que prioriza las cargas de trabajo interactivas. Altamente flexible y fácil de adaptar.
Al tomar decisiones sobre qué núcleos usar, Bpfland tiene en cuenta su diseño de caché y qué núcleos comparten la misma caché L2/L3, lo que resulta en menos fallos de caché = más rendimiento.
- Casos de uso:
- Videojuegos
- Uso de escritorio
- Producción multimedia/audio
- Gran interactividad bajo cargas de trabajo intensivas
- Ahorro de energía
- Servidor
Modos del Planificador
Sección titulada «Modos del Planificador»Baja Latencia
Sección titulada «Baja Latencia»- Opciones de línea de comandos:
-m performance -w - Descripción: Diseñado para reducir la latencia a costa del rendimiento (throughput). Adecuado para aplicaciones de tiempo real flexible como el procesamiento de audio y multimedia.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
-s 20000 -m powersave -I 100 -t 100 - Descripción: Prioriza la eficiencia energética. Favorece los núcleos menos potentes (por ejemplo, los E-cores en Intel).
Servidor
Sección titulada «Servidor»- Opciones de línea de comandos:
-s 20000 -S - Descripción: Prioriza tareas con afinidad estricta. Esta opción puede aumentar el rendimiento a costa de la latencia y es más adecuada para cargas de trabajo de servidor.
Desarrollado por: Andrea Righi (arighi GitHub)
¿Listo para producción?
scx_beerland es un planificador diseñado para priorizar la localidad y la escalabilidad.
Prioriza mantener las tareas en la misma CPU para conservar la localidad de la caché, al mismo tiempo que asegura una buena escalabilidad en muchos CPUs mediante el uso de DSQs locales (colas de ejecución por CPU) cuando el sistema no está saturado.
- Casos de uso:
- Cargas de trabajo intensivas en caché
- Sistemas con una gran cantidad de CPUs
- Videojuegos: Se sabe que funciona sorprendentemente bien en ciertos juegos, aunque los resultados pueden variar
- Servidor: Bueno para cargas de trabajo de servidor de propósito general debido a sus optimizaciones de escalabilidad y localidad.
- También se puede usar para escritorio.
Modos del Planificador
Sección titulada «Modos del Planificador»Ninguno por el momento.
Desarrollado por: Andrea Righi (arighi GitHub)
¿Listo para producción?
Para escenarios de producción críticos en cuanto a rendimiento, es probable que otros planificadores muestren un mejor desempeño, ya que delegar todas las decisiones de planificación al espacio de usuario tiene un cierto costo (incluso si es mínimo).
Sin embargo, un planificador implementado completamente en el espacio de usuario tiene el potencial de integrarse sin problemas con bibliotecas sofisticadas, herramientas de trazado, servicios externos (por ejemplo, IA), etc.
Por lo tanto, podría haber situaciones en las que los beneficios superen la sobrecarga, justificando el uso de este planificador en un entorno de producción.
Comparte similitudes con bpfland, hecho con la intención de ser fácil de leer y entender cómo funciona debido a su implementación en el espacio de usuario.
Ten en cuenta que hay una ligera desventaja en el rendimiento (throughput) al usar un planificador en el espacio de usuario.
- Casos de uso:
- Cargas de trabajo de baja latencia (Videojuegos, videoconferencias y transmisiones en vivo)
- Uso de escritorio
Desarrollado por: Andrea Righi (arighi GitHub)
¿Listo para producción?
Un planificador que se enfoca en asegurar la equidad entre tareas y la predictibilidad del rendimiento.
Opera utilizando una política de plazo más próximo primero (EDF), donde a cada tarea se le asigna un peso de “latencia”. Este peso se ajusta dinámicamente según la frecuencia con la que una tarea libera la CPU antes de que se agote su porción de tiempo completa.
A las tareas que liberan la CPU antes de tiempo se les da un mayor peso de latencia, priorizándolas sobre las tareas que consumen completamente su porción de tiempo.
- Casos de uso:
- Videojuegos
- Cargas de trabajo sensibles a la latencia como multimedia o procesamiento de audio en tiempo real
- Necesidad de respuesta en situaciones de sobrecarga
- Consistencia en el rendimiento
- Servidor
Modos del Planificador
Sección titulada «Modos del Planificador»Baja Latencia
Sección titulada «Baja Latencia»- Opciones de línea de comandos:
-m performance -w -C 0 - Descripción: Diseñado para reducir la latencia a costa del rendimiento (throughput). Adecuado para aplicaciones de tiempo real flexible como el procesamiento de audio y multimedia.
Videojuegos
Sección titulada «Videojuegos»- Opciones de línea de comandos:
-m all - Descripción: Optimiza para un alto rendimiento en juegos.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
-m powersave -I 10000 -t 10000 -s 10000 -S 1000 - Descripción: Prioriza la eficiencia energética. Favorece los núcleos menos potentes (por ejemplo, E-cores en Intel) e introduce un ciclo de inactividad forzada cada 10 ms para aumentar el ahorro de energía.
Servidor
Sección titulada «Servidor»- Opciones de línea de comandos:
-m all -s 20000 -S 1000 -I -1 -D -L - Descripción: Ajustado para cargas de trabajo de servidor. Intercambia capacidad de respuesta por rendimiento (throughput).
Desarrollado por: Andrea Righi (arighi GitHub)
- ¿Listo para producción?
Planificador ligero optimizado para preservar la localidad tarea-CPU.
Cuando el sistema no está saturado, el planificador prioriza mantener las tareas en la misma CPU usando DSQs locales. Esto no solo mantiene la localidad, sino que también reduce la contención de bloqueos en comparación con los DSQs compartidos, permitiendo una buena escalabilidad en muchos CPUs.
- Casos de uso:
- Planificador de propósito general: el planificador debería adaptarse tanto a cargas de trabajo de servidor como de escritorio.
Modos del Planificador
Sección titulada «Modos del Planificador»Automático
Sección titulada «Automático»- Opciones de línea de comandos:
-d - Descripción: Deshabilita las activaciones diferidas (deferred wakeups). Reduce el rendimiento (throughput) y el desempeño para ciertas cargas de trabajo mientras disminuye el consumo de energía.
Videojuegos
Sección titulada «Videojuegos»- Opciones de línea de comandos:
-c 0 -p 0 - Descripción: Desactiva el seguimiento de la carga de la CPU e impone siempre una planificación basada en plazos para mejorar la capacidad de respuesta.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
-m powersave -d -p 5000 - Descripción: Prioriza la eficiencia energética. Favorece los núcleos menos potentes (por ejemplo, E-cores en Intel) y deshabilita las activaciones diferidas, reduciendo el rendimiento (throughput) mientras aumenta la eficiencia energética. El sondeo de la carga de la CPU se aumenta a 5 ms.
Baja Latencia
Sección titulada «Baja Latencia»- Opciones de línea de comandos:
-m performance -c 0 -p 0 -w - Descripción: Diseñado para reducir la latencia a costa del rendimiento (throughput). Adecuado para aplicaciones de tiempo real flexible como el procesamiento de audio y multimedia. Impone siempre una planificación basada en plazos y optimizaciones de activación síncrona para mejorar la predictibilidad del rendimiento.
Servidor
Sección titulada «Servidor»- Opciones de línea de comandos:
-s 20000 - Descripción: Habilita la afinidad del espacio de direcciones para mejorar la localidad y el rendimiento en ciertas cargas de trabajo sensibles a la caché. El sondeo se aumenta a 20 ms.
Desarrollado por: Changwoo Min (multics69 GitHub).
- ¿Listo para producción?
Breve introducción a LAVD de Changwoo:
LAVD es un nuevo algoritmo de planificación que todavía está en desarrollo. Está motivado por las cargas de trabajo de los videojuegos, que son críticas en latencia y con mucha comunicación. Su objetivo es minimizar los picos de latencia mientras se mantiene un buen rendimiento (throughput) general y un uso justo del tiempo de CPU entre las tareas.
- Casos de uso:
- Videojuegos
- Producción de audio
- Cargas de trabajo sensibles a la latencia
- Uso de escritorio
- Gran interactividad bajo cargas de trabajo intensivas
- Ahorro de energía
Una de las capacidades principales e increíbles que incluye LAVD es la Compactación de Núcleos (Core Compaction), que sin entrar en detalles técnicos: cuando el uso de la CPU es < 50%, los núcleos actualmente activos funcionarán por más tiempo y a una frecuencia más alta. Mientras tanto, los núcleos inactivos permanecerán en Estado-C (Reposo) por una duración mucho más larga, logrando un menor consumo de energía general.
Modos del Planificador
Sección titulada «Modos del Planificador»Videojuegos y Baja Latencia
Sección titulada «Videojuegos y Baja Latencia»- Opciones de línea de comandos:
--performance - Descripción: Maximiza el rendimiento utilizando todos los núcleos disponibles, priorizando los núcleos físicos.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
--powersave - Descripción: Minimiza el consumo de energía mientras mantiene un rendimiento razonable. Prioriza los núcleos e hilos eficientes sobre los núcleos físicos.
Desarrollado por: David Vernet (Byte-Lab GitHub)
- ¿Listo para producción?
- Sí. Si se ajusta correctamente.
Rusty ofrece una amplia gama de características que mejoran sus capacidades, proporcionando una mayor flexibilidad para diversos casos de uso. Una de estas características es la capacidad de ajuste, que te permite personalizar Rusty para que se adapte a tus preferencias y requisitos específicos.
- Casos de uso:
- Videojuegos
- Cargas de trabajo sensibles a la latencia
- Uso de escritorio
- Producción multimedia/audio
- Gran interactividad bajo cargas de trabajo intensivas
- Ahorro de energía
- ¿Listo para producción?
- Sí. Si se ajusta correctamente para tu carga de trabajo y hardware específicos.
Desarrollado por: Daniel Hodges (hodgesds GitHub)
Un planificador de propósito general que se centra en el balanceo de carga “pick two” (elegir dos) entre cachés LLC. Mantiene una alta localidad de caché y conservación del trabajo mientras proporciona una latencia razonable.
- Casos de uso:
- Servidor
- Entornos de escritorio
- Videojuegos (con algo de ajuste manual)
Modos del Planificador
Sección titulada «Modos del Planificador»Videojuegos
Sección titulada «Videojuegos»- Opciones de línea de comandos:
--task-slice true -f --sched-mode performance - Descripción: Mejora la consistencia en el rendimiento de los videojuegos y aumenta la preferencia por planificar en núcleos de mayor rendimiento.
Baja Latencia
Sección titulada «Baja Latencia»- Opciones de línea de comandos:
-y -f --task-slice true - Descripción: Reduce la latencia haciendo que las tareas interactivas se adhieran más a la CPU a la que fueron asignadas y aumentando la estabilidad en la porción de tiempo.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
--sched-mode efficiency - Descripción: Mejora la eficiencia energética al priorizar los núcleos de bajo consumo.
Servidor
Sección titulada «Servidor»- Opciones de línea de comandos:
--keep-running - Descripción: Mejora las cargas de trabajo del servidor al permitir que las tareas se ejecuten más allá de su porción de tiempo si la CPU está inactiva.
Desarrollado por: Andrea Righi (arighi Github)
- ¿Listo para producción?
- Este planificador todavía es experimental y no se recomienda para uso en producción.
scx_tickless es un planificador orientado a servidores, diseñado para computación en la nube, virtualización y cargas de trabajo de computación de alto rendimiento.
El planificador funciona enrutando todos los eventos de planificación a través de un grupo de CPUs primarias asignadas para manejar estos eventos. Esto permite deshabilitar el “tick” del planificador en otras CPUs, reduciendo el ruido del sistema operativo.
- Casos de uso:
- Computación en la nube
- Virtualización
- Cargas de trabajo de computación de alto rendimiento
- Servidor
Modos del Planificador
Sección titulada «Modos del Planificador»Videojuegos
Sección titulada «Videojuegos»- Opciones de línea de comandos:
-f 5000 -s 5000 - Descripción: Aumenta el rendimiento en videojuegos al incrementar la frecuencia con la que el planificador detecta la contención de la CPU y activa cambios de contexto con una porción de tiempo más corta.
Ahorro de Energía
Sección titulada «Ahorro de Energía»- Opciones de línea de comandos:
-f 50 - Descripción: Mejora la eficiencia energética al reducir las comprobaciones de contención.
Baja Latencia
Sección titulada «Baja Latencia»- Opciones de línea de comandos:
-f 5000 -s 1000 - Descripción: Similar al perfil de videojuegos pero con una porción de tiempo aún más reducida.
Servidor
Sección titulada «Servidor»- Opciones de línea de comandos:
-f 100 - Descripción: Reduce la frecuencia con la que el planificador comprueba la contención de la CPU para mejorar el rendimiento (throughput) a costa de la capacidad de respuesta.
Pruebas de configuración y rendimiento
Sección titulada «Pruebas de configuración y rendimiento»Piloto automático y energía automática de LAVD
Sección titulada «Piloto automático y energía automática de LAVD»Citas de Changwoo Min:
-
En modo de piloto automático, el planificador ajusta su modo de energía
Powersave, Balanced, o Performancesegún la carga del sistema, específicamente la utilización de la CPU. -
Energía automática: Decide automáticamente el modo de energía del planificador basándose en el perfil de energía del sistema, también conocido como EPP (Energy Performance Preference).
# La energía automática se puede activar con la siguiente bandera:--autopower# ej:scx_lavd --autopowerananicy-cpp y sched-ext
Sección titulada «ananicy-cpp y sched-ext»Para desactivar/detener ananicy-cpp, ejecuta el siguiente comando:
systemctl disable --now ananicy-cppCambio de perfiles de energía de scx_loader
Sección titulada «Cambio de perfiles de energía de scx_loader»Implementado en el paquete power-profiles-daemon proporcionado por CachyOS, que incluye un parche personalizado para admitir el cambio de perfiles de energía de scx_loader.
- Si
scx_loaderse está ejecutando, al usar el modo game-performance, cambiará automáticamente el planificador activo al perfilGamingcuando se inicie un juego y volverá al perfil predeterminado cuando el juego se cierre. - Al cambiar entre perfiles de energía, por ejemplo, en KDE Plasma o GNOME usando el selector de perfiles de energía,
scx_loadercambiará automáticamente al perfil de planificador correspondiente:
| Power Profile | Scheduler Profile |
|---|---|
| Power Saver | Power Save |
| Balanced | Auto |
| Performance | Gaming |
Realizar benchmarks y comparar planificadores con cachyos-benchmarker
Sección titulada «Realizar benchmarks y comparar planificadores con cachyos-benchmarker»La herramienta cachyos-benchmarker proporciona una manera fácil de evaluar y comparar el rendimiento de diferentes planificadores de CPU.
Ejecuta un conjunto completo de benchmarks para medir el rendimiento de la CPU, la memoria y el sistema en general bajo diversas cargas de trabajo.
Se incluyen los siguientes benchmarks:
| Prueba | Mide | Herramienta |
|---|---|---|
| stress-ng cpu-cache-mem | Rendimiento de CPU, caché y memoria | stress-ng |
| Compilación de FFmpeg | Rendimiento de compilación en paralelo | make |
| Codificación x265 | Rendimiento de codificación de video | x265 |
| Hashing argon2 | Hashing de contraseñas multihilo | argon2 |
| perf sched msg | Cambio de contexto y rendimiento de IPC | perf |
| perf memcpy | Rendimiento de memoria memcpy() |
perf |
| Cálculo de primos | Aritmética de enteros y paralelismo | primesieve |
| NAMD | Dinámica molecular (carga de trabajo científica) | namd3 |
| Renderizado en Blender | Renderizado 3D solo con CPU | blender |
| Compresión xz | Rendimiento de compresión | xz |
| Compilación defconfig del kernel | Rendimiento de compilación del kernel | make |
| y-cruncher | Precisión matemática y estrés de memoria | y-cruncher |
cachyos-benchmarker se puede utilizar para varios propósitos, incluyendo:
- Probar la estabilidad del planificador
Ejecuta el conjunto completo de benchmarks para detectar bloqueos, caídas o regresiones introducidas por cambios en el planificador.
Si estás utilizando
scx_loader, puedes recopilar registros en caso de un bloqueo o caída con:Esto creará un archivo llamadoTerminal window journalctl --unit scx_loader.service --boot 0 > crash.logcrash.logen tu directorio actual. - Comparar el rendimiento del planificador
- Evaluar las diferencias de rendimiento entre planificadores. Por ejemplo,
BPFLAND vs LAVD
- Evaluar las diferencias de rendimiento entre planificadores. Por ejemplo,
- Medir el efecto de las actualizaciones del kernel o del planificador
- Comparar ejecuciones antes y después de aplicar parches o cambios de versión para verificar regresiones o mejoras de rendimiento.
- Probar ajustes de configuración
- Evaluar el impacto de cambios como la configuración del gobernador de la CPU, la activación/desactivación de SMT o las banderas modificadas del planificador.
Requisitos
Sección titulada «Requisitos»- 4 GB de RAM o más
- Al menos 8 GB de espacio de almacenamiento libre
- Tiempo y paciencia - el benchmark completo puede tardar más de una hora en sistemas más lentos
Instalación
Sección titulada «Instalación»Para instalar cachyos-benchmarker, ejecuta el siguiente comando:
sudo pacman -S cachyos-benchmarkerEjecutando el benchmark
Sección titulada «Ejecutando el benchmark»- Ejecuta
cachyos-benchmarker:Terminal window cachyos-benchmarker ~/cachyos-benchmarker/# Puedes reemplazar ~/cachyos-benchmarker/ con cualquier directorio en el que desees guardar los registros. - Espera a que finalicen los pasos de preparación.
- Sigue las indicaciones:
Do you want to drop page cache now? Root privileges needed! (y/N) y(¿Deseas limpiar la caché de página ahora? ¡Se necesitan privilegios de superusuario! (s/N) s)Please enter a name for this run, or leave empty for default:(Por favor, introduce un nombre para esta ejecución, o déjalo en blanco para el valor por defecto:)
- Espera a que terminen las pruebas.
- Una vez finalizado, sucederá lo siguiente:
- Creación de un archivo de registro con un nombre como
benchie_<nombre>_<FECHA>.logque contiene información detallada sobre la ejecución del benchmark.- Ejemplo:
benchie_p2dq_2025-09-29-2115.log - El script
benchmark_scraper.pyse ejecutará automáticamente para generar un informe de resumen en formato HTML. - ¿Qué hace el script?:
- Lee todos los archivos
benchie_*.logen el directorio especificado. - Extrae los nombres, tiempos y puntuaciones de los benchmarks.
- Los ordena o agrega.
- Imprime un resumen limpio de los resultados en tu terminal y crea un archivo HTML que se puede abrir en un navegador.
Ejemplo de salida en la terminal:
stress-ng cpu-cache-mem: 15.26y-cruncher pi 1b: 31.23perf sched msg fork thread: 8.892perf memcpy: 13.53namd 92K atoms: 53.54calculating prime numbers: 11.126argon2 hashing: 6.62ffmpeg compilation: 53.38xz compression: 61.13kernel defconfig: 130.73blender render: 96.29x265 encoding: 24.99Total time (s): 506.72Total score: 70.71Name: p2dqDate: 2025-09-29-2115System: Kernel: 6.17.0-1.1-cachyos-p2dq arch: x86_64 bits: 64Desktop: KDE Plasma v: 6.4.5 Distro: CachyOSMemory: System RAM: total: 32 GiB available: 30.61 GiB used: 7.54 GiB (24.6%)Device-1: Channel-A DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-2: Channel-B DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-3: Channel-C DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sDevice-4: Channel-D DIMM 0 type: LPDDR5 size: 8 GiB speed: 7500 MT/sCPU: Info: 8-core model: AMD Ryzen 7 8845HS w/ Radeon 780M Graphics bits: 64 type: MT MCP cache: L2: 8 MiBSpeed (MHz): avg: 3366 min/max: 419/5138 cores: 1: 3366 2: 3366 3: 3366 4: 3366 5: 3366 6: 3366 7: 3366 8: 3366 9: 3366 10: 3366 11: 3366 12: 3366 13: 3366 14: 3366 15: 3366 16: 3366SCX Scheduler: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuSCX Version: p2dq_1.0.21_gf90c2aa1_dirty_x86_64_unknown_linux_gnuVersion : 0.5.1-1Ejemplo en HTML del resultado de una prueba comparando dos ramas diferentes del mismo planificador:
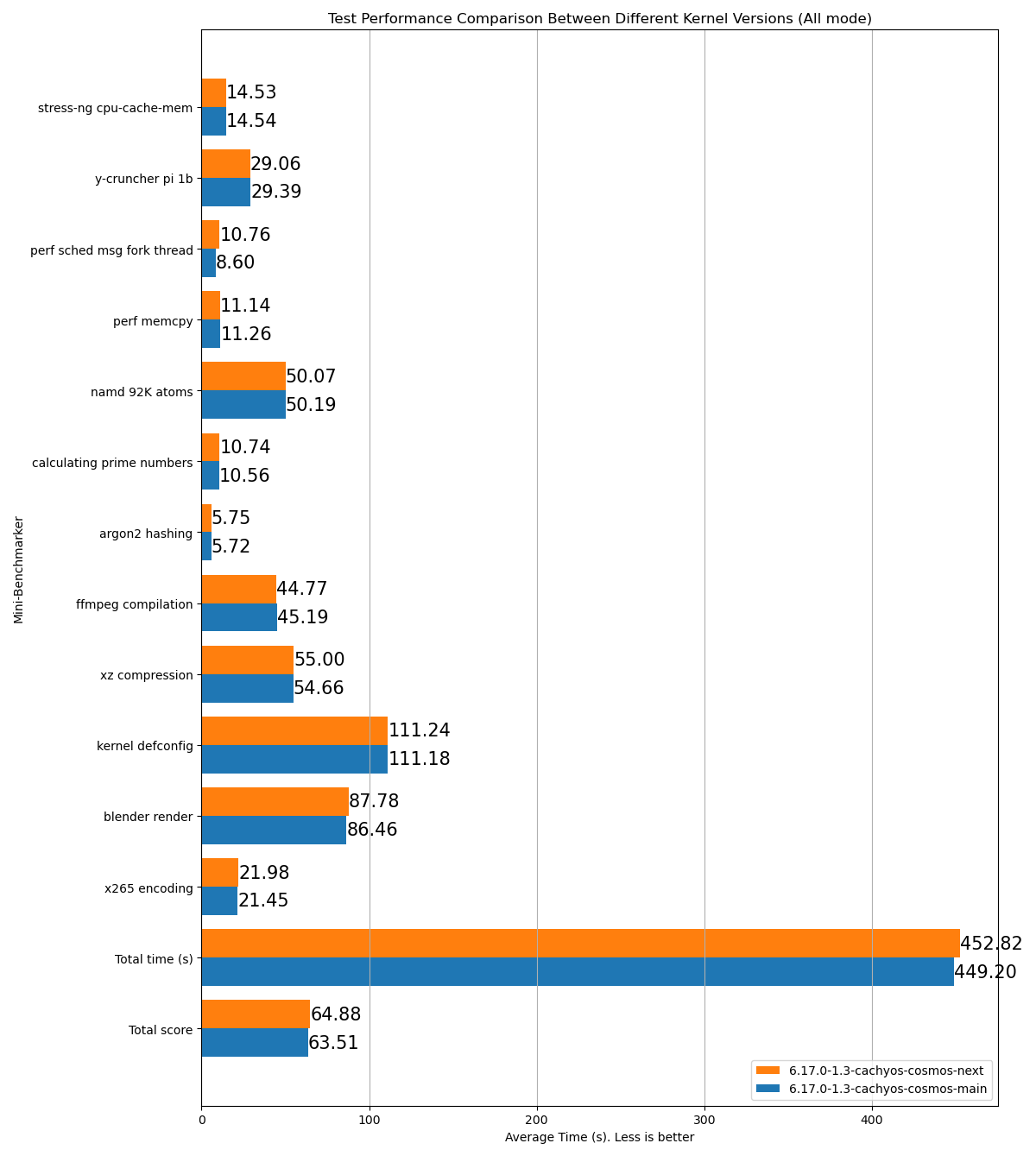
- Lee todos los archivos
- Ejemplo:
- Creación de un archivo de registro con un nombre como
- Para comparar dos o más ejecuciones, coloca los archivos
.logen el mismo directorio antes de ejecutarbenchmark_scraper.py. La herramienta los detectará y comparará automáticamente en el informe HTML.
Pruebas de latencia del planificador con schbench
Sección titulada «Pruebas de latencia del planificador con schbench»schbench es un benchmark de planificadores diseñado para medir la latencia del planificador bajo una carga de trabajo simulada de tipo servidor. Genera un número configurable de hilos “trabajadores” y “mensajeros”, donde los mensajeros despiertan repetidamente a los trabajadores. Al medir la distribución de la latencia desde el despertar hasta la ejecución de estos hilos trabajadores, proporciona información crucial sobre la capacidad de un kernel para manejar despertares de hilos, equilibrio y contención de CPU, especialmente bajo carga.
Casos de uso
Sección titulada «Casos de uso»Puedes usar schbench para:
- Evaluar la latencia del planificador: Identificar cuán rápido se planifican los hilos después de ser despertados.
- Comparar el rendimiento de despertar entre planificadores: Detectar mejoras o regresiones en el cambio de contexto y la latencia de despertar.
- Probar el efecto de parches en el kernel o el planificador: Evaluar si los ajustes o actualizaciones afectan la equidad y la capacidad de respuesta de la planificación.
Instalación
Sección titulada «Instalación»schbench está disponible en los repositorios de CachyOS:
sudo pacman -S schbenchEjecutando el benchmark
Sección titulada «Ejecutando el benchmark»Una forma sencilla de ejecutar schbench para una prueba de latencia general es:
schbench -m 2 -t 8 -r 60Este ejemplo ejecuta:
- 2 hilos mensajeros (
-m 2) - 8 hilos trabajadores por cada hilo mensajero (
-t 8) - durante 60 segundos de tiempo de ejecución total (
-r 60)
Puedes ajustar estos valores dependiendo de la cantidad de núcleos de tu CPU y el nivel de carga deseado.
Aquí tienes una tabla que explica algunas de las opciones clave:
| Opción | Descripción |
|---|---|
-C, --calibrate |
Ejecuta la calibración e informa el tiempo (sin benchmark). |
-L, --no-locking |
Desactiva los spinlocks durante el trabajo de la CPU (por defecto: bloqueo activado). |
-m, --message-threads <n> |
Número de hilos mensajeros (por defecto: 1). |
-t, --threads <n> |
Hilos trabajadores por hilo mensajero (por defecto: número de CPUs). |
-r, --runtime <sec> |
Duración del benchmark (por defecto: 30). |
-F, --cache_footprint <KB> |
Tamaño de la huella de caché (por defecto: 256). |
-n, --operations <count> |
Número de operaciones de “tiempo de reflexión” a realizar (por defecto: 5). |
-A, --auto-rps |
Aumenta automáticamente el RPS hasta alcanzar el objetivo de utilización de la CPU. |
-R, --rps <count> |
Modo de solicitudes por segundo. |
-p, --pipe <bytes> |
Simula una prueba de transferencia por tubería. |
-w, --warmuptime <sec> |
Duración del calentamiento antes de recopilar estadísticas (por defecto: 0). |
-i, --intervaltime <sec> |
Intervalo para imprimir latencias (por defecto: 10). |
-z, --zerotime <sec> |
Intervalo para poner a cero las estadísticas de latencia (por defecto: nunca). |
Entendiendo la salida
Sección titulada «Entendiendo la salida»Después de cada ejecución, schbench imprime los percentiles de latencia de esta forma:
Ejemplo de salida
Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2394 total samples) 50.0th: 49216 (726 samples) 90.0th: 69760 (954 samples)* 99.0th: 166656 (212 samples) 99.9th: 273920 (21 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248current rps: 230.99Wakeup Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 60 (648 samples) 90.0th: 2034 (968 samples)* 99.0th: 4104 (211 samples) 99.9th: 10128 (22 samples) min=1, max=10308Request Latencies percentiles (usec) runtime 10 (s) (2406 total samples) 50.0th: 49216 (729 samples) 90.0th: 69760 (956 samples)* 99.0th: 165632 (212 samples) 99.9th: 273920 (22 samples) min=11770, max=334247RPS percentiles (requests) runtime 10 (s) (11 total samples) 20.0th: 234 (3 samples)* 50.0th: 238 (3 samples) 90.0th: 241 (4 samples) min=230, max=248average rps: 240.60Cómo interpretar los resultados
Sección titulada «Cómo interpretar los resultados»- Latencias de despertar (Wakeup Latencies):
- Mide cuán rápido se despiertan los hilos después de ser señalados.
- Valores más bajos aquí (especialmente el percentil 99) significan que el planificador es más responsivo.
- Mide cuán rápido se despiertan los hilos después de ser señalados.
- Latencias de solicitud (Request Latencies):
- Representa el tiempo que se tarda en completar solicitudes entre hilos.
- Una latencia más baja indica una mejor comunicación entre hilos y eficiencia en la planificación.
- Representa el tiempo que se tarda en completar solicitudes entre hilos.
- RPS (Solicitudes por segundo):
- Muestra el rendimiento sostenido:
- Un RPS promedio más alto indica que el planificador puede manejar más trabajo por segundo bajo la configuración dada.
- Muestra el rendimiento sostenido:
En conclusión:
- Un buen planificador mostrará bajas latencias de despertar y de solicitud con un RPS consistente.
- Un planificador menos eficiente puede exhibir picos de alta latencia o valores de RPS inestables a lo largo del tiempo.
Recomendaciones para hacer benchmarks en juegos
Sección titulada «Recomendaciones para hacer benchmarks en juegos»Si tu deseo es hacer benchmarks en juegos para comparar el rendimiento de diferentes planificadores, aquí tienes algunos consejos para obtener los resultados más precisos:
- Usa benchmarks integrados: Muchos juegos modernos vienen con herramientas de benchmarking integradas. Estas están diseñadas para proporcionar resultados consistentes al ejecutar la misma secuencia de eventos cada vez.
- Echa un vistazo a este sitio web para ver una lista de juegos que incluyen benchmarks integrados.
- Configuración consistente: Asegúrate de que la configuración del juego (resolución, calidad de gráficos, etc.) sea la misma para cada prueba.
- Cierra aplicaciones en segundo plano: Otras aplicaciones que se ejecutan en segundo plano pueden afectar el rendimiento. Cierra los programas innecesarios para minimizar su impacto.
- Si no estás utilizando un benchmark integrado, intenta realizar las mismas acciones en el juego en cada prueba. Esto podría incluir seguir el mismo camino, participar en escenarios de combate similares o realizar las mismas tareas.
- Incluso no apuntar al mismo lugar puede llevar a resultados de rendimiento diferentes.
- Múltiples ejecuciones: Realiza varias ejecuciones del benchmark y saca el promedio para tener en cuenta la variabilidad.
- Usa herramientas de monitoreo de rendimiento: Herramientas como MangoHud o GOverlay pueden proporcionar métricas de rendimiento en tiempo real como FPS, tiempos de fotograma y uso de CPU/GPU.
- Aprovecha los atajos de teclado o macros:
- Un ejemplo es crear una combinación de teclas con la que puedas cambiar entre diferentes planificadores o sus modos sobre la marcha mientras estás en el juego.
- Esto se puede hacer usando una herramienta como scxctl o creando scripts personalizados que cambien el planificador activo y su modo.
- Un ejemplo es crear una combinación de teclas con la que puedas cambiar entre diferentes planificadores o sus modos sobre la marcha mientras estás en el juego.
Subir y compartir tus benchmarks
Sección titulada «Subir y compartir tus benchmarks»Este sitio web contiene una lista de benchmarks realizados por la comunidad utilizando diferentes planificadores o probando diversas configuraciones.
Para subir tus propios benchmarks, tendrás que vincular tu cuenta de Discord al sitio web y luego podrás enviar tus propios benchmarks.
Luego haz clic en el botón New benchmark y completa la información requerida.
- Puedes subir múltiples resultados para el mismo juego usando diferentes planificadores o configuraciones.
- Acepta registros tanto de MangoHud como de Afterburner.
- Permite buscar por título o descripción.
Transición de scx.service a scx_loader: Una Guía Completa
Sección titulada «Transición de scx.service a scx_loader: Una Guía Completa»Primero, comencemos con una comparación detallada entre la estructura de archivos de scx.service y la estructura del archivo de configuración de scx_loader.
Si anteriormente tenías LAVD funcionando con el antiguo scx.service como en este ejemplo a continuación:
# Lista de scx_schedulers: scx_bpfland scx_central scx_flash scx_lavd scx_layered scx_nest scx_qmap scx_rlfifo scx_rustland scx_rusty scx_simple scx_userlandSCX_SCHEDULER=scx_lavd
# Establecer flags personalizados para el planificadorSCX_FLAGS='--performance'Entonces el equivalente en el archivo de configuración de scx_loader se verá así:
default_sched = "scx_lavd"default_mode = "Auto"
[scheds.scx_lavd]auto_mode = ["--performance"]Para más información sobre cómo configurar el archivo scx_loader
Siga la guía a continuación para una transición sencilla del servicio systemd scx a la nueva utilidad scx_loader.
-
Deshabilitando scx.service en favor de scx_loader.service systemctl disable --now scx.service && systemctl enable --now scx_loader.service -
Creando el archivo de configuración para scx_loader y añadiendo la estructura por defecto # El editor Micro va a crear un nuevo archivo.sudo micro /etc/scx_loader.toml# Añada las siguientes líneas:default_sched = "scx_bpfland" # Edite esta línea con el planificador que desea que scx_loader inicie en el arranquedefault_mode = "Auto" # Valores posibles: "Auto", "Gaming", "LowLatency", "PowerSave".# Pulse CTRL + S para guardar los cambios y CTRL + Q para salir de Micro. -
Reiniciando el scx_loader systemctl restart scx_loader.service- Ha terminado, el scx_loader ahora cargará e iniciará el planificador deseado.
Depuración en el scx_loader
Sección titulada «Depuración en el scx_loader»-
Comprobando el estado del servicio systemctl status scx_loader.service -
Viendo todas las entradas de registro del servicio journalctl -u scx_loader.service -
Viendo solo los registros de la sesión actual. journalctl -u scx_loader.service -b 0
Para obtener un registro más detallado, siga estos pasos.
-
Editar el archivo del servicio sudo systemctl edit scx_loader.service -
Añada la siguiente línea bajo la sección [Service] Environment=RUST_LOG=trace -
Reinicie el servicio sudo systemctl restart scx_loader.service - Revise los registros de nuevo para obtener información de depuración más detallada.
Preguntas Frecuentes
Sección titulada «Preguntas Frecuentes»¿Por qué el planificador X rinde peor que el otro?
Sección titulada «¿Por qué el planificador X rinde peor que el otro?»- Hay muchas variables a considerar al compararlos. Por ejemplo, ¿cómo miden el peso de una tarea? ¿Priorizan las tareas interactivas sobre las no interactivas? En última instancia, depende de sus decisiones de diseño.
¿Por qué todo el mundo sigue diciendo que este planificador X es el mejor para el caso X pero no me rinde tan bien?
Sección titulada «¿Por qué todo el mundo sigue diciendo que este planificador X es el mejor para el caso X pero no me rinde tan bien?»- Al igual que en la respuesta anterior, la elección de la CPU y su diseño, como la disposición de los núcleos, cómo comparten la caché entre los núcleos y otros factores relacionados, pueden hacer que el planificador funcione de manera menos eficiente.
- Por eso tener opciones es uno de los puntos fuertes del framework sched-ext, así que no tenga miedo de probar uno y ver cuál funciona mejor para su caso de uso.
Ejemplos: estabilidad de fps, rendimiento máximo, capacidad de respuesta bajo cargas de trabajo intensivas, etc.
Los casos de uso de estos planificadores son bastante similares… ¿por qué es eso?
Sección titulada «Los casos de uso de estos planificadores son bastante similares… ¿por qué es eso?»Principalmente porque son planificadores multipropósito, lo que significa que pueden adaptarse a una variedad de cargas de trabajo, aunque puede que no destaquen en todas las áreas.
- Para determinar qué planificador se adapta mejor a usted, no hay mejor consejo que probarlo por sí mismo.
¿Por qué me falta un planificador que algunos usuarios mencionan o prueban en el servidor de Discord de CachyOS?
Sección titulada «¿Por qué me falta un planificador que algunos usuarios mencionan o prueban en el servidor de Discord de CachyOS?»Asegúrese de que está utilizando la versión más reciente del paquete scx-scheds, llamada scx-scheds-git
- Una de las razones será que este planificador es muy nuevo y actualmente está siendo probado por los usuarios, por lo tanto, aún no se ha añadido al paquete
scx-scheds-git.
¿Por qué el planificador se ha colgado de repente? ¿Es inestable?
Sección titulada «¿Por qué el planificador se ha colgado de repente? ¿Es inestable?»- Podría haber algunas razones por las que esto ocurrió:
- Una de las razones más comunes es que estaba usando ananicy-cpp junto con el planificador. Por eso añadimos esta advertencia
- Otra razón podría ser que la carga de trabajo que estaba ejecutando excedió los límites y la capacidad del planificador, provocando que se detuviera.
- Ejemplo de una carga de trabajo irrazonable:
hackbench
- Ejemplo de una carga de trabajo irrazonable:
- O la razón más obvia, ha encontrado un error en el planificador. Si es así, por favor repórtelo como un “issue” en su GitHub o hágaselo saber
en el canal de Discord de CachyOS
sched-ext
He utilizado previamente el scx_loader en la GUI del Gestor de Kernel. ¿Aun así necesito seguir los pasos de transición?
Sección titulada «He utilizado previamente el scx_loader en la GUI del Gestor de Kernel. ¿Aun así necesito seguir los pasos de transición?»- En este caso particular, no, no es necesario porque el Gestor de Kernel ya se encarga del proceso de transición.
- A menos que haya añadido previamente flags personalizados en
/etc/default/scxy todavía quiera usarlos.
- A menos que haya añadido previamente flags personalizados en
Aprenda Más
Sección titulada «Aprenda Más»- Lista de reproducción de YT de Sched_ext
- LWN: The extensible scheduler class (Febrero, 2023)
- Blog de arighi: Implement your own kernel CPU scheduler in Ubuntu with sched_ext (Julio, 2023)
- Charla de David Vernet: Kernel Recipes 2023 - sched_ext: pluggable scheduling in the Linux kernel (Septiembre, 2023)
- Blog de Changwoo: sched_ext: a BPF-extensible scheduler class (Part 1) (Diciembre, 2023)
- Blog de arighi: Getting started with sched_ext development (Abril, 2024)
- Blog de Changwoo: sched_ext: scheduler architecture and interfaces (Part 2) (Junio, 2024)
- Canal de YT de arighi: scx_bpfland Linux scheduler demo: topology awareness (Agosto, 2024)
- Charla de David Vernet: Kernel Recipes 2024 - Scheduling with superpowers: Using sched_ext to get big perf gains (Septiembre, 2024)